
티스토리 뷰
[Java] HashMap의 내부 동작 깊게 들여다보기(HashMap Internals with Separate Chaining & Treeify, Capacity & LoadFactor 등)
망나니개발자 2025. 5. 20. 10:00
1. HashMap의 내부 동작 깊게 들여다보기
(HashMap Internals with Separate Chaining & Treeify, Capacity & LoadFactor 등)
[ HashMap의 해시 버킷 Separate Chaining과 Treeify ]
HahsMap은 내부적으로 노드 배열로 저장되는데, 이때 각 노드 배열의 요소를 해시 버킷이라고 한다. HashMap을 생성할 때 별도의 해시 버킷 배열의 capacity를 지정하지 않는다면 기본값 16으로 할당된다. 이러한 부분을 그림으로 표현하면 다음과 같다.
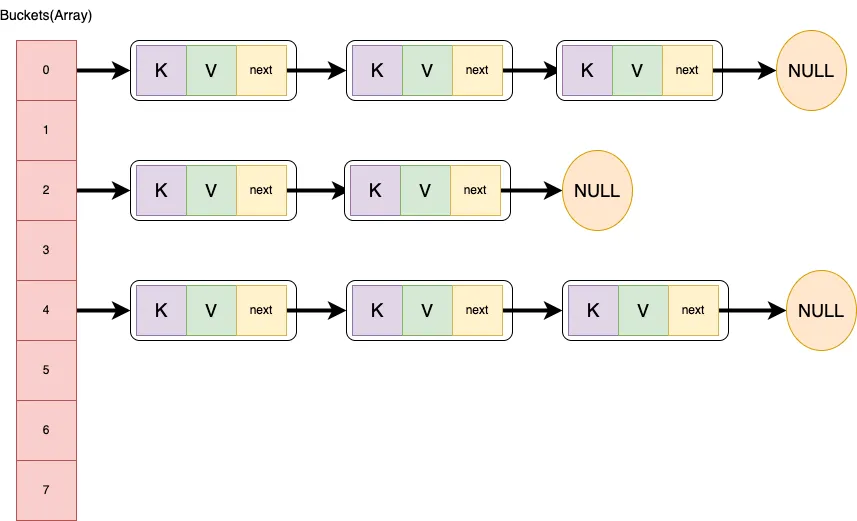
HashMap은 데이터를 저장할 키에 대한 해시코드(hashcode)를 계산하고 해당 값을 배열의 크기로 나누어, 데이터를 저장할 해시 버킷의 인덱스를 구하고, 해당 해시 버킷에 데이터를 저장한다.
예를 들어 다음과 같이 데이터를 저장하는 로직이 존재한다고 하자.
Map<String, String> map = new HashMap<>();
map.put("apple", "사과");
map.put("banana", "바나나");
HashMap은 내부적으로 "apple"의 해시 코드와 HahsMap의 크기를 바탕으로 버킷 인덱스를 구하고, 해당 위치에 데이터를 저장한다. 그렇다면 이때 "banana" 역시 버킷 인덱스가 15라면 어떻게 될까? 위의 그림에서 보이듯이 해시 버킷 내부에서 리스트 형태로 관리된다. 이를 분리 연결법(Separate Chaining)이라고 한다.
table[15] -> Node("apple", "사과") -> Node("banana", "바나나")
하지만 동일한 해시 버킷을 사용하는 원소가 많아지면 리스트가 길어져 시간 복잡도가 O(N)과 같이 증가하게 된다. 따라서 자바8부터는 이러한 문제를 해결하기 위해, 하나의 버킷에 들어간 노드 수가 8개가 초과할 경우 자료 구조를 트리(레드 블랙 트리)로의 변경을 시도한다. 아래의 코드에서 TREEIFY_THRESHOLD는 8에 해당한다.

여기서 트리화를 “시도한다”고 표현한 이유는 트리로 변경하기 이전에 선행하는 작업이 있기 때문이다. HashMap은 내부적으로 트리로 변경하기 이전에, HashMap의 전체 크기를 검사하여 64보다 작은 경우 먼저 해시 버킷 배열을 확장(resize)한다. 왜냐하면 해시 버킷 배열 크기 자체가 작은 경우에는 충돌이 자주 발생할 수밖에 없기 때문이다.
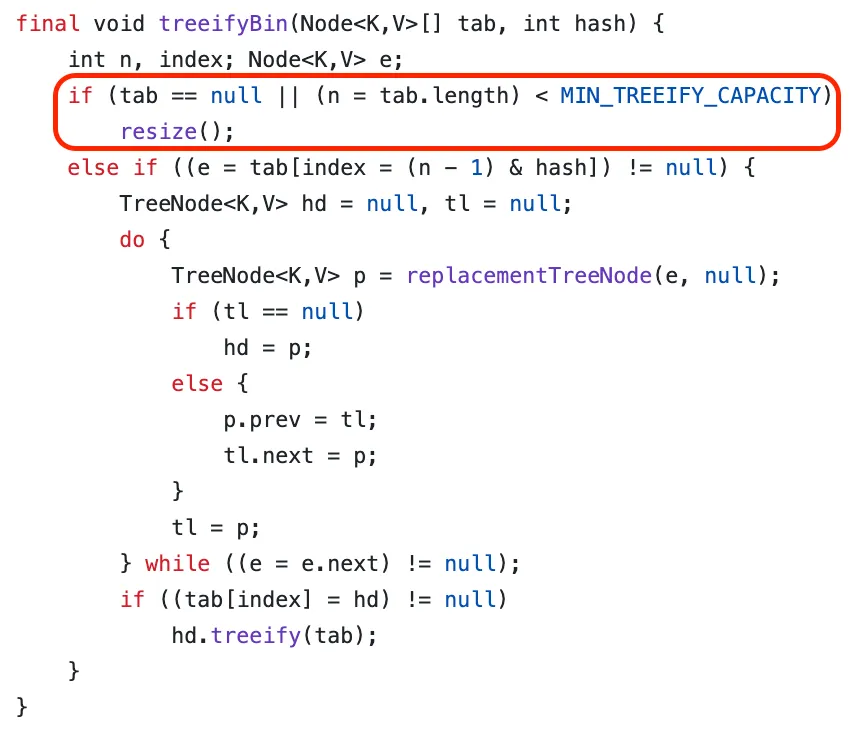
자바는 이러한 방식으로 HashMap 내부를 구현하여 최적화를 진행하고 있으며, 버킷 충돌이 자주 발생하는 경우에는 트리화를 통해 시간 복잡도를 O(log N)까지 낮출 수 있었다. 하지만 이때 트리의 정렬을 위해 키가 String, Number 클래스 같은 Comparable 타입이여만 트리로의 변환이 가능하다는 점은 주의할 필요가 있다.
[ HashMap의 크기와 확장 작업(capacity and resize) ]
앞서 설명하였듯 해시맵을 생성할 때 별도의 크기(capacity)를 지정하지 않는다면, 해시 버킷 배열의 크기가 기본값 16으로 할당된다. 그리고 하나의 버킷에 8개를 초과하여 충돌이 발생한 경우, 크키가 64보다 작다면 트리화 이전에 먼저 HashMap의 크기를 확장(resize)한다고 하였다.
그렇다면 이때 해시 버킷 배열의 크기는 어떻게 산정될까? 해시 버킷 배열의 크기는 현재의 크기의 다음 2의 제곱수로 선정된다. 아래의 로직에서 보이듯이 신규 크기(newCap)는 이전 크기(oldCap)의 2배로 할당되는 것을 볼 수 있다.
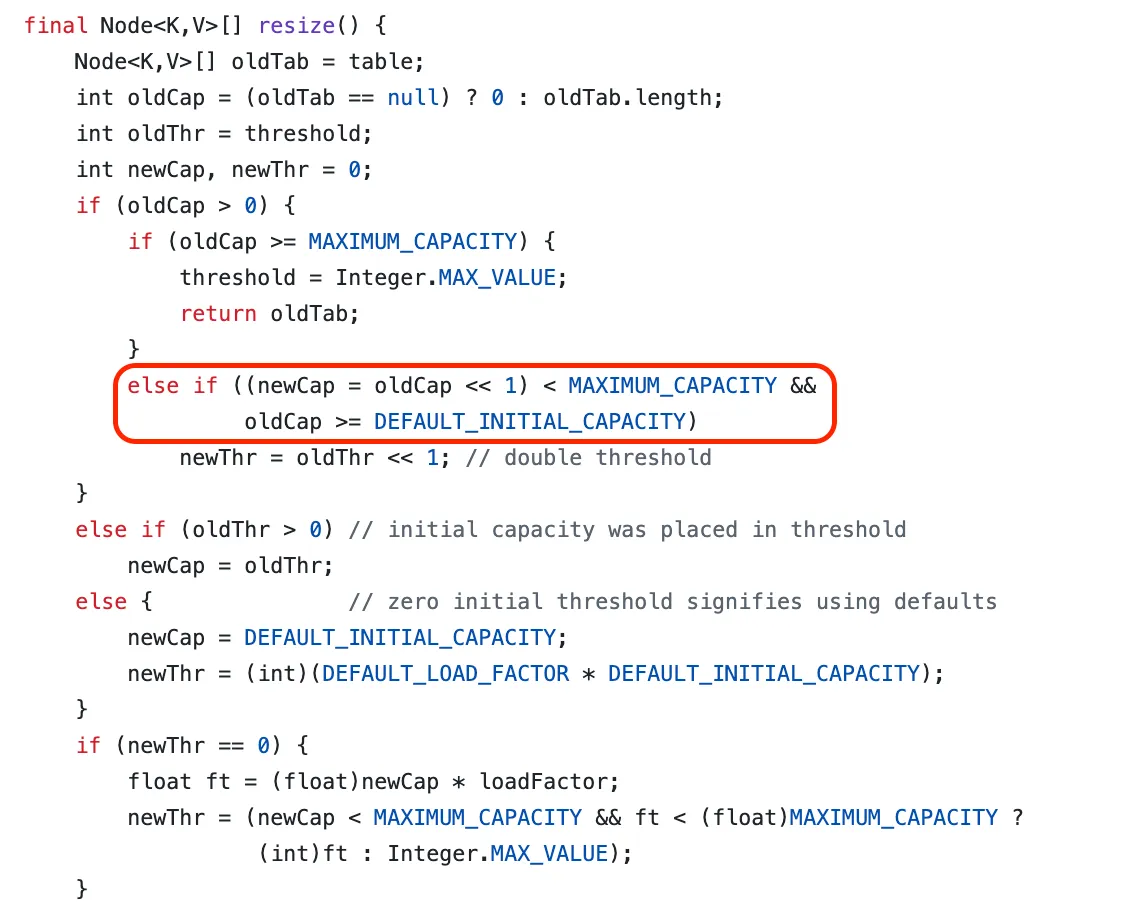
HashMap이 그 크기를 2의 제곱수(capacity = 2ⁿ)로 유지하는 데는 효율성과 성능 측면에서 분명한 이유가 있다. 먼저 mod 연산이 아닌 비트 연산을 통해 인덱스를 빠르게 구할 수 있다.
// Mod 연산은 느림
(X) index = hashCode % table.length;
// Bit 연산은 빠름
(O) index = (hash & (table.length - 1));
뿐만 아니라 비트 마스크를 통한 하위 비트만으로 인덱스를 결정하여 효율적으로 분산시킬 수도 있다.
예를 들어 배열의 크기가 16이면 length-1 = 15이고, 이를 hash된 값과 연산화여 하위 4비트만 사용하여 빠르고 균등하게 인덱스를 분산시킬 수 있는 것이다. 이는 2의 제곱수가 아니면 균등하게 분산되지 못하는 연산이다.
| 해시값 | 이진수 하위 4비트 | & 0b1111 결과 | 인덱스 |
| 0xA2F3 | 0b0011 | 3 | table[3] |
| 0x84B7 | 0b0111 | 7 | table[7] |
| 0x129C | 0b1100 | 12 | table[12] |
뿐만 아니라 리사이즈도 효율적으로 일어날 수 있는데, 위의 인덱스 연산을 통하면 새로운 인덱스는 항상 기존의 인덱스와 동일하거나 기존 인덱스에 기존 크기를 더한 값으로, 이는 비트를 한칸 늘린 것이다. 예를 들어 기존 크기 16에서 32로 확장한다면, 각 노드는 기존 위치 또는 기존 위치 + 16 둘 중 하나로 이동되는 선택지 밖에 없는 것이다. 이러한 구현 덕분에 리사이즈도 빠르고 효율적으로 일어나는 것이다. 이를 정리하면 다음과 같다.
- % 대신 & 비트 연산을 통한 빠른 인덱스 계산
- 하위 비트를 활용한 균등한 해시 분산
- 간단한 리사이즈 위치 계산을 통한 빠르고 효율적인 재구성
[ HashMap의 해시 버킷 크기 확장 조건 ]
그렇다면 해시 버킷 배열의 크기가 확장(resize)되는 조건은 무엇일까? 배열의 크기가 꽉 찼을 경우가 아닌, 꽉차기 이전에 특정한 임계값(threshold)를 넘었을 경우 확장되도록 되어 있다. 예를 들어 다음과 같이 1~1000의 숫자를 가진 리스트를 해시맵에 넣는다고 하자.
class HashMapTest {
@Test
void printThresholdWithSize() throws Exception {
List<Integer> integers = IntStream.rangeClosed(1, 1000).boxed().toList();
HashMap<Integer, String> map = new HashMap<>(integers.size());
printThresholdWithSize(0, map);
for (Integer integer : integers) {
map.put(integer, integer.toString());
if (integer == 767 || integer == 768 || integer == 769 || integer == 770) {
printThresholdWithSize(integer, map);
}
}
}
private static void printThresholdWithSize(Integer integer, HashMap<Integer, String> map) throws Exception {
System.out.println("num = " + integer + ", threshold: " + getThreshold(map) + ", Table size: " + getTableSize(map));
}
private static int getTableSize(HashMap<Integer, String> map) throws NoSuchFieldException, IllegalAccessException {
Field tableField = map.getClass().getDeclaredField("table");
tableField.setAccessible(true);
Object[] table = (Object[]) tableField.get(map);
return table == null ? 0 : table.length;
}
private static int getThreshold(HashMap<Integer, String> map) throws NoSuchFieldException, IllegalAccessException {
Field thresholdField = map.getClass().getDeclaredField("threshold");
thresholdField.setAccessible(true);
return thresholdField.getInt(map);
}
}
위의 코드 출력 결과에서 중요한 부분만 추리면 다음과 같다.
num = 0, threshold: 1024, Table size: 0
num = 1, threshold: 768, Table size: 1024
num = 768, threshold: 768, Table size: 1024
num = 769, threshold: 1536, Table size: 2048
위의 실행을 통해 알 수 있는 것은, 해시맵 생성 시에 1000의 크기를 할당해 주었을 때 확장을 위한 threshold은 768이며, 해당 값 이상의 HashMap 해시 버킷 배열이 사용되었다면 확장이 일어난다는 점이다. 따라서 우리가 HashMap의 크기를 1000으로 고정 할당해주었더라도, 초기에는 1024 그리고 확장 시에는 2048의 크기를 갖는 HashMap이 생성 및 사용되는 것이다. 이러한 처리가 일어나는 이유는 HashMap 내부에서 사용하는 threshold와 loadFactor 변수에 있다.
HashMap은 3가지의 생성자를 지원하며, 이를 정리하면 다음과 같다.
- 기본 생성자: capacity는 16, loadFactor는 0.75로 할당함
- capacity 생성자: capacity는 입력받은 값, loadFactor는 0.75로 할당함
- capacity, loadFactory 생성자: capacity와 loadFactory 모두 입력받은 값으로 할당함

먼저 HashMap은 생성되는 시점에 threshold를 1차적으로 결정하는데, 2의 제곱수 중에서 capacity 보다 크거나 같은 값으로 설정된다. 위의 코드에서는 capacity를 1000으로 설정해주었기 때문에 1000보다 큰 2의 제곱수 중에서 가장 근접한 1024가 threshold로 설정된 것이다. 그 외에 흥미로운 부분은 TableSize가 0이라는 점인데, 이를 통해 해시 버킷 배열이 지연 초기화(Lazy Initialization)된다는 사실을 알 수 있다.
num = 0, threshold: 1024, Table size: 0
이후에 첫 번째 원소가 put 되면, 그때 버킷 배열이 생성 및 확장되면서 threshold와 table의 크기가 설정됨을 확인할 수 있다.
num = 1, threshold: 768, Table size: 1024
여기서 흥미로운 사실은 threshold가 할당되는 로직인데, threshold는 다음과 같은 공식으로 할당된다. 현재의 크기는 1024이고, 기본 loadFactor는 0.75이므로 두 수를 곱하여 768이 threshold로 설정된 것이다.
threshold = newCap * loadFactor
해당 로직은 resize 내부에서 찾아볼 수 있다.
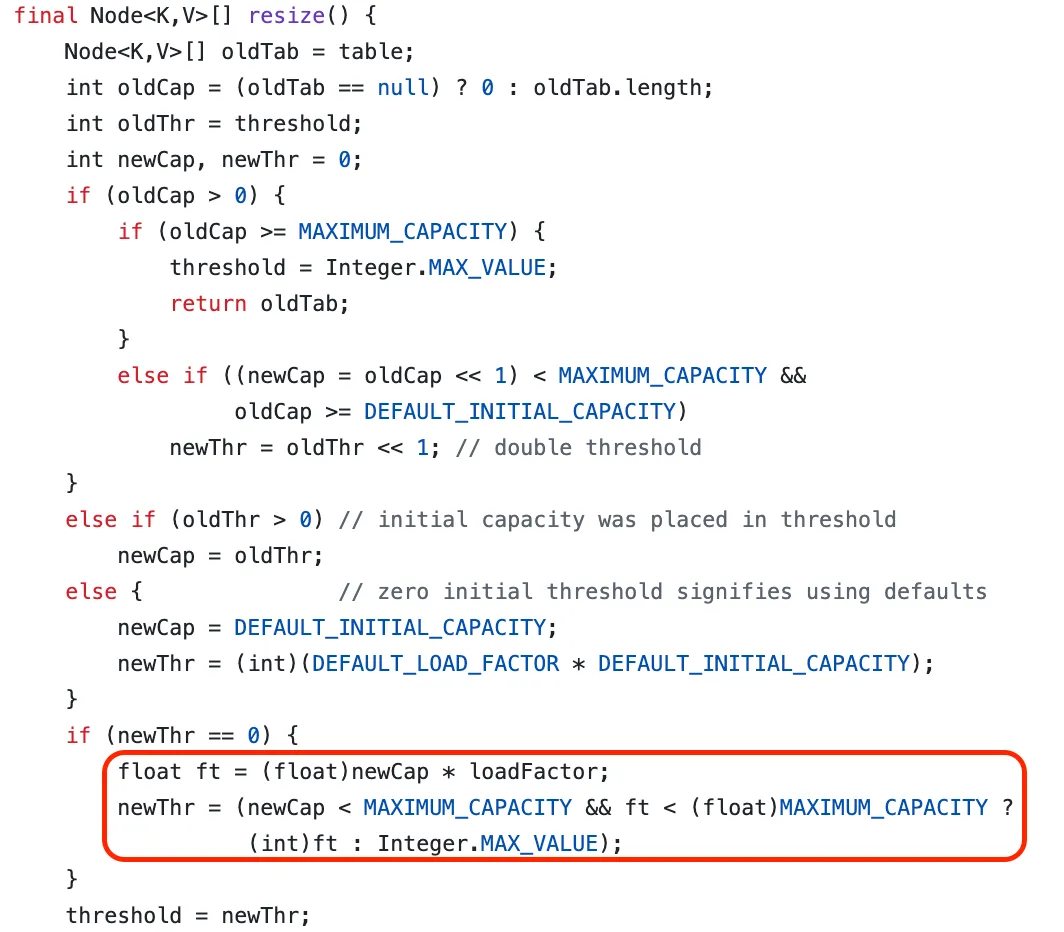
그 후에는 size가 threshold를 넘을 때마다 resize가 항상 일어나는 것이고, 따라서 769가 put 되었을 때 resize가 일어나면서 값이 재구성되었던 것이다.
num = 768, threshold: 768, Table size: 1024
num = 769, threshold: 1536, Table size: 2048
따라서 고정된 값을 추가하는 경우에 불필요한 HashMap의 확장을 막기 위해서는 다음과 같이 생성 시에 loadFactor를 1.0으로 고정해주는 방법이 있다. 그러면 다음과 같이 threshold가 capacity와 동일하게 확장되며 불필요한 연산이 줄어든다.
num = 0, threshold: 1024, Table size: 0
num = 1, threshold: 1024, Table size: 1024
num = 768, threshold: 1024, Table size: 1024
num = 769, threshold: 1024, Table size: 1024
이 외에도 JDK 19부터는 각각의 컬렉션에 대해 정적 팩토리 메서드를 제공하여 이러한 부분을 개선하고자 하였다.
HashMap.newHashMap
LinkedHashMap.newLinkedHashMap
WeakHashMap.newWeakHashMap
HashSet.newHashSet
LinkedHashSet.newLinkedHashSet
해당 메서드는 사전에 용량이 설정된 경우에 사용하도록 만들어진 컬렉션 팩토리 메서드로, 해당 메서드를 통해 고정된 크기의 객체를 추가하는 경우, 여유롭게 메모리 공간을 할당하여 확장(resize)없이 원소를 추가할 수 있게 해준다. 예를 들어 위의 로직에 해당 정적 팩토리 메서드를 적용한 결과는 다음과 같다.
num = 0, threshold: 2048, Table size: 0
num = 1, threshold: 1536, Table size: 2048
num = 768, threshold: 1536, Table size: 2048
num = 769, threshold: 1536, Table size: 2048
참고로 resize 내부적으로는 해시 버킷 테이블이 재할당된 이후 모든 값들의 hash를 재계산하는 등의 적지 않은 연산이 일어난다. 따라서 HashMap 내부의 동작에 대해 정확하게 이해하고, 불필요한 연산을 최소화해줄 필요가 있다.
- 내부 table 재할당 // HashMap$Node[1024] → HashMap$Node[2048]
- 내부 모든 값들의 hash 재계산 % 1024 → % 2048
- Node 재생성
- 트리 구조 변경
[ ConcurrentHashMap의 락 스트라이핑(Lock Striping) 기법 ]
애플리케이션을 개발하다 보면 동시성을 지원하는 HashMap이 필요해지는 순간이 있다. 자바에서는 기본적으로 synchronized 키워드로 동기화를 수행할 수 있기 때문에, 자바 역시 synchronized를 활용하는 Map 객체를 지원하고 있다.
Collections.synchronizedMap(new HashMap<Integer, String>(integers.size()));
이를 SynchronizedMap이라고 부르며, 내부 구현을 보면 실제로 synchronized를 통해 동기화를 수행하고 있음을 확인할 수 있다.

하지만 이러한 구현은 동시성 처리가 매우 떨어지기 때문에, 자바는 락 스트라이핑 기법을 활용한 ConcurrentHashMap을 제공한다.
락 스트라이핑(lock striping)이란 독립적인 객체를 여러 단위로 분할하고, 분할된 단위로 락을 나누어 적용하는 기법이다. ConcurrentHashMap의 경우 내부적으로 해시 버킷 단위로 연산이 나눠지기 때문에 락 스트라이핑 기법을 적용하기에 특히 적합하다. 따라서 특정한 해시 버킷에 대한 쓰기 처리를 하는 경우에만 동기화 처리를 지원하여, 버킷이 비어 있는 경우 (처음 삽입) 또는 카운터 증가 등 락 없이 처리 가능한 CAS(Compare And Swap) 방식으로 처리되는 반면, 버킷에 노드가 이미 있거나 버킷이 트리 구조(TreeBin)인 경우에는 synchronized로 락을 잡고 처리하는 것을 확인할 수 있다. 물론 값을 조회하는 경우에는 잠금이 필요없기 때문에 잠금 없이(Lock Free) 처리된다.

이러한 부분을 표로 정리하면 다음과 같다. 참고로 이는 자바8 이후의 ConcurrentHashMap의 동작에 대한 설명이며, 자바8 이전에는 Segment 기반으로 다른 방식으로 처리되었으니 참고해두도록 하자.
| 상황 | 동기화 방식 | 이유 |
| 버킷이 비어 있는 경우 (처음 삽입) | CAS (casTabAt) | 락 없이 빠르게 삽입하기 위해 |
| 카운터 증가 등 일부 작업 | CAS (casTabAt) | 락 없이 병렬로 처리할 수 있는 부분은 CAS 사용 |
| 버킷에 노드가 이미 있음 (충돌 발생) | synchronized | 노드가 여러 개라 탐색 및 삽입에 경쟁이 생기므로 락 필요 |
| 버킷이 TreeBin(트리 구조)일 경우 | synchronized | 트리 삽입은 복잡한 연산이므로 락이 필요 |
| 버킷 조회 | Lock Free | 조회 시에는 잠금이 필요 없음 |
ConcurrentHashMap 클래스는 동시성 친화적이며 최신 기술을 반영한 HashMap 버전으로, 내부 자료구조의 특정 부분만 잠궈 동시 추가, 갱신 작업을 허용하는 등 상당히 세밀하고 많은 최적화가 적용되었음을 확인할 수 있다. 그 외에도 ConcurrentHashMap은 Iterator이 ConcurrentModificationException을 발생시키지 않는데, ConcurrentHashMap의 Iterator는 즉시 멈춤(fail-fast) 대신 약한 일관성 전략을 취하기 때문이다. 이는 반복문과 동시에 컬렉션의 내용을 변경한다 해도 Iterator를 만들었던 시점의 상황대로 반복을 계속할 수 있다. 또한 Iterator를 만든 시점 이후에 변경된 내용을 반영해 동작할 수도 있다.
하지만 이로 인해 더 주의해야 할 부분 역시 존재하는데, Map의 모든 하위 클래스에서 공통적으로 사용하는 size 메소드나 isEmpty 메소드 등이 대표적인 예시이다.예를 들어 size 메소드는 그 결과를 리턴하는 시점에 이미 실제 객체의 수가 바뀌었을 수 있기 때문에 정확한 값일 수 없다. 또한 Map을 독점적으로 사용하는 것 역시 불가능한데, 이러한 단점을 트레이드 오프 하더라도 이러한 부분이 미칠 영향은 상당히 적기 때문에 오늘날의 ConcurrentHashMap은 매우 널리 활용되고 있다.
