
티스토리 뷰
[Java] 시스템의 성능과 volatile 키워드를 통한 메모리 가시성에 대한 이해(Memory Visiblilty)
망나니개발자 2025. 2. 18. 10:00
1. 스템의 성능과 volatile 키워드를 통한 메모리 가시성에 대한 이해(Memory Visiblilty)
[ 시스템의 성능에 대한 이해, 성능은 어디에서 오는가? ]
무어의 법칙(Moore's law)과 컴퓨터 구조(Computer Architecture)
무어의 법칙(Moore's law)은 인텔의 창업자 중 한명인 고든 무어(Gorden Moore)가 명명한 것으로, 경제적으로 생산 가능한 칩 위의 트랜지스터 수는 대략 2년마다 거의 2배로 증가함을 뜻한다.무어의 법칙이 성능이 아닌 트랜지스터 수를 기준으로 한다는 것은, 소프트웨어 엔지니어가 하드웨어 엔지니어로부터 얻어낼 수 있는 성능이 2배가 아님을 의미한다.
성능에는 여러 가지 복합작인 요소가 작용하는데, 그럼에도 불구하고 성능에 가장 결정적인 요인 하나를 뽑으라면 “다음에 실행할 명령과 관련된 데이터를 얼마나 빠르게 찾을 수 있는가?” 이다. 이를 이해하려면 기본적인 컴퓨터 구조에 대해 이해해야 한다. 기본적인 컴퓨터 구조의 구성 요소를 간략히 살펴보면 다음과 같다.
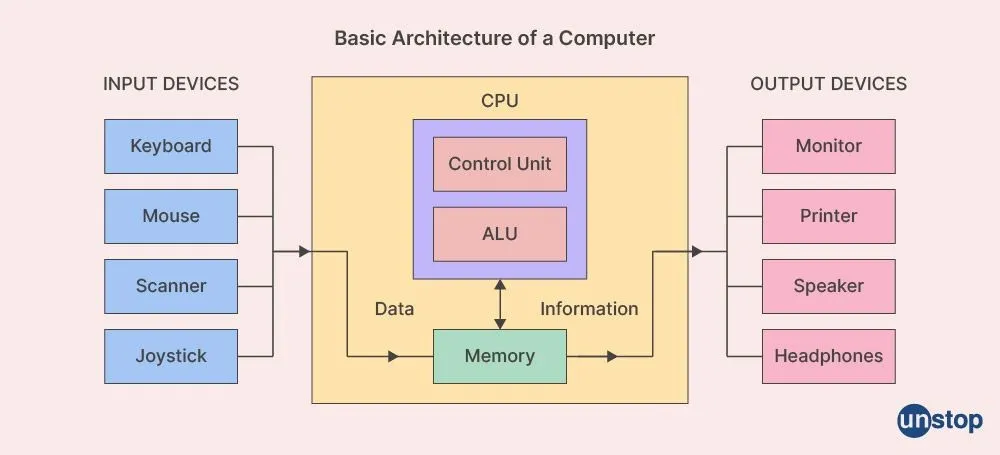
- 입/출력 장치(Input Devices): 키보드, 마우스, 모니터, 프린터 및 네트워크 인터페이스 등을 통해 사용자가 컴퓨터와 상호 작용하고 외부 세계와 데이터를 교환할 수 있도록 함
- 메모리(Memory): CPU가 빠르게 접근할 수 있는 데이터와 명령어를 저장하며, 메무리 중에서 RAM은 임시 저장 공간으로 사용되고, 캐시 메모리는 자주 사용되는 데이터에 더 빠르게 접근할 수 있도록 사용됨
- 중앙처리장치(CPU): 메모리로부터 처리할 명령어를 읽고 실행하는데, 산술 논리 연산 장치(ALU)는 산술 및 논리 연산을 수행하며, 제어 장치(Control Unit)는 명령어 해독 및 실행을 담당하고, 레지스터는 임시 데이터 저장을 위한 공간을 제공함
- 저장 장치: HDD, SSD와 같은 저장 장치는 데이터를 영구적으로 저장하는 데 사용됨
사용자가 프로그램을 실행하면, 운영체제가 메모리에 처리할 명령어들과 다음에 실행할 명령어의 주소(프로그램 카운터, PC) 등을 올려둔다. 그러면 CPU가 메모리에 저장된 명령어를 인출해 이를 처리하려고 하는데, 이때 명령어 처리를 위해 필요한 데이터가 있다면 역시 조회해야 한다. 그리고 바로 여기, “명령 실행을 위해 필요한 데이터를 얼마나 빠르게 찾을 수 있는가?”가 성능을 결정짓는 가장 결정적인 요인 중 하나이다.
캐시 계층 구조(Cache Hierarchy)
당연하게도 명령어를 처리하는 CPU와 인접할수록 데이터를 빠르게 조회할 수 있는데, 이러한 저장 공간을 계층화하여 표현하면 다음과 같다. Level 0에 가까울수록 조회 속도는 빠른 반면, 저장 공간이 작다.
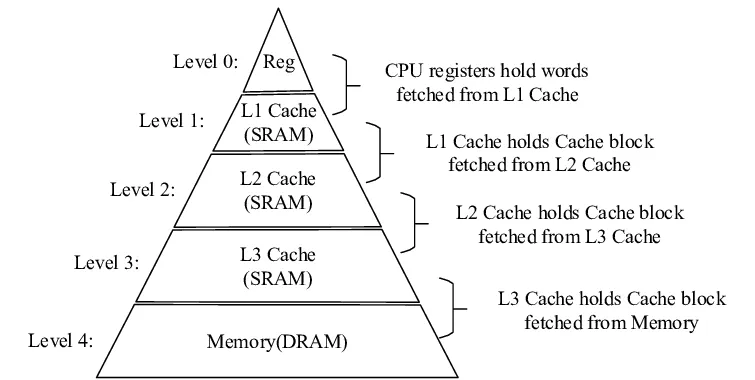
따라서 CPU 내의 데이터 처리를 위한 임시 저장 공간인 레지스터(Register)에서부터 시작하여 없으면 다음 저장 공간에서 데이터 조회를 시도해야 한다. 레지스터 이후에 데이터를 탐색하는 저장 공간은 코어 내부의 캐시에 해당하는데, L1/L2/L3 캐시라고 볼 수 있다.
- L1 캐시: 가장 빠르고 작은 캐시로 각 CPU 코어에 존재함. 일반적으로 코어당 64KB 정도의 용량을 가짐
- L2 캐시: L1 캐시보다 크고 약간 느리며 각 CPU 코어에 존재함. 일반적으로 코어당 256KB에서 1MB 사이의 용량을 가짐
- L3 캐시: 가장 크고 느린 캐시로, CPU의 모든 코어가 공유함. 일반적으로 10MB에서 64MB 사이이며, 서버용 프로세서에서는 256MB까지 커질 수 있음

캐시에서 데이터를 조회할 수 없다면 메모리에서 데이터를 가져와야 하는데, 캐시된 데이터가 없다면 데이터의 조회 속도가 현저하게 느려져 처리 속도가 훨씬 길어지게 된다. 컴퓨터는 처리할 데이터를 사용할 수 없는 경우 CPU 사이클의 속도와 상관없이 데이터를 사용할 수 있을 때까지 기다리면서 NOP(no operation)을 수행하고 기본적으로 멈추게 된다.
무어의 법칙은 트랜지스터 수의 지수적인 증가를 설명하며, 이로 인해 메모리도 혜택을 받고, 메모리 접근 속도도 지수적으로 증가했지만, 메모리 접근 속도는 CPU의 트랜지스터 추가보다 더 느리게 개선됐다. 즉, 코어가 필요한 데이터를 처리할 수 없어서 작업이 중단되어 성능 저하가 오게되는 것이다.
캐싱 여부에 따른 성능 차이
이러한 부분은 우리가 코드를 작성하여 직접 실험해 볼 수 있다. 처리량이 많은 코드의 경우 성능을 저하시키는 주요 요인 중 하나는 애플리케이션 코드를 실행할 때 발생하는 L1 캐시 미스 횟수다.
아래의 예제는 8MB 배열에 대해 루프를 반복하는 데 걸리는 시간을 출력한다. 두 루프 중 touchEveryItem는 배열의 모든 데이터에 직접 접근하여 데이터를 조회한다. 반면에 touchEveryLine는 16개 항목마다 1개씩만 데이터에 접근한다. 해당 코드를 실행하면 어떠한 결과가 나올까?
public class Caching {
private final int ARR_SIZE = 2 * 1024 * 1024;
private final int[] testData = new int[ARR_SIZE];
private void touchEveryItem() {
for (int i = 0; i < testData.length; i++) {
testData[i] = testData[i] + 1; // 모든 항목을 액세스 함
}
}
private void touchEveryLine() {
for (int i = 0; i < testData.length; i += 16) {
testData[i] = testData[i] + 1; // 각 캐시 라인을 액세스 함
}
}
private void run() {
for (int i = 0; i < 100; i++) {
long t0 = System.nanoTime();
touchEveryLine();
long t1 = System.nanoTime();
touchEveryItem();
long t2 = System.nanoTime();
long el1 = t1 - t0;
long el2 = t2 - t1;
System.out.println("Line: " + el1 + " ns; Item: " + el2);
}
}
public static void main(String[] args) {
new Caching().run();
}
}
touchEveryItem은 배열 내의 모든 바이트를 증가시키므로 touchEveryLine 보다 16배 더 많은 작업을 수행하지만, 실행 결과를 확인해보면 둘 사이에 작업량 만큼의 큰 차이는 존재하지 않음을 확인할 수 있다.
Line: 978666 ns; Item: 2869667
Line: 187291 ns; Item: 2480417
Line: 128333 ns; Item: 196833
Line: 126834 ns; Item: 191708
Line: 126125 ns; Item: 191292
Line: 126209 ns; Item: 191958
Line: 126958 ns; Item: 192250
Line: 126958 ns; Item: 164417
Line: 126709 ns; Item: 175416
Line: 126791 ns; Item: 162084
Line: 126875 ns; Item: 162000
Line: 126375 ns; Item: 181167
Line: 140625 ns; Item: 156459
...
그 이유는 전반적인 성능에서 주요한 역할을 하는 것은 데이터의 조회이고, 둘은 동일한 수의 캐시 라인 읽기를 수행하기 때문이다. L1 캐시 라인은 일반적으로 64바이트에 해당하며, 자바에서 Int는 4바이트이므로 L1 캐시 라인 하나에는 16개의 Int가 포함될 수 있다. 따라서 한 번에 16개의 데이터를 조회하여 L1 캐시에 데이터가 적재되고, 이후에 연산들은 캐시를 통해 처리하기 때문에 성능적으로 기대보다 큰 차이는 존재하지 않는 것이다. 따라서 CPU가 실제로 시간을 어떻게 소비하는지, 적어도 작동 수준에 대한 이해(또는 멘탈 모델)가 필요하다는 것을 알고 있어야 한다.
[ 메모리 가시성 그리고 재배치 문제(Memory Visibility and Reordering Problem) ]
메모리 가시성 문제(Memory Visibility Problem)
앞서 설명하였듯 우리의 컴퓨터는 성능을 높이기 위해 캐시를 적극적으로 활용하고 있는데, 이러한 부분은 기본적으로 다중 CPU(다중 코어)를 활용하는 현재가 되며 두드러지게 되었다.
먼저 마주할 수 있는 문제는 메모리 가시성(Memory Visiblity) 문제인데, 한 코어의 스레드에서 변경한 특정 메모리의 값이, 다른 코어의 스레드에서 제대로 읽혀지지 않는 문제라고 볼 수 있다. 멀티스레드 환경에서 스레드들은 각자의 캐시를 가지는 코어에 할당되어 병렬 실행될 수 있는데, 스레드들이 하나의 변수를 공유하면 각각의 코어가 개별 캐시를 소유하게 되고, 이로 인해 한 코어의 스레드에서 변경한 값이 다른 코어 스레드의 값과 불일치(Cache inconsistency)하는 것이다.
예를 들어 다음과 같은 코드가 있다고 하자. 해당 코드를 실행한 결과는 어떻게 나오게 될까?
public class TaskRunner {
private static int number;
private static boolean ready;
private static class Reader extends Thread {
@Override
public void run() {
while (!ready) {
Thread.yield();
}
System.out.println(number);
}
}
public static void main(String[] args) {
new Reader().start();
number = 42;
ready = true;
}
}
해당 출력의 결과는 예측할 수 없으며, 심지어 무한 루프에 빠질 수도 있다. 왜냐하면 메인 스레드가 실행되는 코어에서 number를 42, ready를 true로 변경한다고 하더라도, Reader 스레드를 실행시킨 2번 코어에서는 캐싱된 데이터로 인해 변경 전의 데이터인 0과 false를 만날 수 있기 때문이다.
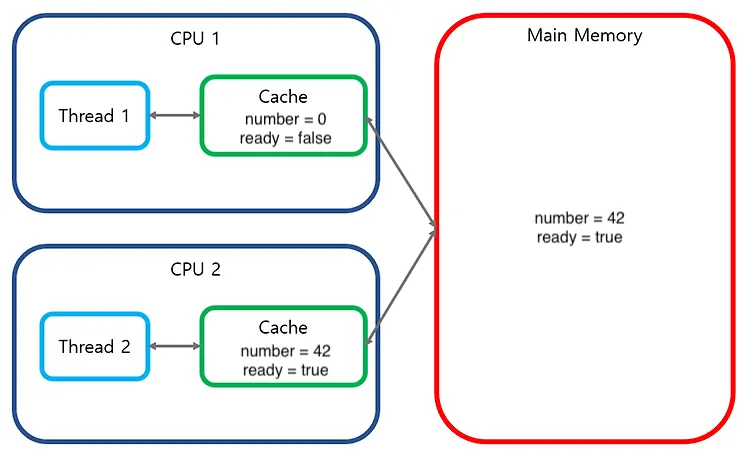
우리가 동시성 테스트를 위해 멀티스레드 기반의 작성할 때에도 다음과 같이 synchronized와 같은 동시성 제어 키워드가 없음에도 불구하고 동시성 문제가 없는 것처럼 테스트가 실행될 수 있다. 아래의 코드는 1개의 Order 객체에 대해 100개의 스레드가 동시에 변수를 차감하는 코드이다. 여러 스레드가 동시에 수를 차감함에도 불구하고 quantity 객체는 메모리 가시성 문제에 의해 1이 됨을 확인할 수 있다. 이러한 상황이 생기면 메모리 가시성 문제임을 빠르게 인지할 수 있어야 한다.
class OrderTest {
@Getter
@AllArgsConstructor
static class Order {
private int quantity;
public boolean subtract(int subtractQuantity) {
if (subtractQuantity >= quantity) {
return false;
}
this.quantity -= subtractQuantity;
return true;
}
}
@Test
void asyncSubtract() throws InterruptedException {
int numberOfThreads = 100;
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
List<Callable<Boolean>> tasks = new ArrayList<>();
Order order = new Order(201);
for (int i = 0; i < numberOfThreads; i++) {
tasks.add(() -> order.subtract(50));
}
executorService.invokeAll(tasks);
executorService.shutdown();
executorService.awaitTermination(10, TimeUnit.SECONDS);
assertThat(order.getQuantity()).isLessThan(1); // 메모리 가시성 문제에 의해 1이 되어버림
}
}
재배치 혹은 재정렬 문제(Reordering Problem)
메모리 가시성 문제 외에도 재배치 문제(Reordering Problem) 역시 발생할 가능성이 있다. 재배치 또는 재정렬(reordering)은 성능 향상을 위한 최적화 기술로, 컴파일러가 의도적으로 실행되는 코드의 순서를 변경하는 기법이다. 예를 들어 TaskRunner 코드를 기준으로 살펴보면 number를 42로 설정하는 로직과 ready를 true로 설정하는 로직의 순서가 바뀌는 것이다. 이는 우리의 머리 만으로 예측할 수 있는 것이 아니기 때문에 문제 원인 파악과 해결이 상당히 어려울 수 있다.
동기화를 지정하지 않으면 컴파일러나 프로세서, JVM 등이 프로그램 코드가 실행되는 순서를 임의로 바꿔 실행하는 이상한 경우가 발생하기도 한다. 따라서 동기화 되지 않은 상황에서 메모리 상의 변수를 대상으로 작성해둔 코드가 “반드시 이런 순서로 동작할 것이다”라고 단정지으면 위험하다.
[ Volatile 키워드와 Happens-Before 관계 ]
Volatile 키워드
앞서 설명했던 메모리 가시성 그리고 재배치 문제를 해결하는 데 도움을 주는 키워드가 바로 volatile이다. volatile은 모든 스레드가 항상 메인 메모리로부터 최신의 값을 읽도록 하여 volatile로 선언된 변수의 값이 바뀌어도 다른 스레드에서 항상 최신 값을 읽어갈 수 있도록 해준다.
volatile 키워드를 지정하면, 컴파일러와 런타임 모두 “이 변수는 공유해 사용하고, 따라서 실행 순서를 재배치 해서는 안 된다”고 이해한다. volatile로 지정된 변수는 프로세서의 레지스터에 캐시되지도 않고, 프로세서 외부의 캐시에도 들어가지 않기 때문에 volatile 변수의 값을 읽으면 항상 다른 스레드가 보관해둔 최신의 값을 읽어갈 수 있다.
따라서 volatile을 올바르게 사용하는 것은 미묘한 버그를 방지하는 데 필수적이라고도 볼 수 있다. volatile은 컴파일러에게 선언된 객체에 대해 문법 그대로의 동작을 적용하도록 지시하며, 특히 해당 객체에 대한 접근을 최적화하거나 재정렬하지 않도록 한다. 그리고 매번 값을 메모리에서 읽도록 강제할 수 있는 것이다. 하지만 이는 성능적인 이점을 포기하는 부분이 있으므로, 이러한 부분에 대해 올바르게 인지하고 사용하는 것이 필요하다.
volatile 외에도 락 역시 상호 배제 뿐만 아니라 정상적인 메모리 가시성을 확보하기 위해서도 사용될 수 있는데, 예를 들어 synchronized와 같은 키워드들을 사용한다면 volatile이 없어도 메모리 가시성을 보장받을 수 있다. 왜냐하면 synchronized와 volatile 키워드를 사용해 얻을 수 있는 가시성을 통해 메모리 배리어(memory barrier)라는 특별한 명령어를 사용하게 되기 때문이다. 메모리 배리어는 캐시를 플러시하거나 무효화하고, 하드웨어 관련된 쓰기 버퍼를 플러시하고, 실행 파인을 늦출 수 있다. 메모리 배리어를 사용하면 컴파일러가 제공하는 여러 가지 최적화 기법을 적용하지 않도록 하기 때문이다.
Happens-Before 관계
자바에서는 대표적으로 아래의 두 가지 상황에 대해 원자적으로 동작한다고 볼 수 있다.
- 참조 변수와 대부분의 기본 타입 변수(long과 double 제외)에 대한 읽기와 쓰기
- volatile로 선언된 모든 변수(long과 double 포함)에 대한 읽기와 쓰기
하지만 이 중에서 64비트를 사용하는 숫자형(double이나 long 등)에는 원자적 연산이 적용되지 않는데, 극단적인 상황이라면 이것이 잘못된 데이터를 조회하는 오류를 유발할 수 있다.자바 메모리 모델은 메모리에서 값을 가져오고(fetch) 저장하는(store) 연산이 단일해야 한다고 정의하고 있지만, volatile로 지정되지 않은 long이나 double 형의 64비트 값에 대해서는 메모리에 쓰거나 읽을 때 두 번의 32비트 연산을 사용할 수 있도록 허용하고 있다. 따라서 volatile을 지정하지 않은 long 변수의 값을 쓰는 기능과 읽는 기능이 서로 다른 스레드에서 동작한다면, 이전 값과 최신 값에서 각각 32비트를 읽어올 가능성이 생긴다.
원자적 동작은 중간에 다른 작업과 섞이지 않으므로 스레드 간 간섭 없이 사용할 수 있지만, 메모리 가시성 문제는 발생할 가능성이 있다. 하지만 volatile 변수를 사용하면 이런 오류의 위험이 줄어드는데, volatile 변수에 대한 모든 쓰기(write) 동작은 동일한 변수를 이후에 읽는(read) 동작과 Happens-Before 관계를 형성하기 때문이다.
Happens-Before 관계는 자바 메모리 모델(JMM, Java Memory Model)에서 쓰레드 간의 상호작용을 설명하는 개념이다. 특정 연산 A가 연산 B보다 happens-before 관계에 있다면, A의 결과가 B에서 반드시 보이며(가시성 보장), A가 B보다 먼저 실행됨이 보장된다(순서 보장). 다음 규칙 중 하나라도 만족하면 A happens-before B 관계를 보장해준다.
- 프로그램 순서 규칙: 단일 스레드 내에서 앞선 코드의 연산이 뒤의 코드보다 먼저 실행됨이 보장됨
- 모니터 락 규칙: 한 스레드가 synchronized 블록을 벗어나고(unlock) 이후 다른 스레드가 진입할 때(lock), unlock 이전의 연산이 lock 이후의 연산보다 먼저 일어남이 보장됨
- volatile 변수 규칙 (Volatile Rule): 한 스레드가 volatile 변수에 값을 쓰면, 이후 다른 스레드가 같은 변수를 읽을 때, 그 값이 반드시 반영됨
- 스레드 시작 규칙 (Thread Start Rule): Thread.start() 를 호출한 스레드에서 수행한 작업은 새로운 스레드에서 실행되는 코드보다 먼저 수행됨이 보장됨
- 스레드 종료 규칙 (Thread Termination Rule): 한 스레드에서 실행이 종료되면 (Thread.join() 호출), join을 호출한 스레드는 종료된 스레드에서 수행한 모든 작업을 볼 수 있음
- 객체 초기화 규칙 (Final Field Rule): final 필드는 생성자가 실행된 후 다른 스레드에서 올바르게 볼 수 있음
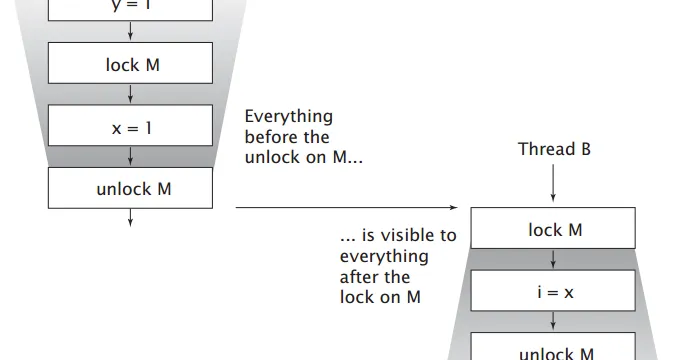
기술적으로, volatile 필드에 대한 모든 쓰기는 동일한 필드를 읽는 모든 후속 읽기보다 먼저 발생한다. 이것이 Java 메모리 모델(JMM)의 volatile 변수 규칙이다. 따라서 필요한 경우에 적절하게 volatile 키워드를 적용해줄 필요가 있다.
참고 자료
- 기본기가 탄탄한 자바 개발자 (제2판)
- https://www.linkedin.com/pulse/basic-computer-architecture-khalid-hasan-yyuuc
- https://docs.oracle.com/javase/tutorial/essential/concurrency/atomic.html
- https://docs.oracle.com/cd/E19683-01/806-5222/codingpractices-1/index.html
- Baeldung | Guide to the Volatile Keyword in Java
