
티스토리 뷰
[Post Mortem] 로블록스 장애 포스트모템(Roblox Return to Service 10/28-10/31 2021)
망나니개발자 2023. 9. 12. 10:002021년 10월, 로블록스(Roblox)에 완전 복구까지 3일 걸린 대규모 장애가 있었습니다. 관련 내용을 로블록스에서 정리하여 블로그에 올려주었는데, 이번에는 해당 내용을 살펴보도록 하겠습니다.
1. Introduction
[ Roblox Return to Service 10/28-10/31 2021 ]
10월 28일부터 10월 31일에 완전히 해결되기 까지 Roblox는 73시간 서비스 중단을 경험했습니다. 매일 5천만 명의 플레이어가 Roblox를 정기적으로 이용하고 있으며, 플레이어가 원하는 경험을 제공하기 위해 수백 개의 내부 온라인 서비스가 존재합니다. 다른 대규모 서비스와 마찬가지로 가끔 서비스 중단이 발생하지만, 이번에는 특히 길었기 때문에 주목할 만합니다. 서비스 중단에 대해 커뮤니티 여러분께 진심으로 사과드립니다.
문제의 근본 원인, 해결 방법, 향후 유사한 문제 재발 방지를 위해 취하고 있는 조치에 대한 이해를 돕기 위해 기술적 세부 사항을 공유하고자 합니다. 이번 장애로 인해 사용자 데이터가 손실되거나 권한이 없는 정보에 액세스한 사례는 없음을 다시 한 번 말씀드립니다.
Roblox 엔지니어링 팀과 HashiCorp의 기술 직원이 힘을 합쳐 Roblox를 다시 서비스하기 위해 노력했습니다. 문제가 해결될 때까지 엄청난 자원을 투입하고 지칠 줄 모르고 협력해준 HashiCorp 팀에 감사의 말씀을 전하고 싶습니다.
[ Outage Summary(장애 요약) ]
이번 장애는 기간과 복잡성에서 모두 독보적이었습니다. 근본 원인을 파악하고 서비스를 복구하기 위해 여러 가지 문제를 순차적으로 해결해야 했습니다.
- 서비스 중단은 73시간 동안 지속되었습니다.
- 근본 원인은 두 가지 문제 때문이었습니다. 읽기 및 쓰기 부하가 비정상적으로 높은 상태에서 Consul의 상대적으로 새로운 스트리밍 기능에서 과도한 경합과 성능 저하가 발생했습니다. 또한, 특정 부하 조건으로 인해 BoltDB에서 병적인 성능 문제가 발생했습니다. 오픈 소스 BoltDB는 Consul 내에서 리더 선출 및 데이터 복제를 위한 write-ahead-logs를 관리하는 데 사용됩니다.
- 여러 워크로드를 지원하는 단일 Consul 클러스터는 이러한 문제의 영향을 더욱 악화시켰습니다.
- Consul 구현 내부에 숨겨진 서로 연관없는 두 가지 문제를 파악하는 어려움이 서비스 중단을 연장시킨 주요 원인이었습니다.
- 서비스 중단의 원인을 더 잘 파악할 수 있는 핵심 모니터링 시스템은 Consul처럼 영향받은 시스템에 의존했습니다. 이 조합은 원인 파악을 심각하게 방해했습니다.
- 장기간의 완전 중단 상태에서 Roblox를 복구하기 위해 깊고 신중한 접근 방식을 취했으며, 이 또한 상당한 시간이 걸렸습니다.
- 모니터링 개선, 통합 가시성 스택의 순환 종속성 제거, 부트스트랩 프로세스 가속화를 위해 엔지니어링 노력을 더했습니다.
- 여러 가용 영역과 데이터 센터로 이전하기 위해 노력하고 있습니다.
- 이 사건의 근본 원인이었던 Consul 문제를 해결하고 있습니다.
[ Preamble: Our Cluster Environment and HashiStack(서문: 클러스터 환경과 해시스택) ]
Roblox의 핵심 인프라는 Roblox 데이터 센터에서 실행됩니다. Roblox는 자체 하드웨어를 배포하고 관리할 뿐만 아니라 하드웨어 위에 자체 컴퓨팅, 스토리지, 네트워킹 시스템을 구축합니다. 배포 규모는 18000대 이상의 서버와 170000개의 컨테이너로 상당히 큽니다.
여러 사이트에서 수천 대의 서버를 실행하기 위해 흔히 알려진 "HashiStack"을 활용합니다. Nomad, Consul, Vault를 통해 전 세계의 서버와 서비스를 관리하며, 이를 통해 Roblox 서비스 컨테이너를 오케스트레이션할 수 있습니다.
Nomad는 작업 스케줄링에 사용됩니다. 어떤 컨테이너를 어떤 노드에서 실행할지, 어떤 포트로 접근 가능한 지 결정합니다. 또한 컨테이너 상태도 확인합니다. 이 모든 데이터는 IP:포트 조합의 데이터베이스인 Service Registry로 전달됩니다. Roblox 서비스는 Service Registry를 통해 서로를 찾아 통신할 수 있습니다. 이를 "Service Discovery"이라고 합니다. 서비스 검색, 상태 확인, 세션 잠금(상단에 구축된 HA 시스템의 경우) 및 KV 저장소로 Consul을 사용합니다.
Consul는 두 가지 역할을 하는 머신 클러스터로 배포됩니다. "Voters"(5대의 머신)는 클러스터의 상태를 권한을 갖고 유지하며, "Non-Voters"(5대의 추가 머신)는 읽기 요청 확장을 위한 읽기 전용 복제본입니다. 특정 시점에 “Voters” 중 한 명이 클러스터에서 리더로 선출됩니다. 리더는 다른 투표자에게 데이터를 복제하고 기록된 데이터가 완전히 커밋되었는지 확인합니다. Consul은 Raft라는 알고리즘을 사용하여 리더를 선출하고, 클러스터의 각 노드가 업데이트에 동의하도록 하는 방식으로 클러스터 전체에 상태를 배포합니다. 리더 선거를 통해 리더는 하루에도 여러 번 바뀔 수 있습니다.
아래는 최근 Roblox Consul 대시보드 스크린샷입니다. 이 게시물에 언급된 주요 운영 지표 중 상당수는 정상 수준으로 표시되어 있습니다. 예를 들어 KV 적용 시간은 300ms 미만이면 정상으로 간주되며 현재 30.6ms입니다. Consul 리더는 지난 32ms 동안 클러스터의 다른 서버와 접촉했으며, 이는 방금 전의 일입니다.

10월 사고가 발생하기 몇 달 전, Roblox는 새로운 스트리밍 기능을 활용하기 위해 Consul 1.9에서 Consul 1.10으로 업그레이드했습니다. 이 스트리밍 기능은 Roblox와 같은 대규모 클러스터를 배포하는 데 필요한 CPU 및 네트워크 대역폭을 크게 줄이도록 설계되었습니다.
2. Body
[ Initial Detection (10/28 13:37, 초기 탐지) ]
10월 28일 오후, Vault 성능이 저하되고 한 대의 Consul 서버에 높은 CPU 부하가 발생했습니다. Roblox 엔지니어들이 조사를 시작했습니다. 이 시점에는 아직 플레이어가 영향을 받지 않았습니다.
[ Early Triage (10/28 13:37 – 10/29 02:00, 초기 분석) ]
초기 조사 결과, Vault 및 수많은 서비스들이 의존하는 Consul 클러스터가 비정상인 것으로 나타났습니다. 구체적으로, Consul이 데이터를 저장하는 기본 KV 저장소에 쓰기 소요 시간이 증가한 것으로 나타났습니다. 해당 작업의 평균 소요 시간은 보통 300ms 미만이었지만 현재는 2s였습니다. 하드웨어 문제는 Roblox 규모에서 드문 일이 아니며, Consul은 하드웨어 장애에도 견딜 수 있습니다. 그러나 하드웨어가 고장난 것이 아니라 단순히 느린 경우라면 전반적인 Consul 성능에 영향을 미칠 수 있습니다. 팀은 하드웨어 성능 저하를 근본 원인으로 의심하고 Consul 클러스터 노드 중 하나를 교체하기 시작했습니다. 이것이 사고 진단을 위한 첫 번째 시도였습니다. 이 무렵, HashiCorp의 직원이 Roblox 엔지니어와 함께 진단 및 문제 해결에 도움을 주었습니다. 이 시점부터 "팀" 및 "엔지니어링 팀"에 대한 모든 언급은 Roblox와 HashiCorp 직원을 모두 지칭합니다.
새로운 하드웨어 도입에도 불구하고 Consul 클러스터 성능은 계속 저하되었습니다. 16시 35분에 온라인 플레이어 수는 평소의 50%로 떨어졌습니다.
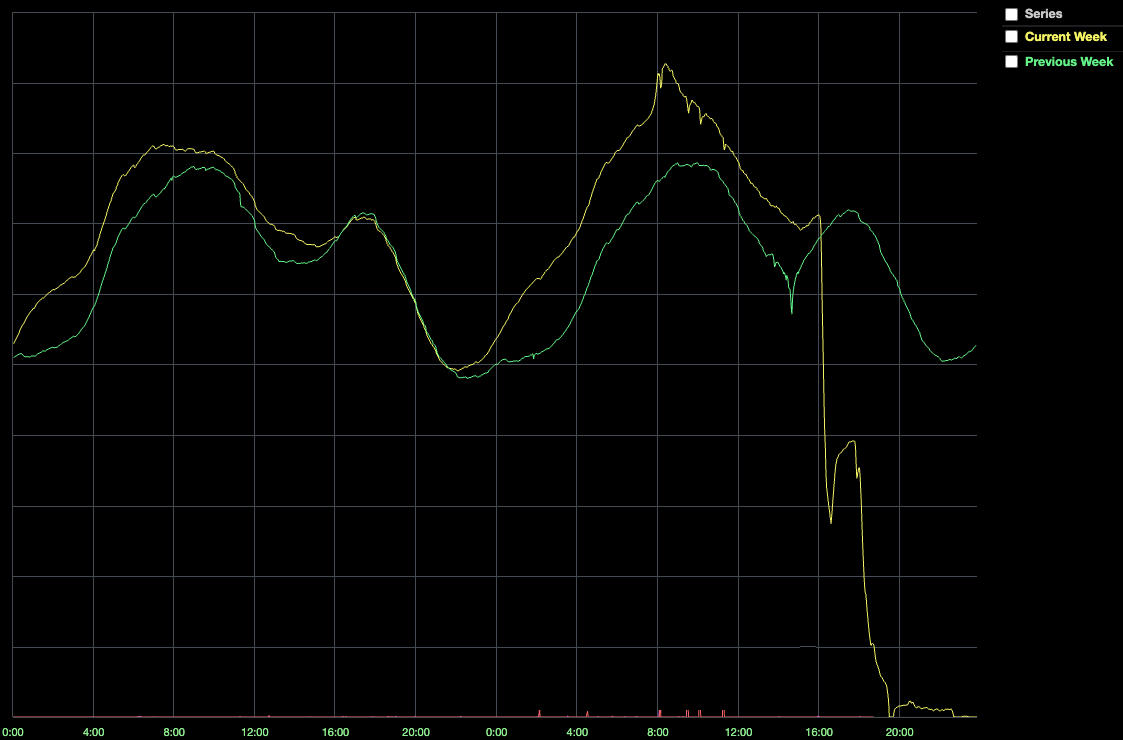
이러한 성능 저하는 심각한 시스템 상태 악하와 맞물려 결국 시스템 전체가 중단되는 결과를 초래했습니다. 왜 그랬을까요? Roblox 서비스는 다른 서비스와 통신하고자 할 때, 해당 서비스의 위치에 대한 최신 정보를 얻기 위해 Consul에 의존합니다. 따라서 Consul이 정상적이지 않으면 서버 연결에 어려움을 겪습니다. 또한, Nomad와 Vault는 Consul에 의존하기 때문에 Consul이 정상적이지 않으면 시스템이 새 컨테이너를 예약하거나 인증을 위한 production secrets를 획득할 수 없습니다. 간단히 말해, Consul은 단일 장애 지점이고 Consul이 정상적이지 않아서 시스템이 실패한 것입니다.
이 시점에서 무엇이 잘못되었는지에 대한 새로운 가설을 떠올렸는데, 바로 트래픽 증가였습니다. 시스템이 티핑 포인트에 도달하여 Consul을 구동 중인 서버가 더 이상 부하를 처리할 수 없어서 속도가 느려진 것일까요? 이것이 장애의 근본 원인을 진단하기 위한 두 번째 시도였습니다.
장애의 심각성을 감안하여 팀은 모든 Consul 클러스터 노드를 더 강력한 신규 장비로 교체하기로 결정했습니다. 해당 장비에는 128개의 코어(2배 증가)와 더 빠른 최신 NVME SSD 디스크가 장착되어 있었습니다. 19시까지 팀은 클러스터의 대부분을 새 머신으로 마이그레이션했지만 클러스터는 여전히 비정상이였습니다. 클러스터는 대부분의 노드가 쓰기를 따라잡을 수 없다고 보고했으며, KV 쓰기 작업의 평균 소요 시간은 여전히 약 2s였습니다.
[ Return to Service Attempt #1 (10/29 02:00 – 04:00, 첫 번째 서비스 복구 시도) ]
Consul 클러스터를 정상 상태로 되돌리려는 첫 두 번의 시도는 실패했습니다. 여전히 KV 쓰기 작업이 길어질 뿐만 아니라, Consul 리더가 다른 투표자들과 정기적으로 동기화되지 않는 새로운 현상이 발생했습니다.
팀은 서비스 중단 몇 시간 전의 스냅샷을 통해 전체 Consul 클러스터를 종료하고 상태를 재설정하기로 결정했습니다. 이렇게 하면 사용자 데이터 손실은 없지만 소량의 시스템 구성 데이터가 손실될 수 있음을 인지하고 있었습니다. 장애의 심각성과 필요한 경우 해당 시스템 구성 데이터를 수작업으로 복원할 수 있다는 자신감을 고려하여 이 정도는 감수할 수 있다고 판단했습니다.
시스템이 정상일 때 찍은 스냅샷에서 복원하면 클러스터가 정상 상태가 될 것으로 예상했지만 한 가지 추가 문제가 있었습니다. 이때 Roblox는 사용자에 의한 트래픽이 시스템을 통해 전달되지 않았음에도 불구하고, 내부 Roblox 서비스는 여전히 라이브 상태였으며 dependency 위치를 파악하고 상태 정보를 업데이트하기 위해 꾸준히 Consul과 통신하고 있었습니다. 이러한 읽기 및 쓰기로 인해 클러스터에 상당한 부하가 발생하고 있었습니다. 클러스터 재설정에 성공하더라도 부하로 인해 클러스터가 즉시 비정상 상태로 돌아갈 수 있다는 점이 염려되었습니다. 이를 해결하기 위해 클러스터에서 접근을 차단하도록 iptables를 구성했습니다. 이렇게 하면 클러스터를 제어된 방식으로 재가동할 수 있고 사용자 트래픽과 무관하게 Consul에 가해지는 부하가 문제의 일부인지 파악하는 데 도움이 됩니다.
재설정은 순조롭게 진행되었고 처음에는 지표가 양호해 보였습니다. iptables 블록을 제거하자 내부 서비스의 서비스 검색 및 상태 확인 부하가 기존대로 돌아왔습니다. 하지만 Consul 성능이 다시 저하되기 시작했고 결국 처음 시작점으로 돌아갔습니다: KV 쓰기 작업의 평균 소요 시간은 2s로 돌아갔습니다. Consul에 의존하는 서비스들은 스스로를 “비정상”으로 표시하기 시작했고, 결국 시스템은 이제 익숙한 문제 상태로 되돌아갔습니다. 이제 04:00이 되었습니다. Consul에 대한 부하가 문제를 일으킨 것이 분명했지만, 사고가 발생한 지 14시간이 넘었음에도 여전히 그 원인을 알지 못했습니다.
[ Return to Service Attempt #2 (10/29 04:00 – 10/30 02:00, 두 번째 서비스 복구 시도) ]
하드웨어 오류는 배제했습니다. 더 빠른 하드웨어는 도움이 되지 않았고, 나중에 알게 된 것처럼 안정성을 해칠 가능성이 있었습니다. Consul의 내부 상태를 재설정해도 도움이 되지 않았습니다. 사용자 트래픽이 유입되지 않았는데도 Consul은 여전히 느렸습니다. 저희는 클러스터로 트래픽이 천천히 다시 들어오도록 iptables를 활용했습니다. 단순히 재접속을 시도하는 수천 개의 컨테이너로 인해 클러스터가 비정상적 상태로 밀려난 것일까요? 이것은 장애의 근본 원인을 진단하기 위한 세 번째 시도였습니다.
엔지니어링 팀은 Consul 사용량을 줄인 후 신중하고 체계적으로 다시 도입하기로 결정했습니다. 투명한 시작점을 확보하기 위해 나머지 외부 트래픽도 차단했습니다. Consul을 사용하는 모든 서비스 목록을 수집하고 필수적이지 않다면 비활성화하도록 구성을 변경했습니다. 이 프로세스는 대상 시스템과 구성 변경 유형이 매우 다양했기 때문에 몇 시간이 걸렸습니다. 일반적으로 수백 개의 인스턴스가 실행되던 Roblox 서비스가 한 자릿수로 축소되었습니다. 상태 확인 주기를 60초에서 10분으로 줄여 클러스터에 추가적인 숨통을 틔워주었습니다. 가동이 중단된 지 24시간이 지난 10월 29일 16:00에 팀은 Roblox를 다시 온라인 상태로 만들기 위한 두 번째 시도를 시작했습니다. 이 재시도의 초기 단계는 순조롭게 진행되었지만 10월 30일 02:00에 Consul은 다시 정상적이지 않은 상태가 되었으며, 이번에는 이에 의존하는 Roblox 서비스의 부하가 현저히 줄어든 상태였습니다.
이때 처음 발견한 성능 저하의 원인이 Consul 사용량만은 아니라는 것이 분명해졌습니다. 이 사실을 깨닫고 팀은 다시 방향을 전환했습니다. Consul에 의존하는 Roblox 서비스의 관점에서 Consul을 바라보는 대신, Consul 내부에서 단서를 찾기 시작했습니다.
[ Research Into Contention (10/30 02:00 – 10/30 12:00, 경합에 대한 분석) ]
이후 10시간 동안 엔지니어링 팀은 디버그 로그와 운영 체제 수준 메트릭을 더 자세히 분석했습니다. 이는 Consul KV 쓰기가 오랜 시간 차단되는 것을 보여주었습니다. 즉, "경합"(Contention) 이 발생한 것입니다. 경합의 원인이 처음부터 명확하지는 않았지만, 한 가지 가설은 중단 초기에 64코어 서버에서 128코어 서버로 전환한 것이 오히려 문제를 악화시켰을 수 있다는 것이었습니다. 아래 스크린샷에 표시된 htop 데이터와 성능 디버깅 데이터를 살펴본 후, 팀은 중단 전과 유사한 64코어 서버로 돌아가는 것이 좋겠다는 결론을 내렸습니다. 팀은 하드웨어를 준비하기 시작했습니다. Consul을 설치하고, 운영 체제 구성을 세 번 점검하고, 가능한 세밀하게 서버를 투입할 준비를 마쳤습니다. 이후 팀은 Consul 클러스터를 64 CPU 코어 서버로 다시 전환했지만 도움이 되진 않았습니다. 이는 사고의 근본 원인을 진단하기 위한 네 번째 시도였습니다.
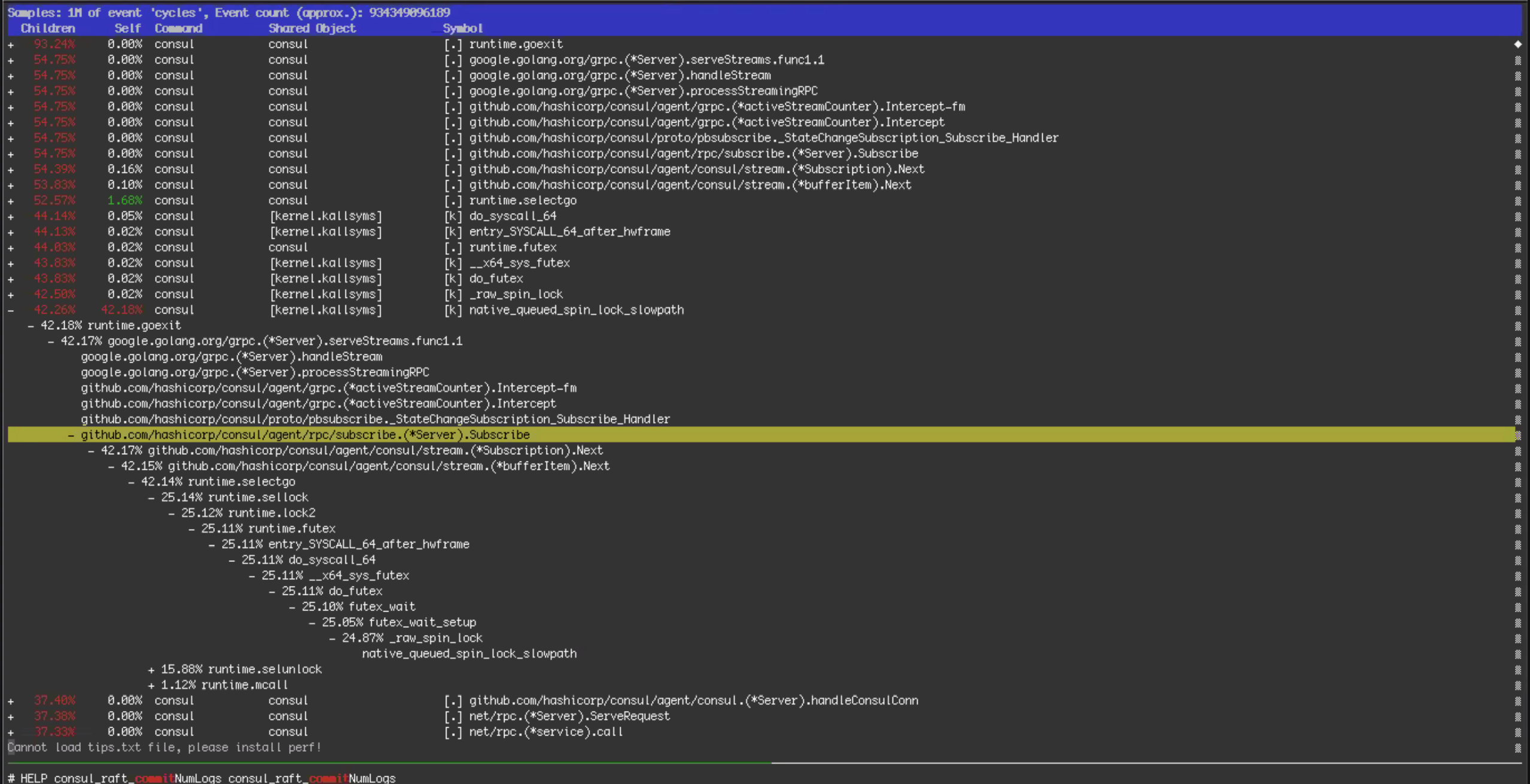
[ Root Causes Found (10/30 12:00 – 10/30 20:00, 근본 원인의 발견) ]
몇 달 전, Roblox는 일부 서비스에서 새로운 Consul 스트리밍 기능을 활성화했습니다. Consul 클러스터의 CPU 사용량과 네트워크 대역폭을 낮추기 위해 설계된 이 기능은 기대한 대로 작동했고, 그 후 몇 달 동안 더 많은 서비스에서 이를 점진적으로 활성화했습니다. 서비스 중단 하루 전인 10월 27일 14:00에 트래픽 라우팅을 담당하는 백엔드 서비스에서 이 기능을 활성화했습니다. 이때 연말에 보통 발생하는 트래픽 증가에 대비하기 위해 트래픽 라우팅 노드 수도 50% 늘렸습니다. 장애 시작 하루 전까지만 해도 시스템은 해당 수준의 스트리밍을 원활하게 처리했기 때문에 처음에는 성능 변화가 생긴 이유를 명확히 알 수 없었습니다. 하지만 Consul 서버의 성능 보고서와 플레임 그래프를 분석한 결과, 스트리밍 코드 경로가 높은 CPU 사용량을 유발하는 경합의 원인이라는 증거를 발견했습니다. 트래픽 라우팅 노드를 포함한 모든 Consul 시스템에서 스트리밍 기능을 비활성화했습니다. 구성 변경은 15:51에 전파가 완료되었으며, 이때 Consul KV 쓰기 평균 시간이 300ms로 낮아졌습니다. 마침내 돌파구를 찾았습니다.
스트리밍이 문제가 된 이유는 무엇이었나요? HashiCorp는 스트리밍이 전반적으로 더 효율적이지만, 롱 폴링보다 동시성 제어 요소(Go 채널)를 더 적게 사용한다고 설명했습니다. 특히 읽기 부하와 쓰기 부하가 매우 높은 경우, 스트리밍 설계는 단일 Go 채널의 경합 양을 가중시켜 쓰기 중에 블로킹을 유발하므로 효율성이 현저히 떨어지게 됩니다. 이러한 동작은 코어 수가 더 많은 서버의 영향도 설명해줍니다. 해당 서버는 NUMA 메모리 모델을 사용하는 듀얼 소켓 아키텍처였습니다. 따라서 이 아키텍처에서는 공유 리소스에 대한 추가 경합이 더 심해졌습니다. 스트리밍을 해제함으로써 Consul 클러스터의 상태가 크게 개선되었습니다.
획기적인 해결책을 찾았음에도 불구하고 아직 벗어난 것은 아니었습니다. Consul이 간헐적으로 새로운 클러스터 리더를 선출하는 것은 정상이었지만, 스트리밍을 비활성화하기 전에 보았던 것과 마찬가지로 지연 문제가 일부 리더에서 계속 나타나고 있었습니다. 특정 리더의 지연 문제에 대한 근본 원인을 가리키는 명백한 단서는 없었고, 특정 서버가 리더로 선출되지 않는 한 클러스터는 정상이라는 증거가 있었기 때문에, 문제가 있는 리더를 계속 선출되지 않도록 실용적인 문제 해결 판단을 내렸습니다. 이를 통해 Consul에 의존하는 Roblox 서비스를 정상 상태로 복구하는 데 집중할 수 있었습니다.
하지만 지연 문제가 발생하는 리더들에게는 무슨 일이 있었던 걸까요? 사고 당시에는 이 사실을 파악하지 못했지만, HashiCorp 엔지니어들은 가동 중단 이후 며칠 만에 근본 원인을 파악했습니다. Consul은 널리 사용되는 오픈 소스 기반의 영속성 도구인 BoltDB를 사용하여 Raft 로그를 저장합니다. 이는 Consul의 현재 상태를 저장하는 데 사용되지 않고, 적용된 작업 로그를 롤링하는 데 사용됩니다. BoltDB가 무한정 커지는 것을 방지하기 위해 Consul은 정기적으로 스냅샷을 수행합니다. 스냅샷 작업은 Consul의 현재 상태를 디스크에 기록한 다음 가장 오래된 로그를 BoltDB에서 삭제합니다.
그러나 BoltDB의 설계로 인해 가장 오래된 로그 항목이 삭제되더라도 BoltDB가 디스크에서 사용하는 공간은 절대 줄어들지 않습니다. 대신, 삭제된 데이터를 저장하는 데 사용된 모든 페이지(파일 내의 4KB 세그먼트)가 "free"으로 표시되어 이후의 쓰기에 재사용됩니다. BoltDB는 "freelist"라는 구조에서 이러한 free 페이지를 추적합니다. 일반적으로 쓰기 지연 시간은 freelist를 업데이트하는 데 걸리는 시간에 큰 영향을 받지 않지만, Roblox의 워크로드에서는 freelist 유지 관리 비용이 매우 많이 드는 BoltDB의 병적인 성능 문제가 노출되었습니다.
[ Restoring Caching Service (10/30 20:00 – 10/31 05:00, 캐시 서비스 복구) ]
서비스가 중단된 지 54시간이 지났습니다. 스트리밍이 비활성화되고 지연 문제가 발생하는 리더가 선출되는 것을 방지하는 절차가 마련되면서 이제 Consul은 계속 안정적이었습니다. 팀은 서비스 재개에 집중할 준비가 되었습니다.
Roblox는 백엔드에 전형적인 마이크로서비스 패턴을 사용합니다. 마이크로서비스 “스택”의 맨 아래에는 데이터베이스와 캐시가 있습니다. 데이터베이스는 서비스 중단의 영향을 받지 않았지만, 일반적인 시스템 운영 중에 여러 계층에서 초당 10억 건의 요청을 정기적으로 처리하는 캐싱 시스템에는 문제가 발생했습니다. 캐시는 기본 데이터베이스에서 쉽게 다시 채울 수 있는 일시적인 데이터를 저장하기 때문에 캐싱 시스템을 정상 상태로 되돌릴 수 있는 가장 쉬운 방법은 캐시를 다시 배포하는 것이었습니다.
캐시 재배포 과정에서 일련의 문제가 발생했습니다.
- 이전에 수행한 Consul 클러스터 스냅샷 재설정으로 인해, 캐시 시스템이 Consul KV를 통해 관리하는 내부 스케줄링 데이터가 올바르지 않은 것 같습니다.
- 작은 캐시 배포는 예상보다 오래 걸렸고, 큰 캐시 배포는 완료되지 않았습니다. 작업 스케줄러가 정상 상태로 판단했지만 비정상 상태인 노드도 있었던 것으로 밝혀졌습니다. 그 결과 작업 스케줄러가 해당 노드에서 캐시 작업을 끊임없이 스케줄링하려고 했지만, 노드가 비정상 상태라 실패했습니다.
- 캐싱 시스템의 자동화된 배포 도구는 대규모 클러스터를 처음부터 부트스트랩하려는 반복적인 시도가 아니라 이미 대규모 트래픽을 처리하고 있는 대규모 배포에 대한 점진적인 조정을 지원하도록 구축되었습니다.
팀은 밤새도록 이러한 문제를 파악 및 해결하고, 캐시 시스템이 올바르게 배포되었는지 확인하고, 정확성 검증을 위해 노력했습니다. 서비스가 중단된 지 61시간이 지난 10월 31일 05:00에 Consul 클러스터와 캐싱 시스템이 정상적으로 작동하기 시작했습니다. 나머지 Roblox를 가동할 준비가 되었습니다.
[ The Return of Players (10/31 05:00 – 10/31 16:00, 플레이어들의 복귀) ]
최종 서비스 복구는 31일 05:00에 공식적으로 시작되었습니다. 캐싱 시스템과 마찬가지로, 초기 중단 또는 문제 해결 단계에서 실행 중인 서비스의 상당 부분이 종료되었습니다. 팀은 해당 서비스들을 올바른 컴퓨팅 능력에서 재시작하고 정상 작동하는지 확인해야 했습니다. 이 작업은 순조롭게 진행되었고, 10시가 되자 플레이어들에게 게임을 공개할 준비가 되었습니다.
트래픽이 폭주했을 때, 콜드 캐시와 아직 불확실한 시스템으로 인해 불안정한 상태로 돌아가는 것을 원하지 않았습니다. 트래픽 폭주를 피하기 위해 DNS steering을 사용하여 Roblox에 접속할 수 있는 플레이어 수를 관리했습니다. 이를 통해 무작위로 선택된 특정 비율의 플레이어는 허용하고 다른 플레이어는 static 페이지로 계속 리디렉션할 수 있었습니다. 비율을 늘릴 때마다 데이터베이스 로드, 캐시 성능, 전반적인 시스템 안정성을 점검했습니다. 작업은 하루 종일 계속되었고, 약 10% 단위로 접속률을 높였습니다. 가장 열성적인 플레이어 중 일부가 트위터의 DNS 조정 체계를 파악하고 트위터에서 이 정보를 교환하기 시작하여 서비스 재가동 시 '조기' 접속을 할 수 있도록 도와주는 것을 보면서 즐거웠습니다. 서비스 중단이 시작된 지 73시간이 지난 일요일 16시 45분, 100%의 플레이어에게 접속 권한이 주어졌고 Roblox는 정상적으로 작동했습니다.
[ Further Analysis and Changes Resulting from the Outage(서비스 중단으로 인한 추가 분석 및 변경 사항) ]
10월 31일에 플레이어가 Roblox로 복귀할 수 있게 되었지만, Roblox와 Hashicorp는 다음 주 내내 서비스 중단에 대한 이해를 계속해서 개선해나갔습니다. 새로운 스트리밍 프로토콜의 특정 경합 문제를 파악하고 격리했습니다. Hashicorp는 Roblox 사용량과 비슷한 규모의 스트리밍을 벤치마킹한 적이 있었지만, 많은 수의 스트림과 높은 이탈률의 조합으로 인해 이러한 특정 동작을 관찰한 적은 없었습니다. Hashicorp 엔지니어링 팀은 특정 경합 문제를 재현하기 위해 새로운 벤치마크 실험실을 만들고 추가적인 규모 테스트를 수행하고 있습니다. 또한 Hashicorp는 극심한 부하에서 경합을 피하고 안정적인 성능을 보장하기 위해 스트리밍 시스템의 설계를 개선하고자 노력하고 있습니다.
리더 지연 문제에 대한 추가 분석을 통해 2초 단위의 Raft 데이터 쓰기 및 클러스터 일관성 문제의 주요 원인도 밝혀냈습니다. 엔지니어들은 아래 그림과 같은 불꽃 그래프를 보고 BoltDB의 내부 작동을 더 잘 이해할 수 있었습니다.

앞서 언급했듯이, Consul은 BoltDB라는 영속성 라이브러리를 통해 Raft 로그 데이터를 저장합니다. 장애 중에 만들어진 특정 사용 패턴으로 인해 16KB 쓰기 작업이 오히려 훨씬 더 커졌습니다. 이 그림에서 문제를 확인할 수 있습니다.
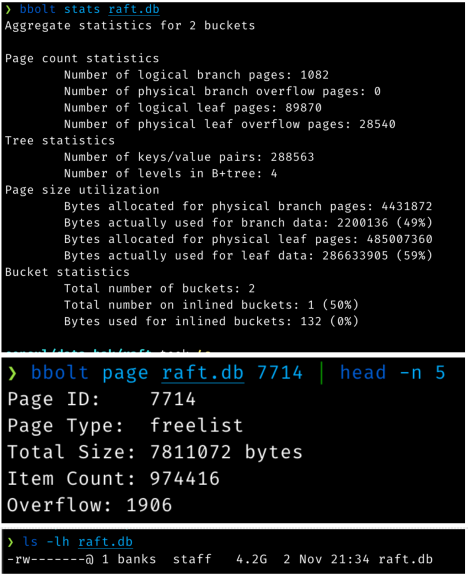
앞선 출력 명령은 여러 가지를 알려줍니다.
- 4.2GB 로그 저장소는 실제 데이터(모든 인덱스 내부 포함)의 489MB만 저장하고 있습니다. 3.8GB는 "빈" 공간입니다.
- freelist는 거의 백만 개의 free 페이지 ID를 포함하므로 7.8MB입니다.
즉, 로그가 추가될 때마다(일괄 처리 후 각 Raft가 쓸 때마다), 추가되는 실제 원시 데이터가 16KB 이하임에도 불구하고 7.8MB의 새로운 freelist가 디스크에 기록되고 있다는 뜻입니다.
또한 이러한 작업에 대한 Back pressure으로 인해 전체 TCP 버퍼가 생성되어 비정상 리더의 쓰기 시간이 2~3초로 증가했습니다. 아래 이미지는 사고 당시 TCP Zero Windows에 대한 연구 결과를 보여줍니다.

HashiCorp와 Roblox는 데이터베이스를 "압축"하기 위해 기존 BoltDB 도구 기반의 프로세스를 개발 및 배포하여 성능 문제를 해결했습니다.
3. Recent Improvements and Future Steps(최근 개선 사항 및 향후 단계)
서비스 중단이 발생한 지 2.5개월이 지났습니다. 그 동안 어떻게 지냈나요? 장애를 통해 최대한 많은 것을 배우고, 이를 통해 엔지니어링 우선순위를 조정하고, 시스템을 적극적으로 강화하는 데 시간을 보냈습니다. Roblox의 가치 중 하나는 커뮤니티에 대한 존중이므로, 더 빨리 게시물을 발행하여 무슨 일이 있었는지 설명할 수도 있었지만, 게시하기 전에 시스템 안정성을 개선하는 데 상당한 진전을 이루어 커뮤니티 여러분께 빚을 졌다고 생각했습니다.
완료된 개선 사항과 현재 진행 중인 안정성 개선 사항 목록은 너무 길고 상세하여 이 글에 모두 담을 수 없지만, 주요 항목은 다음과 같습니다:
[ Telemetry Improvements(텔레메트리 개선) ]
Roblox의 원격 분석 시스템과 Consul 사이에 순환적 의존성이 있었기 때문에 Consul이 비정상일 때 무엇이 문제인지 쉽게 파악할 수 있는 원격 분석 데이터가 부족했습니다. 이러한 순환적 종속성을 제거했습니다. 원격 분석 시스템은 더 이상 모니터링을 위한 Consul 기반 시스템에 의존하지 않습니다.
원격 분석 시스템을 확장하여 Consul 및 BoltDB 성능에 대해 더 나은 가시성을 확보했습니다. 이제 시스템이 서비스 상태에 가까워지는 징후가 있을 경우 고도로 타겟팅된 알림을 받게 됩니다. 또한 원격 측정 시스템을 확장하여 Roblox 서비스와 Consul 간의 트래픽 패턴에 대한 가시성을 더욱 강화했습니다. 다양한 수준에서 시스템의 동작과 성능에 대한 추가적인 가시성은 시스템 업그레이드 및 디버깅 세션 중에 도움이 되었습니다.
[ Expansion Into Multiple Availability Zones and Data Centers(여러 가용 영역 및 데이터 센터로의 확장) ]
하나의 Consul 클러스터에서 모든 Roblox 백엔드 서비스를 실행하면 이러한 유형의 서비스 중단에 노출될 수 있습니다. 저희는 이미 백엔드 서비스를 호스팅하기 위해 지리적으로 분리된 추가 데이터 센터에 서버와 네트워킹을 구축했습니다. 해당 데이터 센터 내에서 여러 가용성 영역으로 이전하는 노력을 진행 중이며, 이를 가속화하기 위해 엔지니어링 로드맵과 인력 배치 계획을 대폭 수정했습니다.
[ Consul Upgrades and Sharding(Consul 업그레이드와 샤딩) ]
Roblox는 여전히 빠르게 성장하고 있으므로 여러 개의 Consul 클러스터를 사용하더라도 Consul에 가해지는 부하를 줄이고자 합니다. 저희 서비스에서 Consul의 KV 저장소와 상태 확인을 사용하는 방식을 검토하여 일부 중요 서비스를 자체 전용 클러스터로 분할하여 중앙 Consul 클러스터의 부하를 보다 안전한 수준으로 낮췄습니다.
일부 핵심 Roblox 서비스는 더욱 적합한 다른 스토리지 시스템이 있음에도 불구하고 편리하게 데이터를 저장하기 위해 Consul의 KV 스토어를 직접 사용하고 있습니다. 이 데이터를 더 적합한 스토리지 시스템으로 마이그레이션하는 작업을 진행 중입니다. 이 작업이 완료되면 Consul의 부하도 줄어들 것입니다.
사용되지 않는 대량의 KV 데이터를 발견했습니다. 이 쓸모없는 데이터를 삭제하여 Consul의 성능이 개선되었습니다.
Roblox는 HashiCorp와 긴밀히 협력하여 무한한 freelist 증가 등의 문제가 없는 bbolt라는 후속 버전으로 볼트DB를 대체하는 새로운 버전의 Consul를 배포하고 있습니다. 연말 트래픽이 폭주하는 시기에 복잡한 업그레이드를 피하기 위해 의도적으로 이 작업을 새해로 연기했습니다. 이 업그레이드는 현재 테스트 중이며 1분기에 완료될 예정입니다.
[ Improvements To Bootstrapping Procedures and Config Management(부트스트랩 절차 및 구성 관리 개선 사항) ]
Roblox 서비스에 필요한 캐시의 배포 및 워밍업 등 여러 가지 요인으로 인해 서비스 복귀 작업이 지연되었습니다. 저희는 이 프로세스를 보다 자동화하고 오류를 줄이기 위해 새로운 도구와 프로세스를 개발하고 있습니다. 특히 캐시 배포 메커니즘을 재설계하여 캐시 시스템을 처음부터 빠르게 가동할 수 있도록 했습니다. 이에 대한 구현이 진행 중입니다.
저희는 HashiCorp와 협력하여 장기간 이용이 불가능했던 대규모 작업을 보다 쉽게 처리할 수 있는 몇 가지 Nomad 개선 사항을 확인했습니다. 이러한 개선 사항은 이달 말 예정된 다음 Nomad 개선의 일부로 배포될 예정입니다.
더 빠른 장비 구성 변경을 위한 메커니즘을 개발하여 배포했습니다.
[ Reintroduction of Streaming(스트리밍 재도입) ]
원래 Consul 클러스터의 CPU 사용량과 네트워크 대역폭을 낮추기 위해 스트리밍을 배포했습니다. 새로운 구현이 워크로드 규모에 맞게 테스트되고 나면 신중하게 시스템에 다시 도입할 예정입니다.
[ A Note on Public Cloud(퍼블릭 클라우드에 대한 고려) ]
이러한 서비스 중단이 발생한 상황에서 Roblox가 퍼블릭 클라우드로 이전하고 타사가 기본 컴퓨팅, 스토리지 및 네트워킹 서비스를 관리하도록 하는 것을 고려할지 묻는 것은 당연합니다.
Roblox의 또 다른 가치 중 하나는 “장기적 관점”이며, 의사결정에 큰 영향을 미칩니다. 자체 기본 인프라를 온프레미스로 구축 및 관리하는 이유는 현재 규모와 플랫폼이 성장함에 따라 도달할 규모를 고려할 때, 이것이 비즈니스와 커뮤니티를 지원하는 가장 좋은 방법이라고 믿기 때문입니다. 특히 백엔드 및 네트워크 엣지 서비스를 위한 자체 데이터 센터를 구축하고 관리함으로써 퍼블릭 클라우드에 비해 비용을 크게 절감할 수 있었습니다. 이렇게 절감한 비용은 플랫폼에서 크리에이터에게 지급할 수 있는 금액에 직접적인 영향을 미칩니다. 또한 자체 하드웨어를 소유하고 자체 엣지 인프라를 구축함으로써 성능 편차를 최소화하고 전 세계 플레이어의 지연 시간을 세심하게 관리할 수 있습니다. 일관된 성능과 짧은 지연 시간은 퍼블릭 클라우드 제공업체의 데이터 센터 근처에 있지 않은 플레이어의 경험에 매우 중요합니다.
저희는 특정 접근 방식에 이념적으로 얽매이지 않고, 플레이어와 개발자에게 가장 적합한 사용 사례라면 퍼블릭 클라우드를 사용합니다. 예를 들어, 버스트 용량, 개발 워크플로우의 상당 부분, 대부분의 사내 분석에 퍼블릭 클라우드를 사용합니다. 일반적으로 퍼블릭 클라우드는 성능과 지연 시간이 중요하지 않고 제한된 규모로 실행되는 애플리케이션에 적합한 도구라고 생각합니다. 하지만 성능과 지연 시간이 가장 중요한 워크로드의 경우, 자체 인프라를 온프레미스로 구축하고 관리하기로 결정했습니다. 이러한 선택에는 시간, 비용, 인력이 필요하다는 것을 알면서도 더 나은 플랫폼을 구축할 수 있다는 것을 알기에 내린 결정입니다. 이는 “장기적 관점”이라는 가치와 일치합니다.
[ System Stability Since The Outage(장애 이후의 시스템 안정성) ]
Roblox는 보통 12월 말에 트래픽이 급증합니다. 아직 해야 할 안정화 작업이 많이 남아 있지만, 12월 트래픽 급증 기간 동안 Roblox는 단 한 건의 심각한 프로덕션 장애도 발생하지 않았으며, Consul과 Nomad의 성능과 안정성이 모두 우수했다는 사실을 보고하게 되어 기쁘게 생각합니다. 즉각적인 안정성 개선 작업이 이미 성과를 거두고 있는 것으로 보이며, 장기 프로젝트가 마무리되면 더 좋은 결과가 있을 것으로 기대합니다.
[ Closing Thoughts(마무리 생각) ]
이해와 지지를 보내주신 전 세계 Roblox 커뮤니티에 감사의 말씀을 드립니다. Roblox의 또 다른 가치 중 하나는 책임감이며, 이번 사태에 대해 전적으로 책임을 지고 있습니다. 다시 한 번 HashiCorp 팀에게 진심으로 감사의 말씀을 전합니다. HashiCorp 엔지니어들은 이 전례 없는 서비스 중단이 시작되었을 때 저희를 지원하기 위해 뛰어들어 곁을 떠나지 않았습니다. 서비스 중단이 두 달이 지난 지금도 Roblox와 HashiCorp 엔지니어들은 긴밀한 협업을 통해 유사한 서비스 중단이 다시는 발생하지 않도록 최선을 다하고 있습니다.
마지막으로, 이곳이 왜 일하기 좋은 곳인지 입증해 준 Roblox 동료들에게 감사의 말씀을 전합니다. Roblox는 예의와 존중을 믿습니다. 일이 잘 풀릴 때는 예의와 존중을 지키기 쉽지만, 상황이 어려울 때가 바로 서로를 어떻게 대하는지의 진정한 시험대입니다. 73시간 동안 서비스 중단이 지속되는 동안 시간이 촉박하고 스트레스가 쌓이는 상황에서 누군가가 이성을 잃고 무례한 말을 하거나 이 모든 것이 누구의 잘못인지 큰 소리로 궁금해하는 것을 보는 것은 놀랍지 않습니다. 하지만 그런 일은 일어나지 않았습니다. 우리는 서로를 지지했고, 서비스가 정상화될 때까지 24시간 내내 하나의 팀으로 함께 일했습니다. 물론 이번 서비스 중단과 이로 인해 커뮤니티에 미친 영향이 자랑스러운 것은 아니지만, 한 팀으로 뭉쳐 Roblox를 다시 살리기 위한 노력과 모든 단계에서 예의와 존중으로 서로를 대했던 점이 자랑스럽습니다.
저희는 이번 경험을 통해 많은 것을 배웠으며, 앞으로 더욱 강력하고 신뢰할 수 있는 플랫폼이 되기 위해 그 어느 때보다 최선을 다하고 있습니다.
다시 한 번 감사드립니다.
4. Summary(요약)
[ Summary(요약) ]
- 장애 원인
- 읽기 및 쓰기 부하가 비정상적으로 높은 상태에서 Consul의 신규 스트리밍 기능에서 과도한 경합과 성능 저하가 발생함
- Consul 내에서 리더 선출 및 데이터 복제를 위한 write-ahead-logs를 처리하는 오픈 소스 BoltDB에서 특정 부하 시에 성능 문제가 발생함
- 연관 없는 위의 두 가지 Consul 내부 구현 문제에 의해 Consul 클러스터에 문제가 발생하였고, Consul에 의존하여 영향을 받은 핵심 모니터링 시스템은 원인 파악을 어렵게 만듬
- 복구 작업
- 하드웨어 성능 저하를 근본 원인으로 의심하고 Consul 클러스터 노드 중 하나를 교체함(해결 안됨)
- 트래픽 증가를 의심하고 모든 Consul 클러스터의 노드를 64 코어에서 128 코어의 신규 장비로 교체함(해결 안됨)
- Consul 리더가 다른 투표자들과 정기적으로 동기화되지 않는 새로운 현상이 발생함(두 번째 이슈 발생)
- 시스템이 정상일 때 찍은 스냅샷으로 Consul 클러스터를 복원하고, Consul에 가해지는 트래픽 제어를 위해 iptables를 구성함(해결 안됨 but Consul에 대한 부하가 문제임은 파악함)
- Roblox 서비스의 Consul에 대한 사용량과 부하를 줄임(해결 안됨 but Consul 내부 문제임을 파악함)
- 디버그 로그와 운영 체제 메트릭을 통해 Consul 내부에서 경합이 발생함을 발견함(첫 번째 이슈를 간략하게 파악)
- 128 코어의 신규 장비를 64 코어로 다시 복구함(해결 안됨 but 경합 악화를 막아줌)
- Consul 서버 분석 결과, 신규 스트리밍 기능에서 경합의 증거를 발견(첫 번째 이슈를 세부적으로 파악)
- 모든 Consul 시스템에서 스트리밍 기능을 비활성화(1차 해결 완료)
- 일부 노드에서만 리더의 쓰기 지연 문제가 계속해서 발생함(두 번째 이슈는 재현중)
- 문제가 생긴 노드는 리더로 선출되지 않도록 조치함(두 번째 이슈도 해결 완료)
- 캐시 서비스 복구 후에, 트래픽을 제어하여 사용자들이 서서히 게임에 접속할 수 있도록 서비스 가동(해결 완료)
- 정상화 후에 Consul이 사용중인 BoltDB에 문제가 있음을 확인함(두 번째 이슈를 세부적으로 파악)
참고 자료
'나의 공부방' 카테고리의 다른 글
| [Slack] JIRA 티켓 생성 워크플로우(Workflow) 만들기 (2) | 2023.11.07 |
|---|---|
| [개발서적] 프로그래머의 뇌 핵심 내용 정리 및 요약 (9) | 2023.10.31 |
| [Post Mortem] 데이터독 장애 포스트모템(2023-03-08 Incident: Infrastructure connectivity issue affecting multiple regions) (0) | 2023.09.05 |
| [디자인패턴] 서킷 브레이커 패턴(Circuit Breaker Pattern)의 필요성 및 동작 원리 (8) | 2023.03.14 |
| [개발서적] 클린 아키텍처 6부 세부사항 - 내용 정리 및 요약 (2) | 2022.11.04 |
