
티스토리 뷰
1. 코딩 중 겪는 혼란에 대한 이해
[ 세가지 종류의 혼란 ]
- 지식의 부족으로 인한 혼란
- 정보의 부족으로 인한 혼란
- 처리 능력의 부족으로 인한 혼란
지식의 부족으로 인한 혼란
아래는 APL으로 작성된 코드이다. 이 코드가 혼란스러운 이유는 T의 의미를 모르기 때문이다.
즉, T에 대한 지식이 없기 때문이다.
2 2 2 2 2 T n
정보의 부족으로 인한 혼란
아래는 Java로 작성된 코드이다. 여기서 혼란의 원인은 메서드에 대한 정보가 부족하다는 점이다.
toBinaryString() 메서드의 동작 원리에 대한 정보를 얻으려면 메서드의 내부 코드를 따로 살펴봐야 한다.
public class BinaryCalculator {
public static void main(Integer n) {
System.out.println(Integer.toBinaryString(n));
}
}
처리 능력의 부족으로 인한 혼란
아래는 Basic으로 작성된 코드이다. 이 혼란은 처리 능력의 부족 때문이다.
변수에 임시로 저장되는 값을 모두 다 기억하거나, 각각의 경우 어떤 동작들이 수행되는지를 동시에 알기가 쉽지 않다. 따라서 변수들이 중간에 어떤 값을 갖는지 종이에 따로 적거나 아니면 코드 옆에 적어놔야 한다.
LET N2 = ABS(INT(N)) // 7
LET B$ = ""
FOR N1 = N2 TO 0 STEP 0
LET N2 = INT(N1 / 2) // 3
LET B$ = STR$(N1 - N2 * 2) + B$ // 1
LET N1 = N2
NEXT N1
PRINT B$
[ 연차보다는 경험이 중요하다 ]

- 지식의 부족: 장기 기억 공간(STM)의 문제
- 정보의 부족: 단기 기억 공간(LTM)의 문제
- 처리 능력의 부족: 작업 기억 공간(Working Memory)의 문제
LTM과 프로그래밍
장기 기억 공간(LTM, Long Term Memory)에 있는 기억은 아주 오랫동안 보관된다. LTM은 오랜 시간 동안 저장한다는 점에서 컴퓨터의 하드 드라이브와 비슷하다.
우리가 어떤 일을 할 때든 LTM이 사용된다. APL 예제 코드에서 키워드 T의 의미를 알고 있다면 코드를 읽을 때 그것을 LTM으로부터 인출(retrieval)할 것이다. 여기서 언어의 문법에 대한 지식도 중요하다는 사실을 알 수 있다. APL에서 T의 의미를 알지 못하면 그 코드를 이해하기 어렵지만,0 T를 알면 코드 분석은 간단해진다.
STM과 프로그래밍
단기 기억 공간(STM, Short Term Memory)은 들어오는 정보를 임시 보관하기 위해 사용되며, 값을 일시적으로 저장하는 캐시나 메인 메모리라고 볼 수 있다. 예를 들어 키워드, 변수명, 자료구조 등이 STM에 일시적으로 저장된다.
자바 프로그램에서 n이 정수형 숫자라는 사실은 STM에 일정 기간 보관된다. STM의 크기는 최대 12개를 넘지 않는다고 한다. 두 번째 라인에 이르렀을 때는 toBinaryString()이 어떤 일을 하는지 파악했더라도, 금방 잊어버릴 수 있다. 이 함수가 하는 일을 이해하고 나면 STM은 그 내용을 기억에서 지워버린다.
이 코드를 이해하는 데 STM이 주된 역할을 하지만, LTM도 역할이 있다. LTM은 우리가 행하는 모든 인지 과정에 관여한다.
작업 기억 공간과 프로그래밍
실제 사고 작용은 작업 기억 공간(Working Memory)에서 일어난다. 생각, 아이디어, 해결책 같은 것들이 여기에서 만들어진다. 작업 기억 공간은 두뇌의 프로세서라고 볼 수 있다.
Basic 코드를 읽을 때 두뇌는 코드를 실행해보면서 무슨 일이 일어날지 이해하려고 시도하기 때문에 훨씬 더 많은 일이 일어난다. 이 과정을 트레이싱(추적)이라고 부르는데, 머릿속에서 코드를 컴파일하고 실행하는 과정을 의미한다.
2. 신속한 코드 분석
연구에 따르면 프로그래머의 시간 중 거의 60%는 코드 “작성”이 아닌 “이해”에 사용된다. 따라서 정확도를 유지하면서 코드를 빨리 이해하도록 향상한다면 프로그래밍 기술이 크게 개선되는 것이다.
[ 코드를 신속하게 읽기 ]
코드를 읽는 모든 상황의 한 가지 공통점은 그 코드에 존재하는 특정한 정보를 찾는다는 점이다.
ex) 새로운 기능을 추가할 부분, 버그가 있을 만한 곳, 특정 메서드가 어떻게 구현됐는지 등
관련 정보를 신속하게 찾는 능력을 향상하면 코드를 다시 찾아보는 횟수를 줄일 수 있다. 그러면 코드를 찾는 데 허비할 시간을 버그 수정이나 신규 기능 추가에 사용할 수 있다.
[ 생소한 코드를 읽는 것은 왜 어려운가? ]
이 코드는 의도적으로 b나 l처럼 잘 쓰지 않는 “이상한” 이름을 사용했다. 생소한 변수명을 사용하면 패턴을 찾고 기억하는 것이 어려워진다. 루프 반복 변수로 사용한 l은 특히 숫자 1과 시각적으로 혼동이 된다.
public void execute(int x[]) {
int b = x.length;
for (int v = b/2 - 1; v >= 0; v--;) {
func(x, b, v);
}
for (int l = b-1 ; l > 0 ; l--) {
int temp = x[0];
x[0] = x[l];
x[l] = temp;
func(x, l, 0);
}
}
STM의 용량에 제한이 있기 때문에 위의 코드를 기억하기 어렵다. 코드에 있는 모든 정보를 STM에 저장하고 처리하는 것은 물리적으로 불가능하다. STM은 읽거나 들은 정보를 짧은 시간만 저장하며, 보통 30초를 넘지 않는다.
STM은 정보를 저장하는 시간 뿐만 아니라 크기 또한 제약된다. 최근의 연구는 STM의 용량이 2~ 6개로 더 적다고 추정하는데, 이를 극복하기 위해 STM은 LTM과 협업함으로써 읽거나 기억한 정보를 이해한다.
[ 단위로 묶는 것의 위력 ]
실험에서 체스판에 임의로 말을 배치시키고, 일반 그룹과 체스 마스터 그룹 사람들에게 그것을 몇 초간 보여준 후 놓여 있었던 말의 위치를 기억시켰다. 그 결과 체스 마스터 그룹이 체스 말의 위치를 훨씬 더 잘 기억해냈다.
일반 그룹은 모두 말의 위치를 하나씩 기억해냈다. 예를 들어 “A7에 룩, B5에 폰, C8에 킹”과 같이 말하면서 말의 원래 위치를 복기했다. 이들은 정보를 논리적인 방식으로 묶을 수가 없었고, STM이 소진된 것이다.
반면 체스 마스터 그룹은 LTM의 지식을 많이 활용했다. 누군가는 말의 위치를 자신의 경험이나 보고 읽었던 내용과 연결시켰다. 예를 들어 “3월의 게임에서 캐슬링만 왼쪽이군” 식으로 기억하는 것이다. 이런 기억은 LTM에 존재하므로, 이전의 기억을 살려 말의 위치를 기억하면 STM은 더 적게 필요하다. 이렇듯 몇 개의 그룹으로 묶은 정보를 청크라고 부른다. 특정한 주제에 대해 두뇌가 더 많은 정보를 저장하고 있다면 입력된 정보들을 효율적으로 청크하는 것이 수월해진다.
LTM에 지식이 많으면 기억을 쉽게 한다는 사실은 프로그래밍에도 해당한다. 따라서 초보 프로그래머들은 숙련된 프로그래머들보다 훨씬 적은 줄을 처리한다. 새로운 팀원을 교육할 때나 새로운 프로그래밍 언어를 배울 때 이 점을 기억해야 한다. 심지어 다른 프로그래밍 언어를 잘 아는 뛰어난 프로그래머조차, LTM에 아직 저장되지 않은 익숙하지 않은 키워드, 구조, 도메인 개념을 이해하는 데 어려움을 겪는다.
[ 읽는 것보다 보는 것이 더 많다 ]
체스 실험을 통해 일상적이고 예상 가능한 상황은 청크로 묶는 것을 쉽게 한다는 것을 알게 되었다. 프로그래밍의 경우, 다음을 통해 읽기 쉬운 코드를 작성할 수 있다.
- 디자인 패턴의 사용
- 디자인 패턴을 사용하면 청킹 능력이 향상되고 코드를 더 빠르게 수정할 수 있음
- 주석문 쓰기
- 주석문은 코드를 이해하는 데도 도움이 되지만, 코드를 청킹하는 방식에도 영향을 미침
- “이 함수는 이진 트리를 중위 순회하며 출력한다” 같은 고수준 주석문은 코드를 청킹하는 데 도움이 됨
- 반면 “i++; i를 1만큼 증가” 같은 저수준 주석문을 넣는 것은 오히려 청킹에 부담이 됨
- 표식(beacon) 남기기
- 표식은 코드 내에서 사용하는 특정 자료구조, 알고리즘 혹은 접근 방식 등을 보여주는 라인 혹은 라인의 일부임
- 표식은 코드를 읽고 이해하는 과정에서 개발자의 가정이 옳고 그름을 확인해주는 역할을 함
- ex) 주석문에 “트리”라는 단어를 사용, root와 tree, left와 right라는 변수명 사용 등
3. 프로그래밍 문법 빠르게 배우기
[ 업무 중단이 미치는 나쁜 영향 ]
프로그래밍 언어의 문법은 검색하면 되므로 중요하지 않다고 생각하지만, 이는 다음의 이유로 바람직하지 못하다.
- 관련 내용을 미리 알고 있는 것이 코드를 효율적으로 읽고 이해하는 데 상당한 영향을 줌.
ex) 개념, 자료구조, 문법을 더 많이 알수록 두뇌는 더 많은 코드를 쉽게 분리하고 기억하고 처리할 수 있음 - 두뇌가 작업을 하다 업무 중단(interruption)을 받게 되면, 생각보다 훨씬 더 좋지 못한 결과를 초래함
검색을 위해 브라우저를 열면 이메일을 확인해보고 싶을 수도 있고, 뉴스를 읽고 싶은 마음이 들 수도 있다. 또한 관련 정보를 검색하더라도 너무 자세한 내용에 빠지게 되면 자칫 원래 목적을 잃어버릴 수도 있다.
연구에 의하면 코딩 도중 중단이 되면 다시 그 업무로 돌아가는 데 약 15분 정도 걸렸다. 메서드 수정 작업 도중 중단이 되고 나서 1분 이내에 하던 일을 다시 시작하는 경우는 10% 정도 밖에 되지 않았다. 또한 코드 작성을 하다 업무가 중단되면 그 동안 코드에 대한 중요한 정보를 잊어버린다는 것도 알 수 있었다.
따라서 문법을 기억하는 것은 중요하다.
[ 기억을 잃어버리는 이유 ]
- STM
- 기억 용량에 한계가 있음
- 한꺼번에 많은 정보를 저장할 수 없을 뿐더러 오랫동안 유지되지 않음
- LTM
- STM의 정보가 LTM으로 옮겨지는데, 추가로 연습하지 않고서는 오랫동안 기억할 수 없음
- LTM에 저장된 정보는 STM처럼 수 초 이내에 없어지지는 않지만 생각보다 빨리 지워짐
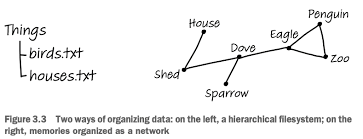
두뇌의 기억은 네트워크 구조로 연결되어 있다. 즉, 하나의 사실은 다른 많은 사실과 연결되어 있다. 서로 다른 사실과 기억이 연결되어 있다는 점을 잘 알고 있어야 한다.
[ 간격을 두고 반복하기 ]
연구에 따르면 8주의 간격을 두고 26회 반복한 경우 가장 많은 기억을 했다. 요약하자면, 오랫동안 학습한 만큼 더 오래 기억한다. 더 많은 시간을 학습해야 한다는 것이 아니라 더 오랜 간격을 두고 학습해야 한다는 것이다.
반복할 때마다 기억은 강화되고, 긴 간격을 두고 반복하면 LTM에 영구적으로 남아 있게 될 것이다. 그렇지 않으면 기억을 잃어버릴 것이다.
[ 문법을 더 오랫동안 기억하기 ]
인출(retrieval)
인출은 무언가를 일부러 기억해보려고 애쓰는 것이다.
- 저장(storage) 강도
- 무언가를 LTM에 얼마나 잘 저장하고 있는가를 나타냄
- 어떤 것을 더 많이 학습할수록 그 내용을 잊어버리는 것이 거의 불가능해질 때까지 기억은 점점 더 강해짐
- 인출(retrieval) 강도
- 무언가를 얼마나 쉽게 기억할 수 있는지를 나타냄
- 단어가 입에서 맴돌기만 하고 기억이 나지 않는다면, 저장 강도는 높지만 인출 강도는 낮음을 의미함
- 시간이 지날수록 저장 강도는 감소하지 않고 늘어나는 반면 인출 강도는 약해지는 것으로 알려짐. 자기가 이미 알고 있다고 생각하는 내용을 기억하려고 노력하면 추가 학습 없이도 인출 강도가 강화됨
특정 문법을 기억하려고 할 때 문제는 종종 저장 강도가 아닌 인출 강도에 있다. 이전에 여러 번 봤던 코드를 단지 보는 것 만으로는 나중에 기억할 수 없다. LTM 어딘가에 정보가 저장되어 있지만 그것을 가져오지 못하는 것이다.
인출을 더 쉽게 하려면 많이 연습해야 한다. 따라서 검색 이전에 먼저 그것을 능동적이고 의도적으로 기억하려고 시도해야 한다. 당장 기억이 나지 않더라도 이런 노력은 기억을 강화하고 다음번에 기억해내는 데 도움이 될 것이다.
정교화(elaboration)
정교화(elaboration)는 기존 기억에 새로운 지식을 연결시키는 것이다. 정보에 대해 능동적으로 생각하고 그것을 반추해보면서 정보에 대해 생각하는 과정을 정교화(elaboration)라고 부른다.
새로운 정보를 학습할 때 정보는 LTM에 저장하기 전에 먼저 스키마의 형태로 만들어진다. 이미 존재하는 스키마에 잘 맞는 정보일수록 더 쉽게 기억할 수 있다.
예를 들어 5, 12, 91, 54, 102 중에서 3개의 숫자를 기억하라고 하면, 연결 고리가 없기 때문에 외우기가 어렵다. 이 숫자들은 “특정 목적을 위해 기억해야 할 숫자들”과 같은 새로운 스키마에 저장될 것이다. 반면 1, 3, 15, 127, 63, 31은 이진수로 표현하면 모두 1로 이루어졌기 때문에 기억하기 더 쉽다. 이 숫자들을 기억하는 것은 나름 의미가 있기 때문에, 더 쉽게 기억할 수 있을 뿐만 아니라 기억하는 데 동기부여도 더 많이 된다.
우리의 기억은 서로 연결되어 있을 때 관련 기억을 찾는 것이 더 쉽다. 즉 인출 강도는 다른 기억에 연관된 기억일 때 더 높다. 따라서 기억하고자 하는 내용을 기존 기억과 연관 지으면서 생각하는 정교화를 통해 기존의 스키마에 맞춰서 새로운 기억을 저장할 수 있다. 정교화 작업을 통해 연관된 기억의 네트워크가 강화되고 새로운 기억이 들어왔을 때 그것과 연관된 기억이 많을수록 기억을 인출하기에 용이해진다.
4. 복잡한 코드를 읽는 방법
[ 프로그래밍과 관련한 인지 부하의 종류 ]
- 내재적 부하
- 문제 그 자체가 갖는 특성때문에 발생하는 인지 부하
- ex) 직각삼각형의 빗변의 길이를 계산하는 경우, 피타고라스의 정리를 알아야만 함
- 외재적 부하
- 내재적인 부하에 더해지는 부하로, 외부적 요인에 의해 문제에 추가되는 부하
- 특정 개념을 많이 경험할수록 부하가 적어짐
- ex) a, b인 직각 삼각형의 빗변을 구하는데, a=6, b=8임을 응용해서 빗변을 구해야 함
- 본유적 부하
- 생각을 LTM에 저장하는 과정에서 일어나는 부하
[ 인지 부하를 줄이기 위한 기업 ]
- 리팩터링
- 가독성이 높은 코드를 작성하도록 리팩터링하는 것(인지적 리팩터링, cognitive refactoring)
- 자신이 코드를 이해하는 게 목적이므로 이해하고 나면 코드를 원래의 상태로 되돌릴 수도 있음
- 생소한 언어 구성 요소를 다른 것으로 대치하기
- 코드에 있는 프로그래밍 개념이 익숙하지 않다면 지식의 부족 문제를 겪을수 있음
- 이때 코드를 좀 더 친숙한 형태로 바꿔서 이해하여 부하가 늘어나지 않게 함
- 상태표
- 코드에서 수행하는 복잡한 계산 로직이 있다면 상태표(state table)도 도움이 됨
- 상태표는 코드의 구조보다 변수의 값에 중점을 둠
- 의존성 그래프
- 흐름을 이해하고 논리적 흐름에 따라 코드를 읽는 데 도움이 됨
5. 코드를 더 깊이 있게 이해하기
[ 텍스트를 읽는 것과 코드를 읽는 것은 유사하다 ]
실험에서 특정 코드의 변수명을 이해하기 어렵게 변경했을 때 참여자들은 코드의 다른 요소들을 읽고 거기서 의미를 유추해내려고 노력했는데, 이것은 텍스트를 읽을 때 하는 일이다.
그래서 어떤 능력이 프로그래밍 능력과 관련 있는지 실험을 했는데, 계산 능력, 즉 수학적 능력은 큰 연관이 없었다. 오히려 언어 능력이 더 연관있었으며, 특히 작업 기억 공간 용량과 추론 능력이 프로그래밍 능력과 상관 관계가 높았다. 언어 능력은 특히 얼마나 빨리 프로그래밍 언어를 배울 수 있는지를 잘 예측했다.
이 연구 결과는 예상치 못한 결과일 수 있다. 컴퓨터 과학은 STEM(과학, 기술, 엔지니어링, 수학)의 한 분야로 분류되고 있고, 개발자 세계에서는 수학 능력이 유용하거나 심지어 반드시 필요한 것으로 간주된다. 하지만 이 연구를 통해 발견한 새로운 사실로 인해 프로그래밍 능력에 대한 우리의 생각을 바꿔야 할지도 모르겠다.
[ 프로그래머는 코드를 읽을 때 스캔을 먼저 한다텍 ]
텍스트를 훑는 동시에 함께 실린 그림을 보는 것은 텍스트 이해 전략(text comprehension strategy)이다. 이런 전략은 학교에서 활발히 가르치고 있고 연습도 많이 하기 때문에, 이미 자동으로 사용되고 있다.
연구팀은 프로그래머들이 코드를 전체적으로 파악하기 위해 먼저 코드를 스캔하며, 코드를 검토하는 데 사용한 시간의 처음 30%동안 코드의 70%를 훑어본다는 것을 발견했다. 이런 유형의 빠른 스캔은 자연어로 된 텍스트의 구조를 전체적으로 파악할 때 흔히 일어나며, 코드를 읽을 때도 이런 방식을 적용하는 것으로 보인다.
[ 초급 프로그래머와 숙련된 프로그래머는 코드를 읽는 방식이 다르다 ]
초보자 그룹은 숙련자 그룹보다 순차적으로 읽거나 콜 스택을 따라 읽는 경우가 더 많았다. 당연한 말이지만 콜 스택을 좇아 코드를 읽는 법은 경험을 쌓아가면서 배우게 되는 것이다.
6. 코딩 문제 해결을 더 잘하려면
[ 정신 모델(Mental Model) ]
문제에 대해 생각할 때 두뇌의 내부에서 만들어진 모델을 정신 모델(mental model)이라고 한다. 정신 모델은 풀어야 할 문제에 대해 추론하기 위해 사용할 수 있는 작업 기억 공간 내의 추상화다. 우리는 컴퓨터와 상호작용할 때 많은 종류의 정신 모델을 만든다. 예를 들어 우리는 파일 시스템에서 한 폴더 안에 있는 파일들을 생각할 것이다. 하지만 실제로는 하드 드라이브에 폴더나 파일이 실제로 있는 것이 아니며 0과 1만 갖고 있을 뿐이다. 하지만 이 0과 1에 대해 생각할 때 그러한 구조로 조직되어 있다고 생각하는 것이다.
[ 개념적 기계(Notional Machine) ]
정신 모델은 세상의 모든 것의 모델이 될 수 있지만, 개념적 기계는 컴퓨터가 코드를 실행하는 방법에 대해 추론할 때 사용하는 모델이다. 개념적 기계는 불완전할지는 몰라도 컴퓨터가 작동하는 방식을 설명 혹은 추론하는 것이다. 따라서 잘못되거나 일관되지 않을 수 있는 정신 모델과 다르다.
우리가 컴퓨터의 작동 방식을 생각할 때, 모든 세부 사항에 관심이 있지 않다. 예를 들어 변수 x가 12라는 값을 가질 때 값이 저장된 메모리 주소와 이 주소를 변수에 연결하는 포인터 같은 것에는 관심을 두지 않는다. x를 어딘가에 존재하는, 현재 값을 가진 개체 정도로 생각하면 충분하다.
7. 생각의 버그
[ 왜 두 번째 프로그래밍 언어가 첫 번째보다 쉬울까? ]
LTM에 저장된 키워드 및 정신 모델이 코드를 이해하는 데 도움이 된다는 것을 앞서 배웠다. 때때로 무언가를 배울 때, 이미 배운 지식은 다른 영역에서도 유용한데, 이것을 전이(transfer)라고 부른다.
[ 이미 알고 있다는 것은 저주인가 축복인가? ]
- 긍정적 전이(positive transfer)
- 무언가를 알고 있어 새로운 것을 배우거나 새로운 작업을 할 때 도움이 되는 전이
- 부정적 전이(negative transfer)
- 기존 지식이 새로운 것을 배우는 데 방해가 되는 전이
- 코드에 대한 잘못된 가정으로 실수가 발생할 수 있음
[ 전이의 어려움 ]
상황이 서로 비슷해야 전이 가능성이 높아진다. 지식이 한 영역에서 원래 영역과는 유사하지 않은 다른 영역으로 전이되는 원거리 전이는 우발적으로 일어날 가능성이 낮다.
즉 많은 사람들은 체스 지식이 논리적인 추론 기술과 기억력뿐만 아니라 일반 지능을 높여줄 것이라고 믿지만, 과학적인 연구들은 이를 뒷받침할 수 없었다. 체스 기술은 다른 논리적인 게임으로도 전이되지 않는 것으로 보인다.
많은 프로그래머는 프로그래밍을 배움으로써 논리적인 추론 기술을 얻거나 심지어 일반적인 지능을 증가시킬 것이라고 주장한다. 그러나 연구 대부분이 프로그래밍 교육의 효과가 거의 없음을 보여준다.
여기서 중요한 점은 하나의 프로그래밍 언어를 숙달했다는 사실이 새로운 언어를 배우는 데 항상 도움이 되는 것은 아니라는 것이다. 이미 자신을 전문가로 생각하고 초보자의 학습 활동이 자신에게는 불필요하다고 느끼는 사람들에게는 예상 못한 결과일 수 있다. 이와 관련하여 고려해야 할 조언은 사고방식을 확장하기 위해 새로운 언어를 배우기 시작했다면 이미 습득한 언어와는 근본적으로 다른 언어를 선택하는 것이 중요하다는 것이다.
[ 오개념: 생각의 버그 ]
오개념은 강한 확신 속에 있는 잘못된 사고방식이다. 오개념은 너무 강한 확신 때문에 교정하기 어려울 수 있다. 종종 오류를 지적하는 것만으로는 충분하지 않고, 새롭게 이해해야 할 수 있다.
이미 알고 있는 프로그래밍 언어 때문에 생긴 오개념을 현재 학습 중인 새로운 언어에 맞는 정신 모델로 대체하는 과정을 개념 변화(conceptual change)라고 한다. 기존의 개념은 근본적으로 바뀌거나 대체되거나 새로운 지식에 동화된다. 기존의 스키마에 새로운 지식을 추구하는 대신 지식 자체를 바꾸는 것이 다른 유형의 학습과 고별되는 점이다.
이미 학습한 지식을 LTM에서 변경해야 하기 때문에 개념 변화 학습은 일반적인 학습보다 더 어렵다. 따라서 오개념이 쉽게 사라지지 않고 오랫동안 지속된다. 그러므로 새로운 프로그래밍 언어를 배울 때는 이전 프로그래밍 언어에 대한 기존의 지식을 떨쳐내기 위해 많은 에너지를 소비해야 한다.
[ 새로운 프로그래밍 언어를 배울 때 오개념 방지하기 ]
새로운 프로그래밍 언어나 시스템을 배울 때, 부정적 전이를 피할 수는 없지만 도움이 될 몇 가지 방법들이 있다.
- 자신이 틀릴 수도 있음을 아는 것이 중요하다. 열린 마음을 유지하는 것이 핵심이다.
- 흔하게 발생하는 오개념에 대해 의도적으로 연구한다.
- 동일한 프로그래밍 언어를 같은 순서로 학습한 다른 프로그래머들에게 조언을 구한다.
8. 명명을 잘하는 방법
[ 명명이 중요한 이유 ]
- 이름은 우리가 읽을 코드의 상당 부분을 차지한다.
- 코드 리뷰 4전 중 1건은 이름에 대한 언급을 포함한다.
- 이름은 문서화의 가장 쉬운 형태이다.
- 이름은 코드를 이해하는 데 도움이 되는 중요한 표식이다.
[ 초기 명명 관행은 지속적인 영향을 미친다 ]
단일 프로젝트에서는 시간이 지난다고 해서 명명 규약이 개선되지 않는다는 것을 발견했다. 여기서 “프로그램 개발 초기에 만들어진 식별자의 품질이 계속 유지된다.”는 결론을 도출했다,
따라서 새 프로젝트를 시작할 때는, 초기 단계에서 이름을 만드는 방식이 그 이후로도 계속 사용될 가능성이 높기 때문에 좋은 이름을 선택하는 데 주의를 기울여야 한다. 왜냐하면 기준 코드를 보고 수정하거나 추가하기 때문이다.
[ 명명의 인지적 측면 ]
형식이 있는 이름은 STM을 돕는다
변수 명명에 명확한 규칙이 있다면 STM이 코드에 있는 이름을 이해하는 데 도움이 될 수 있다. 그 이유는 이런 방식이 청킹에 도움이 될 수 있기 때문이다. 모든 이름의 형식이 다르면 각 이름의 의미를 찾기 위해 많은 노력을 기울여야 한다. 또한 비슷한 이름들은 관련 정보가 매번 같은 방식으로 젯되기 때문에 이름을 읽는 동안 인지 부하가 낮아질 수 있다.
명확한 이름이 LTM에 도움이 된다
코드를 읽을 때 먼저 변수 이름은 감각 기억에 의해 처리되고 STM으로 전송된다. STM은 크기가 제한되어 있기 때문에 변수 이름을 단어별로 구분하려고 한다. nmcntrlst와 같은 이름은 구성 요소를 찾고 이해하는 데 상당한 노력이 필요할 수 있지만, name_counter_list(이름, 카운터, 리스트)와 같은 이름은 필요한 정신적인 노력이 아주 작다. 이를 통해 LTM에 정보를 전달할 때 도움이 된다.
변수 이름은 이해에 도움이 되는 다양한 유형의 정보를 포함할 수 있다
- 코드의 도메인에 대해 생각할 때 이름이 도움이 된다: customer와 같은 도메인 단어에 대해 LTM에는 모든 종류의 연관 관계가 저장되어 있다. 예를 들어 고객은 제품을 구매할 것이라든지 이름과 주소가 필요하다든지 하는 정보들이다.
- 프로그래밍에 대해 생각할 대도 이름이 도움이 된다: 트리와 같은 프로그래밍 개념도 LTM에서 정보를 가져오는 데 일조한다. 트리는 루트 노드가 있고, 순회가 가능하고, 순회하면서 방문한 노드를 순서대로 나열할 수도 있다.
- 경우에 따라 변수에 LTM이 이미 알고 있는 규약에 대한 정보가 포함될 수도 있다. 예를 들어 j라는 변수는 j를 안쪽 루프의 카운터로 사용하는 중첩된 루프를 생각나게 한다.
나쁜 이름을 가진 코드에 버그가 더 많다
실험에 따르면 나쁜 이름을 가진 코드에 버그가 더 많았다.
[ 어떤 종류의 이름이 더 이해하기 쉬운가? ]
축약할 것인가, 하지 않을 것인가?
실험에 따르면 식별자가 단어인 프로그램을 읽을 때 글자나 약어에 비해 분당 19% 더 많은 결함을 발견했다. 다른 연구를 통해서도 단어로 이루어진 변수가 코드 이해에 도움이 된다는 것이 확인됐다 하지만 변수 이름이 길수록 기억하기 어렵고, 기억하는 데 더 많은 시간이 걸린다는 단점도 발견됐다. 변수이름을 기억하기 어렵게 만드는 것은 길이 자체가 아니라 이름에 포함된 음절의 수였다. 인지적인 관점에서 각 음절 별로 청크가 만들어지기 때문이다.
따라서 코드를 이해하고 버그를 쉽게 찾기 위해서라면 명확한 의미의 단어를 사용해야 하는 반면, 기억을 잘하기 위해서라면 간결한 약자를 사용해야 한다. 좋은 변수 이름을 명명하기 위해서는 이 둘 사이의 주의 깊은 균형이 필요하다.
스네이크 케이스냐, 캐멀 케이스냐?
연구 결과 캐멀 케이스가 프로그래머와 비프로그래머 모두에게 더 높은 정확도를 가졌다. 식별자 이름이 캐멀 케이스로 작성되었을 때 올바른 옵션을 선택할 확률이 51.5% 더 높았다. 그러나 답을 선택하는 데 들어간 시간 역시 더 걸렸다. 참가자들이 캐멀 케이스로 적힌 식별자를 찾는 데 0.5초가 더 걸렸다.
9. 나쁜 코드와 인지 부하를 방지하는 두 가지 프레임워크
[ 코드 스멜에 대한 개략적 소개 ]
코드 스멜이 있다고 해서 코드에 반드시 오류가 있는 것은 아니지만, 오류가 있을 가능성이 높은 것으로 알려져 있다. 또한 코드 스멜이 없는 코드보다 코드 스멜이 포함된 코드는 향후에 변경될 가능성이 더 높았다.
- 메서드 수준 코드 스멜
- 한 메서드가 많은 라인으로 되어 있고 많은 기능을 갖는 경우 또는 매개변수가 많은 경우 등
- 클래스 수준 코드 스멜
- 큰 클래스 또는 메서드와 필드가 너무 적은 클래스 등
- 코드베이스 수준 코드 스멜
- 매우 유사한 코드가 중복되는 코드 또는 메서드들이 서로 정보를 계속해서 전달하는 경우 등
[ 코드 스멜이 인지 과정에 악영향을 미치는 방식 ]
- 긴 매개변수 목록과 복잡한 스위치 문: 작업 기억 공간의 용량 초과
- 신의 클래스, 긴 메서드: 효율적인 청킹 불가능
- 유사한 코드: 청킹이 잘못됨(유사하지만 조금 다른 코드를 동일하다고 잘못 청킹할 수 있음)
[ 언어적 안티 패턴 ]
코드 스멜은 구조적 안티패턴 문제가 있는 코드로, 코드가 잘 작성되었으나 파악하기 어려운 구조임을 의미한다.
개념적 안티패턴은 짧은 메서드와 깔끔한 클래스로 올바르게 구성되어 있지만 혼동되는 이름을 갖는 경우다.
언어적 안티패턴은 코드의 언어적 요소와 그 역할 사이의 불일치에 해당한다. 언어적 요소란 메서드 입출력 정의, 설명 문서, 속성 이름, 데이터 타입, 주석 등을 포함하는 코드의 자연어 부분이다. 간단한 예로 initial_element라는 변수가 원소가 아닌 인덱스를 갖거나 isValid가 정수를 반환하는 등의 경우다.
이러한 언어적 안티패턴은 우리 두뇌에 혼란을 초래해 인지 부하를 높일 수 있다.
[ 언어적 안티 패턴이 혼란을 일으키는 이유 ]
- 자신이 작성하지 않은 코드같이 익숙하지 않은 내용을 읽을 때, LTM은 관련 사실과 경험을 검색한다. 이때 충돌되는 이름을 읽게 되면 잘못된 정보가 주어질 수 있다.
- 잘못된 청킹이 발생할 수 있다. isValid 같은 변수를 보면 불리언 변수라고 가정하고 두뇌는 에너지를 절약하려고 노력하는데, 사실이 아닐 경우 잘못된 가정이 오래 지속될 수 있다.
10. 복잡한 문제 해결을 더 잘하려면
[ 프로그래밍 문제를 해결할 때 LTM의 역할은 무엇인가? ]
- 문제 해결 시 LTM이 사용됨
- 우리가 설계할 수 있는 해결책은 사전 지식을 필요로 함
- 예를 들어 자바로 알고리즘을 푼다면 자바 API에 대해 알아야 함
- 두뇌는 익숙한 문제를 해결하는 것이 더 쉬움
- 뇌는 문제 해결 시에 LTM으로부터 네트워크를 통해 연결된 정보(유용한 전략)를 인출함
- 따라서 LTM은 올바른 기억을 인출하기 위한 단서가 필요하며, 단서가 구체적일수록 좋음
[ 자동화: 암시적 기억 생성 ]
문제 해결 능력을 높이는 첫 번째 방법은 자동화다. 어떤 기술을 아무 생각 없이 할 수 있을 정도가 되면 자동화했다고 한다. 추론을 전혀 사용하지 않고 순간적인 기억에 전적으로 의존할 때 자동화는 완전해진다.
[ 코드와 해설에서 배우기 ]
단순히 프로그래밍을 많이 한다고 해서 문제 해결을 더 잘하게 되는 것은 아니다. 작고 간단한 기술은 의도적 연습을 통해 자율적인 수준까지 숙련할 수 있지만, 더 복잡하고 규모가 큰 문제를 해결하기에는 이것만으로 부족하다.
문제 해결 능력을 향상하기 위한 두 번째 방법은 다른 사람들이 문제를 어떻게 해결했는지 의도적으로 연구하는 것이다. 다른 사람들이 문제를 어떻게 해결했는지 연구함으로써 얻는 해결책을 종종 풀이된 예제(worked example)라고 부른다.
방정식 문제를 푸는 두 중학교 그룹 중 한 그룹에는 문제와 함께 풀이를 자세히 설명하는 풀이된 예제를 제공해주었고, 한 그룹에는 추가적인 도움을 주지 않았다. 두 그룹의 성적을 비교해보니 첫 번째 그룹이 더 잘했는데, 레시피가 있었으므로 당연할 수 있다. 하지만 놀라운 것은 풀이 속도의 차이였는데, 첫 번째 그룹이 5배나 더 빨리 풀었다. 학생들이 레시피를 기계적으로 따라 풀기 대문에 레시피를 가르치기를 주저하는 사람들에게 예상치 못한 결과일 수 있다.
“더 나은 프로그래머가 되고 싶다면, 프로그램을 많이 작성하라”와 같은 생각은 때로 사실이 아닌 것으로 보인다. 오히려 코드와 코드의 작성 과정을 연구하는 것이 도움이 될 수 있다. 이를 위한 소스는 여러 가지가 있다.
- 동료와의 협업
- 코드 분석은 누군가와 함께하는 것이 더 유용함
- 함께 코드를 읽으면서 코드와 설명을 나누고 배울 수 있음
- 깃허브 탐구
- 어느 정도 알고 있는 저장소의 코드(사용 중인 도구 등)를 읽으면 됨
- 도메인이 조금이라도 익숙한 저장소를 선택하여 낯선 단어와 개념으로 인한 외재적 부하 없이 프로그래밍 자체에 집중하기
- 소스 코드에 대한 책 또는 블로그 게시물 읽기
- 프로그래밍 문제를 해결한 방법에 대한 블로그 게시물
- 오픈 소스 소프트웨어 아키텍처, 500Lines or Less 책 등
11. 코드를 작성하는 행위
[ 프로그래머의 업무 중단 ]
프로그래밍 작업에는 일종의 워밍업 및 냉각 단계가 있다. 실험 결과에 따르면 업무가 중단된 후 코드 작성을 다시 시작하는 데 약 25분이 소요되었다. 메서드를 작성하다가 중단되면, 1분 이내에 작업을 재개할 수 있었던 경우는 10%에 불과했는데, 이는 작업 기억 공간이 원래 작업하던 코드에 대한 중요한 정보를 잃어버리기 때문이다.
주요 작업 중에 방해를 받은 그룹은 짜증과 불안이 더 많이 나타났고, 두 배나 더 많은 실수를 했다. 많은 연구에 따르면 사람들은 깊은 인지 작업을 하는 동안 여러 가지 일(멀티태스킹)을 할 수 없는데, 흥미로운 점은 멀티태스킹을 하는 사람들이 스스로를 매우 생산적이라고 느낀다는 것이다.
[ 중단에 잘 대비하는 방법 ]
- 정신 모델 저장
- 정신 모델의 일부가 코드와 별도로 저장되어 있으면 정신 모델을 빠르게 되찾을 수 있음
- 정신 모델에 대한 메모를 주석문으로 남기는 것도 도움이 됨
- 미래 기억 향상
- 미래 기억은 미래에 무언가를 할 것에 대한 기억임
- TODO를 남기는 것은 오랫동안 작업되지 않거나 해결되지 않은 채 남아 있을 수 있음
- 이를 위해 의도적인 컴파일 오류 또는 IDE의 플러그인 등을 사용할 수 있음
- 하위 목표 라벨 붙이기
- 문제를 어떤 작은 단계로 나눌 수 있는지 명시적으로 기록해둠
일부 개발자들은 코드가 “그 자체로 문서”이어야 하므로 주석은 불필요하다고 생각한다. 그러나 코드는 프로그래머의 사고 과정을 거의 설명하지 못하므로 작성자의 정신 모델을 적절하게 표현하지 못한다. 코드에 특정 접근 방식을 선택한 이유, 코드의 목표 또는 구현을 위해 고려한 다른 대안 등을 기록하지 않는다면 암묵적으로 발견될 수 밖에 없는데, 이것은 분명 비생산적이다.
존 오스터하우트는 A Philosophy of Software Design(소프트웨어 설계의 철학)에서 이것을 멋지게 묘사했다. “주석문의 배후에 놓인 전반적인 아이디어는, 설계자의 마음속에는 있었지만 코드로 표현할 수 없었던 정보를 포착하는 것이다.”
의사 결정을 문서화해놓으면 다른 사람이 코드를 읽을 때 매우 유용할 뿐만 아니라 자기 자신의 정신 모델을 일시적으로 저장하는 데도 도움이 되고 나중에 작업을 쉽게 재개할 수 있다. 따라서 업무가 중단될 상황에서 잠시 시간 여유가 된다면, 코드에 대한 최신 정신 모델을 주석으로 브레인 덤프(brain dump)하는 것이 아주 유용할 수 있다.
13. 새로운 개발자 팀원의 적응 지원
[ 적응 지원의 문제 ]
- 적응 지원 과정
- 선임 개발자가 새 팀원에게 너무 많은 정보를 줘서 높은 인지 부하를 유발함
ex) 팀원들, 코드베이스의 도메인, 워크플로, 코드베이스를 한꺼번에 소개함 - 이후 새 팀원에게 질문을 하거나 과제를 주는데, 대부분의 선임 개발자는 이것을 아주 간단한 일로 여김
ex) 작은 버그를 고치거나 작은 기능을 추가하는 것 - 도메인이나 프로그래밍 언어 등의 부족으로 인해 인지 부하가 높아지고 새 팀원은 적응에 어려움을 겪음
- 선임 개발자가 새 팀원에게 너무 많은 정보를 줘서 높은 인지 부하를 유발함
- 현상 및 결과
- 너무 많은 내/외재적 부하로 인해 본유적 부하(새로운 정보)를 위한 공간이 없어 기억할 수 없고, 효과적으로 프로그래밍할 수 없음
- 두뇌가 너무 많은 인지 부하를 경험하여 효과적으로 사고하는 것이 억제됨
- 팀장은 새 팀원이 똑똑하지 않다고 생각할 수 있고, 새 팀원은 프로젝트가 매우 어려울 것이라고 추측하여 모두에게 좌절감을 안겨주고, 팀워크가 잘 이루어지지 않음
- 원인
- 어떤 기술을 충분히 익히고 나면, 그 기술이나 지식을 배우는 것이 얼마나 어려웠는지 잃어버림(전문가의 저주)
- 따라서 새로운 팀원이 동시에 처리할 수 있는 새로운 작업의 수를 과대평가함
- 가장 먼저 해야할 것은 일을 배우는 사람에게는 그 과정이 그렇게 쉽지만은 않을 수 있음을 깨닫는 것
[ 적응 지원의 문제 ]
- 전문가의 뇌는 LTM에 저장된 관련 기억(학습된 지식과 일화적 경험)을 필요로 할 때마다 가져옴
- 전문가는 코드 및 코드 관련 사항(오류 메시지, 테스트, 문제, 해결책 등)을 매우 효과적으로 청킹할 수 있어서, 코드의 일부를 보고도 무엇에 대한 것인지 파악할 수 있음
[ 개념을 구체적으로 보는 것과 추상적으로 보는 것의 차이 ]
초보자가 무언가 이해하려 할 때, 의미적 파동을 따른다.

- 시작(추상적)
- 사용하는 목적이나 이유와 같은 일반적인 개념을 이해할 필요가 있음
- ex) 가변 인수 함수는 필요한 만큼의 매개변수를 사용할 수 있어서 유용함
- 포장(구체적)
- 특정 개념에 대한 세부 사항을 배울 준비가 된 상태
- ex) *가 파이썬에서 가변 인수 함수를 위해 사용되며, 리스트로 구현할 수 있음
- 재포장(추상적)
- 일반적으로 어떻게 작동하는지 이해하는 데 어려움이 없으며 관련 지식을 LTM에 통합함
- ex) C++는 가변함수를 지원함
의미적 파동을 따르지 않는 방식으로 설명하는 안티 패턴의 예시이다. 이러한 방식으로 새로운 팀원의 적응을 지원하게 되면 제대로 도움을 주지 못할 것이다.
- 추상적인 용어만 사용해 설명하여 구체적인 내용(문법 등)을 알지 못함
- 세부적인 것들만 지나치게 설명하여 제대로 이해하지 못함
- 재포장할 여지를 주지 않아 새로운 지식을 LTM에 통합하지 못함
[ 적응 지원 개선 ]
적응을 위한 작업은 탐구, 검색, 전사, 이해, 증가의 활동 중에서 하나로 제한하는 것이 좋다.
- ex) 클래스를 검색 → 해당 클래스 내의 메서드 전사 → 클래스를 변경
- ex) 새로운 프로그래밍 개념을 학습하는 작업과 도메인에 대해 배우는 작업을 번갈아 수행함
새로운 팀원의 기억을 지원하기 위한 다양한 방법이 있다. 이 과정은 공감과 인내가 필요하다.
- LTM 지원: 관련 정보 설명
- 중요한 역할을 하는 관련 정보를 숙지하고 전달함
- ex) 모든 중요한 도메인 개념 또는 외부 도구 등을 문서화함
- STM 지원: 규모가 작고 집중할 수 있는 작업 준비
- 동시에 여러 활동을 하지 않고 집중할 수 있게 단계를 나누어 진행함
- ex) 코드베이스를 알아가기 위해 코드를 설명해주고 간단한 구현을 시키는 것보다는 코드 요약만 함
- 작업 기억 공간 지원: 도표 그리기
- 코드를 벗어나 더 큰 그림을 보여주는 것
- 하지만 완전 초보자들에게는 항상 유용하지 않을 수 있음
- 코드 함께 읽기
'나의 공부방' 카테고리의 다른 글
| [개발서적] 실용주의 프로그래머 핵심 내용 정리 및 요약 (6) | 2023.11.14 |
|---|---|
| [Slack] JIRA 티켓 생성 워크플로우(Workflow) 만들기 (2) | 2023.11.07 |
| [Post Mortem] 로블록스 장애 포스트모템(Roblox Return to Service 10/28-10/31 2021) (2) | 2023.09.12 |
| [Post Mortem] 데이터독 장애 포스트모템(2023-03-08 Incident: Infrastructure connectivity issue affecting multiple regions) (0) | 2023.09.05 |
| [디자인패턴] 서킷 브레이커 패턴(Circuit Breaker Pattern)의 필요성 및 동작 원리 (8) | 2023.03.14 |
