
티스토리 뷰
[Spring] 예제 코드를 통해 스프링 @Transactional의 동작 방식에 대해 완벽하게 이해하기(parallelStream에서 @Transactional을 사용하는 경우)
망나니개발자 2023. 10. 24. 10:00
1. 스프링 @Transactional의 동작 방식에 대해 완벽하게 이해하기
[ parallelStream에서 @Transactional을 사용하는 예제 코드 ]
다음과 같은 간단한 JPA 엔티티가 있다.
@Entity
@Getter
@NoArgsConstructor
public class MyEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
private String name;
public MyEntity(String name) {
this.name = name;
}
}
그리고 해당 엔티티를 저장하는 서비스 계층에서 조건에 따라 런타임 예외를 던진다고 하자.
@Service
@Transactional(readOnly = true)
@RequiredArgsConstructor
@Slf4j
public class MyEntityService {
private final MyEntityRepository myEntityRepository;
private final DataSource dataSource;
private static final AtomicInteger atomic = new AtomicInteger(0);
@Transactional
public void add(MyEntity myEntity) {
myEntityRepository.save(myEntity);
if (atomic.addAndGet(1) % 2 == 0) {
log.error("thread:{}, connection:{}", Thread.currentThread().getName(), DataSourceUtils.getConnection(dataSource));
throw new RuntimeException();
}
}
}
아래의 클래스는 parallelStream을 사용해 5개의 MyEntity를 병렬적으로 저장하고 있다. 5번 실행하기 때문에 MyEntityService에서는 예외(2회)가 발생할 것이다. 해당 메소드 호출 후에 저장된 데이터를 확인해보도록 하자.
@Service
@RequiredArgsConstructor
@Transactional(readOnly = true)
public class MyParallelService {
private final MyEntityService myEntityService;
@Transactional
public void addParallel() {
List.of("Hello", "my", "name", "is", "MangKyu")
.parallelStream()
.map(MyEntity::new)
.forEach(v -> myEntityService.add(v));
}
}
데이터를 확인해보면 트랜잭션이 일관되게 롤백되지 않고, 일부 데이터가 남아있는 것을 확인할 수 있다. MyParallelService의 addParallel에서 @Transactional을 통해 트랜잭션을 시작했기 때문에 예외가 발생했다면 모든 데이터가 함께 롤백되기를 기대했지만 일부 데이터는 롤백되지 않있는데, 왜 이런 상황이 생겼는지 알아보도록 하자.

[ 원인 분석, 스프링 @Transactional의 동작 방식 ]
여기서 모든 데이터가 롤백되지 않은 이유는 스프링이 제공하는 @Transactional의 동작 방식에 있다.
먼저 기본적인 로직 흐름을 정리하면 다음과 같다.
- MyParallelService에서 트랜잭션이 처리됨(시작된 트랜잭션이 있으면 참여하고, 없으면 새롭게 생성)
- MyParallelService의 addParallel()이 호출되고, parallelStream을 통해 병렬적으로 MyEntityService가 5회 호출됨
- MyEntityService에서 트랜잭션이 처리됨
- MyEntityService의 add()에서 확률적으로 런타임 예외가 발생함
- 런타임 예외가 발생했다면 롤백됨
기본적으로 데이터베이스는 자동 커밋(auto commit)을 사용한다. 데이터베이스에 하나의 쿼리가 전달될 때마다 자등으로 커밋되고, 실제 데이터베이스에 반영된다. 하지만 하나의 작업이 여러 개의 쿼리로 구성되는 경우에는 자동 커밋 모드를 사용하면 안된다. 따라서 논리적인 하나의 작업을 위해 데이터베이스는 트랜잭션을 지원한다.
스프링의 @Transactional은 AOP (관점 지향 프로그래밍, Aspect-Oriented Programming) 기반으로 트랜잭션을 적용할 수 있게 도와준다. @Transactional을 붙이면 내부적으로 커넥션을 가져와서 자동 커밋 모드를 비활성화하고 트랜잭션을 시작한다. 그리고 해당 커넥션을 한 스레드에서 공유할 수 있도록 스레드 로컬(Thread Local) 변수에 저장하는 트랜잭션 동기화(Transaction Synchronization)를 진행한다.
이를 통해 MyEntityService에서 처리되는 작업은 MyParallelService의 작업과 하나의 트랜잭션으로 이어진다.
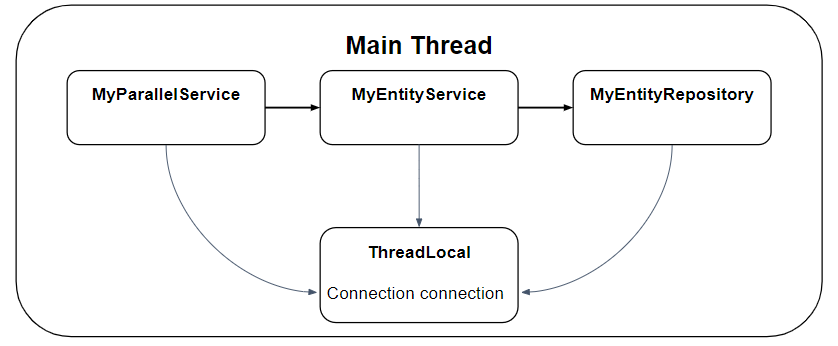
이러한 스프링의 트랜잭션 처리 방식은 단일 스레드 내에서만 유효한 스레드 로컬을 사용하기 때문에 parallelStream처럼 여러 스레드에서 나누어 처리되는 코드에서 문제가 발생할 수 있다.
parallelStream은 내부적으로 ForkJoinPool을 사용해 여러 개의 스레드를 통해 병렬적으로 작업을 실행시킨다. 즉, 하나의 MainThread에서 시작된 작업은 다음과 같이 ForkJoinPool의 4개 스레드에 나누어 처리되는 것이다.

하지만 ThreadLocal은 스레드 별로 할당되는 공간이므로 ForkJoinPool 스레드의 ThreadLocal에는 커넥션이 존재하지 않는다. 따라서 MyEntityService는 @Transactional을 통해 새로운 커넥션을 가져와서 새롭게 트랜잭션을 시작한다.
즉, 5개의 스레드에서 처리되는 작업은 서로 다른 트랜잭션에서 실행되는 독립적인 작업이므로 하나의 작업이 아니며, 예외가 발생해도 각각의 단일 작업만 롤백되고, 전체 데이터가 롤백되지 않는 것이다.
전체 데이터가 롤백되지 않는 것보다 더 심각한 문제는 각각의 스레드에서 새롭게 데이터베이스 커넥션을 획득하려고 시도한다는 것이다. 위의 로직은 1개의 요청임에도 불구하고 5개의 커넥션이 사용된다. 이는 커넥션 풀의 커넥션이 빠르게 고갈되어, 다른 요청들이 커넥션을 획득하기 위해 대기하면서 처리가 지연되는 등의 문제를 일으킬 수 있다.
따라서 @Transasctional의 동작 방식에 대해 정확하게 이해하고, 이러한 부분들에 주의해서 사용할 필요가 있다.
