
티스토리 뷰
1. Transaction(트랜잭션)에 대한 이해
[ 트랜잭션(Transaction)의 필요성 ]
만약 데이터베이스의 데이터를 수정하는 도중에 예외가 발생된다면 어떻게 해야 할까? DB의 데이터들은 수정이 되기 전의 상태로 다시 되돌아가져야 하고, 다시 수정 작업이 진행되어야 할 것이다.
이렇듯 여러 작업을 진행하다가 문제가 생겼을 경우 이전 상태로 롤백하기 위해 사용되는 것이 트랜잭션(Transaction) 이다.
트랜잭션은 더 이상 쪼갤 수 없는 최소 작업 단위를 의미한다. 그래서 트랜잭션은 commit으로 성공 하거나 rollback으로 실패 이후 취소되어야 한다. 하지만 모든 트랜잭션이 동일한 것은 아니고 속성에 따라 동작 방식을 다르게 해줄 수 있다.
예를 들어 1개의 새로운 데이터를 추가하는 와중에 에러가 발생하면 해당 추가 작업은 없었던 것처럼 되돌려진다. 하지만 만약 여러 개의 작업에 대해 롤백을 하려면 어떻게 해야 될까? 여러 개의 작업을 1개의 트랜잭션으로 관리해야 할 것이다.
위에서 설명한 것과 마찬가지로 트랜잭션의 마무리 작업으로는 크게 2가지가 있다.
- 트랜잭션 커밋: 작업이 마무리 됨
- 트랜잭션 롤백: 작업을 취소하고 이전의 상태로 돌림
만약 여러 작업이 모두 마무리 되었다면 트랜잭션 커밋을 통해 작업이 마무리되었음을 알려주어 반영해야 하며, 만약 문제가 생겼다면 작업 취소를 위해 트랜잭션 롤백 처리를 해주어야 한다.
2. Spring이 제공하는 Transaction(트랜잭션) 핵심 기술
Spring은 트랜잭션과 관련된 3가지 핵심 기술을 제공하고 있다. 그 3가지 핵심 기술은 다음과 같다.
- 트랜잭션(Transaction) 동기화
- 트랜잭션(Transaction) 추상화
- AOP를 이용한 트랜잭션(Transaction) 분리
[ 1. 트랜잭션(Transaction) 동기화 ]
JDBC를 이용하는 개발자가 직접 여러 개의 작업을 하나의 트랜잭션으로 관리하려면 Connection 객체를 공유하는 등 상당히 불필요한 작업들이 많이 생길 것이다.
Spring은 이러한 문제를 해결하고자 트랜잭션 동기화(Transaction Synchronization) 기술을 제공하고 있다. 트랜잭션 동기화는 트랜잭션을 시작하기 위한 Connection 객체를 특별한 저장소에 보관해두고 필요할 때 꺼내쓸 수 있도록 하는 기술이다.
트랜잭션 동기화 저장소는 작업 쓰레드마다 Connection 객체를 독립적으로 관리하기 때문에, 멀티쓰레드 환경에서도 충돌이 발생할 여지가 없다. 그래서 다음과 같이 트랜잭션 동기화를 적용하게 된다.
// 동기화 시작
TransactionSynchronizeManager.initSynchronization();
Connection c = DataSourceUtils.getConnection(dataSource);
// 작업 진행
// 동기화 종료
DataSourceUtils.releaseConnection(c, dataSource);
TransactionSynchronizeManager.unbindResource(dataSource);
TransactionSynchronizeManager.clearSynchronization();
하지만 개발자가 JDBC가 아닌 Hibernate와 같은 기술을 쓴다면 위의 JDBC 종속적인 트랜잭션 동기화 코드들은 문제를 유발하게 된다. 대표적으로 Hibernate에서는 Connection이 아닌 Session이라는 객체를 사용하기 때문이다. 이러한 기술 종속적인 문제를 해결하기 위해 Spring은 트랜잭션 관리 부분을 추상화한 기술을 제공하고 있다.
[ 2. 트랜잭션(Transaction) 추상화 ]
Spring은 트랜잭션 기술의 공통점을 담은 트랜잭션 추상화 기술을 제공하고 있다. 이를 이용함으로써 애플리케이션에 각 기술마다(JDBC, JPA, Hibernate 등) 종속적인 코드를 이용하지 않고도 일관되게 트랜잭션을 처리할 수 있도록 해주고 있다.
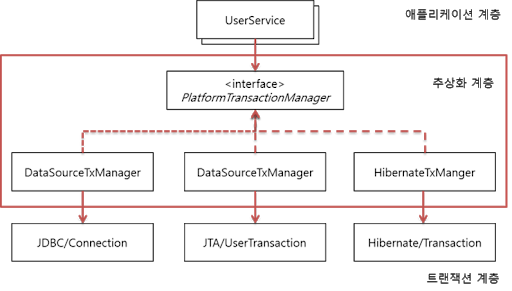
Spring이 제공하는 트랜잭션 경계 설정을 위한 추상 인터페이스는 PlatformTransactionManager 이다. 예를 들어 만약 JDBC의 로컬 트랜잭션을 이용한다면 DataSourceTxManager를 이용하면 된다.
이제 우리는 사용하는 기술과 무관하게 PlatformTransactionManager를 통해 다음의 코드와 같이 트랜잭션을 공유하고, 커밋하고, 롤백할 수 있게 되었다.
public Object invoke(MethodInvoation invoation) throws Throwable {
TransactionStatus status = this.transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
Object ret = invoation.proceed();
this.transactionManager.commit(status);
return ret;
} catch (Exception e) {
this.transactionManager.rollback(status);
throw e;
}
}
하지만 위와 같은 트랜잭션 관리 코드들이 비지니스 로직 코드와 결합되어 2가지 책임을 갖고 있다. Spring에서는 AOP를 이용해 이러한 트랜잭션 부분을 핵심 비지니스 로직과 분리하였다.
[ 3. AOP를 이용한 트랜잭션(Transaction) 분리 ]
예를 들어 다음과 같이 트랜잭션 코드와 비지니스 로직 코드가 복잡하게 얽혀있는 코드가 있다고 하자.
public void addUsers(List<User> userList) {
TransactionStatus status = this.transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
for (User user: userList) {
if(isEmailNotDuplicated(user.getEmail())){
userRepository.save(user);
}
}
this.transactionManager.commit(status);
} catch (Exception e) {
this.transactionManager.rollback(status);
throw e
}
}
위의 코드는 여러 책임을 가질 뿐만 아니라 서로 성격도 다르고 주고받는 것도 없으므로 분리하는 것이 적합하다.
하지만 위의 코드를 어떻게 분리할 것인지에 대한 고민을 해야 한다. 흔히 떠올릴 수 있는 방법으로는 내부 메소드로 추출하거나 DI로 합성을 이용해 해결하거나 상속을 이용할 수 있을 것이다.
하지만 위의 어떠한 방법을 이용하여도 트랜잭션을 담당하는 기술 코드를 완전히 분리시키는 것이 불가능하였다. 그래서 Spring에서는 마치 트랜잭션 코드와 같은 부가 기능 코드가 존재하지 않는 것 처럼 보이기 위해 해당 로직을 클래스 밖으로 빼내서 별도의 모듈로 만드는 AOP(Aspect Oriented Programming, 관점 지향 프로그래밍)를 고안 및 적용하게 되었고, 이를 적용한 트랜잭션 어노테이션(@Transactional)을 지원하게 되었다. 이를 적용하면 위와 같은 코드를 핵심 비지니스 로직만 다음과 같이 남길 수 있다.
@Service
@RequiredArgsConstructor
@Transactional
public class UserService {
private final UserRepository userRepository;
public void addUsers(List<User> userList) {
for (User user : userList) {
if (isEmailNotDuplicated(user.getEmail())) {
userRepository.save(user);
}
}
}
}
[ Spring 트랜잭션의 세부 설정 ]
Spring의 DefaultTransactionDefinition이 구현하고 있는 TransactionDefinition 인터페이스는 트랜잭션의 동작방식에 영향을 줄 수 있는 네 가지 속성을 정의하고 있다. 해당 4가지 속성은 트랜잭션을 세부적으로 이용할 수 있게 도와주며, @Transactional 어노테이션에도 공통적으로 적용할 수 있다.
- 트랜잭션 전파
- 격리수준
- 제한시간
- 읽기전용
트랜잭션 전파
트랜잭션 전파란 트랜잭션의 경계에서 이미 진행중인 트랜잭션이 있거나 없을 때 어떻게 동작할 것인가를 결정하는 방식을 의미한다. 예를 들어 어떤 A 작업에 대한 트랜잭션이 진행중이고 B 작업이 시작될 때 B 작업에 대한 트랜잭션을 어떻게 처리할까에 대한 부분이다.
1. A의 트랜잭션에 참여(PROPAGATION_REQUIRED)
B의 코드는 새로운 트랜잭션을 만들지 않고 A에서 진행중이 트랜잭션에 참여할 수 있다. 이 경우 B의 작업이 마무리 되고 나서, 남은 A의 작업(2)을 처리할 때 예외가 발생하면 A와 B의 작업이 모두 취소된다. 왜냐하면 A와 B의 트랜잭션이 하나로 묶여있기 때문이다.
2. 독립적인 트랜잭션 생성(PROPAGATION_REQUIRES_NEW)
반대로 B의 트랜잭션은 A의 트랜잭션과 무관하게 만들 수 있다. 이 경우 B의 트랜잭션 경계를 빠져나오는 순간 B의 트랜잭션은 독자적으로 커밋 또는 롤백되고, 이것은 A에 어떠한 영향도 주지 않는다. 즉, 이후 A가 (2)번 작업을 하면서 예외가 발생해 롤백되어도 B의 작업에는 영향을 주지 못한다.
3. 트랜잭션 없이 동작(PROPAGATION_NOT_SUPPORTED)
B의 작업에 대해 트랜잭션을 걸지 않을 수 있다. 만약 B의 작업이 단순 데이터 조회라면 굳이 트랜잭션이 필요 없을 것이다.
이렇듯 이미 진행중인 트랜잭션이 어떻게 영향을 미칠 수 있는가에 대한 부분이 트랜잭션 전파 속성이다. 트랜잭션을 시작하는 것처럼 보이는 getTransaction() 코드가 begin이 아닌 get으로 이름이 지어진 이유도 여기에 있다. 해당 트랜잭션은 다른 트랜잭션에 묶여있을 수 있기 때문이다. 위에서 설명한 대표적인 처리 방법 외에도 다양한 처리 방법을 지원하고 있다.
격리 수준
모든 DB 트랜잭션은 격리수준을 가지고 있어야 한다. 서버에서는 여러 개의 트랜잭션이 동시에 진행될 수 있는데, 모든 트랜잭션을 독립적으로 만들고 순차 진행 한다면 안전하겠지만 성능이 크게 떨어질 수 밖에 없다. 따라서 적절하게 격리수준을 조정해서 가능한 많은 트랜잭션을 동시에 진행시키면서 문제가 발생하지 않도록 제어해야 한다. 이는 JDBC 드라이버나 DataSource 등에서 재설정할 수 있고, 트랜잭션 단위로 격리 수준을 조정할 수도 있다.
DefaultTransactionDefinition에 설정된 격리수준은 ISOLATION_DEFAULT로 DataSource에 정의된 격리 수준을 따른다는 것이다.
기본적으로는 DB나 DataSource에 설정된 기본 격리 수준을 따르는 것이 좋지만, 특별한 작업을 수행하는 메소드라면 독자적으로 지정해줄 필요가 있다.
제한시간
트랜잭션을 수행하는 제한시간을 설정할 수 있다. 제한시간의 설정은 트랜잭션을 직접 시작하는 PROPAGATION_REQUIRED나 PROPAGATION_REQUIRES_NEW의 경우에 사용해야만 의미가 있다.
읽기전용
읽기전용으로 설정해두면 트랜잭션 내에서 데이터를 조작하는 시도를 막아줄 수 있을 뿐만 아니라 데이터 액세스 기술에 따라 성능이 향상될 수 있다.
위에서 트랜잭션의 세부 설정들 외에도 Spring은 다양한 세부 설정들을 제공하고 있다. 이와 관련된 자세한 내용은 다음 포스팅에서 참고할 수 있다.
관련 포스팅
- 트랜잭션에 대한 이해와 Spring이 제공하는 Transaction(트랜잭션) 핵심 기술 - (1/3)
- Spring 트랜잭션의 세부 설정(전파 속성, 격리수준, 읽기전용, 롤백/커밋 예외 등) - (2/3)
- Spring에서 트랜잭션의 사용법 - (3/3)
