
티스토리 뷰
이번에는 유지보수하기 좋은 멀티 모듈 구조를 설계하는 기준과 그에 따른 고려사항에 대해 알아보도록 하겠습니다. 아래의 내용은 절대적인 기준이 아니며, 상황에 따라 달라질 수 있음을 참고 부탁드립니다. 또한 해당 내용은 인프콘 2023에서 발표한 내용이니, 인프콘 영상을 통해서도 참고 하실 수 있습니다. 발표자료는 여기서 확인하실 수 있고, 예시로 설계된 구조는 깃허브에서 확인하실 수 있습니다.
1. 멀티 모듈 설계하기, 모듈을 나누는 기준
- 시스템에 독립적인 공통 코드 분리하기
- 서로 다른 수준(속도)의 공통 코드 분리하기
- 서로 다른 기능의 모듈 분리하기
- 서로 다른 액터의 모듈 분리하기
[ 시스템에 독립적인 공통 코드 분리하기 ]
가장 먼저 공통 코드를 분리시킬 수 있고, 공통 코드는 “시스템 종속성”을 기준으로 구분할 수 있다. 대표적으로 앱 스토어, 배달 플랫폼 등은 하나의 시스템이라고 볼 수 있다.
- 공통 코드
- 특정 시스템에 독립적인 공통 코드
- 특정 시스템에 종속적인 공통 코드
특정 시스템에 독립적인 공통 코드라 함은 StringUtils나 DateUtils처럼 다른 어떤 시스템을 개발하더라도 사용될 수 있는 코드들을 의미한다. 반면에 특정 시스템에 종속되는 공통 코드라 함은 앱 스토어를 위한 공통 데이터베이스 설정이나 앱 스토어의 앱을 나타내는 App이라는 도메인 엔티티 등이 존재할 수 있다.
특정 시스템에 독립적인 코드들은 추후에 다른 프로젝트에서도 사용될 여지가 있기 때문에, 재사용성을 고려해 이를 기준으로 모듈을 분리하였다.
해당 모듈은 전역적으로 사용된다는 점, 그리고 대부분 유틸성 클래스라는 점에서 global-utils라고 이름을 지어주었다.
공통 모듈이라 하면 흔히 common 키워드를 떠올리는데, 여기서는 common이라는 네이밍을 사용하지 않았다. 왜냐하면 common이라는 네이밍이 해당 모듈에 대한 접근 또는 인식을 가볍게 만들 수 있기 때문이다.

상황에 따라 해당 모듈은 존재하지 않을 수도 있다. 또는 모듈이 아닌 라이브버리 형태로 jar 패키징되어 저장소에 배포되고 의존할 수도 있다. 여러 가지 불확실성이 가득하지만, 한 가지 확실한 것은 global-utils 모듈은 변경이 거의 없다는 점이다. 어느 프로젝트에서나 사용될 수 있는 시스템에 독립적인 공통 코드는 흔치 않다.
[ 서로 다른 수준(속도)의 공통 코드 분리하기 ]
그 다음으로 처리할 부분은 특정 시스템에 종속적인 공통 코드이다. 해당 부분은 도메인 영역과 인프라 영역으로 세분화할 수 있고, 이를 모듈의 기준으로 삼을 수 있다.
- 시스템에 종속적인 공통 코드
- 도메인 영역: App, AppStatus
- 인프라 영역: DatabaseConfig, CacheConfig
이 둘을 분리해야 하는 이유는 도메인 영역과 인프라 영역이 서로 다른 수준(Level)이며, 서로 다른 속도로 변경되기 때문이다. 이 부분을 이해하려면 고수준과 저수준이 무엇인지 짚고 넘어가야 한다.
수준(Level)을 엄밀하게 정의하자면 “입력과 출력까지의 거리”이다. 입력으로는 HTTP 혹은 웹소켓 등이 있을 수 있고, 출력으로는 캐시, 데이터베이스 등이 있을 수 있다. 시스템의 입력과 출력 모두로부터 멀리 위치할수록 고수준 정책에 해당한다. 따라서 도메인 영역은 고수준 영역에 해당하며, 인프라 영역은 저수준 영역에 해당한다.
비즈니스와 관련된 도메인 영역은 비즈니스 요구 사항에 맞춰 수시로 변경된다. 반면에 데이터베이스 설정과 같은 인프라 영역은 특정 시점에 변경된다. 예를 들어 보안 취약점이 생겼다고 해서 혹은 사용중인 데이터베이스를 변경한다고 해서 비즈니스 부분이 바뀌어서는 안된다. 따라서 고수준 정책은 저수준 세부사항들로부터 분리될 필요가 있으며, 만약 분리되지 않는다면 데이터베이스를 바꾸는 등의 영향이 비즈니스 로직에 영향을 줄 수 있게 된다.
데이터베이스, 웹, 라이브러리, 프레임워크 등은 비즈니스가 아닌 영역들이며, 비즈니스와 다른 속도로 변한다. 즉, 이 둘은 변경이 요구되는 시점이 다르기 때문에 최대한 독립시켜주는 것이 좋다.
이렇게 두 모듈을 분리한 구조를 그림으로 표현하면 다음과 같다.

domain 모듈에는 도메인 엔티티, 도메인 엔티티를 위한 Enum 등이 포함될 수 있지만 절대 유스케이스는 포함시키지 않았다. 이 부분은 뒤에서 자세히 살펴보도록 하자.
[ 서로 다른 기능의 모듈 분리하기 ]
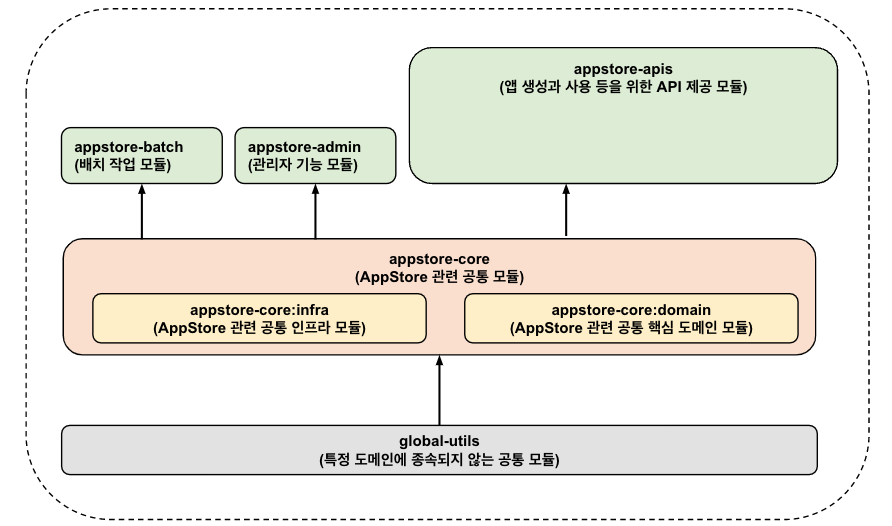
우리가 담당하는 시스템은 서로 다른 기능들을 가질 수 있다. api를 제공해줄 수도 있고, 통계 또는 일괄 처리를 위해 배치 작업이 필요할 수도 있고, 관리자를 위해 SSR 기반의 웹페이지를 제공해줄 수도 있다. 이들은 서로 다른 기능의 모듈이고, 그에 따라 필요로 하는 의존성이 다르기 때문에 모듈로 나누어 주는 것이 좋다.
- apis: FE에게 API를 제공해주는 모듈
- admin: 관리자를 위한 관리 웹 페이지 모듈
- batch: 배치 작업을 위한 모듈
- …
기능 별로 모듈을 세분화하면 다음과 같이 나눌 수 있다.
[ 서로 다른 액터의 모듈 분리하기 ]
이 부분을 제대로 이해하려면 SRP에 대해서 확실히 알고 넘어갈 필요가 있다.
로버트 마틴은 SOLID 원칙 중에서 그 의미가 가장 전달되지 못한 원칙으로 SRP(Single Responsibility Principle, 단일 책임 원칙)를 뽑았다. 그리고 SRP는 “하나의 일만 해야한다”는 의미가 아니라 "단일 모듈은 변경의 이유가 하나, 오직 하나뿐 이여야 한다."는 것이라고 설명했다. 여기서 변경의 이유가 하나여야 한다는 것은 하나의 액터만 책임져야 한다는 의미이며, 여기서 액터란 동일한 변경을 요청하는 사람들을 의미한다. 즉, 최종적으로 "하나의 모듈은 하나의, 오직 하나의 액터에 대해서만 책임을 져야 한다."는 원칙이 바로 SRP이다.
예를 들어 AppStore에 등록된 앱의 사용량을 측정하는 메소드가 있다고 하자. 앱을 만드는 사람은 사용량을 바탕으로 사용 금액을 계산해서 비용을 청구하고 있다. 앱을 관리하는 사람은 사용량을 바탕으로 사용 시간을 보고하고 있다. 이런 상황에서 앱의 사용량을 측정하는 메소드는 2명의 액터를 책임지기 때문에 SRP를 위반하는 것이다.
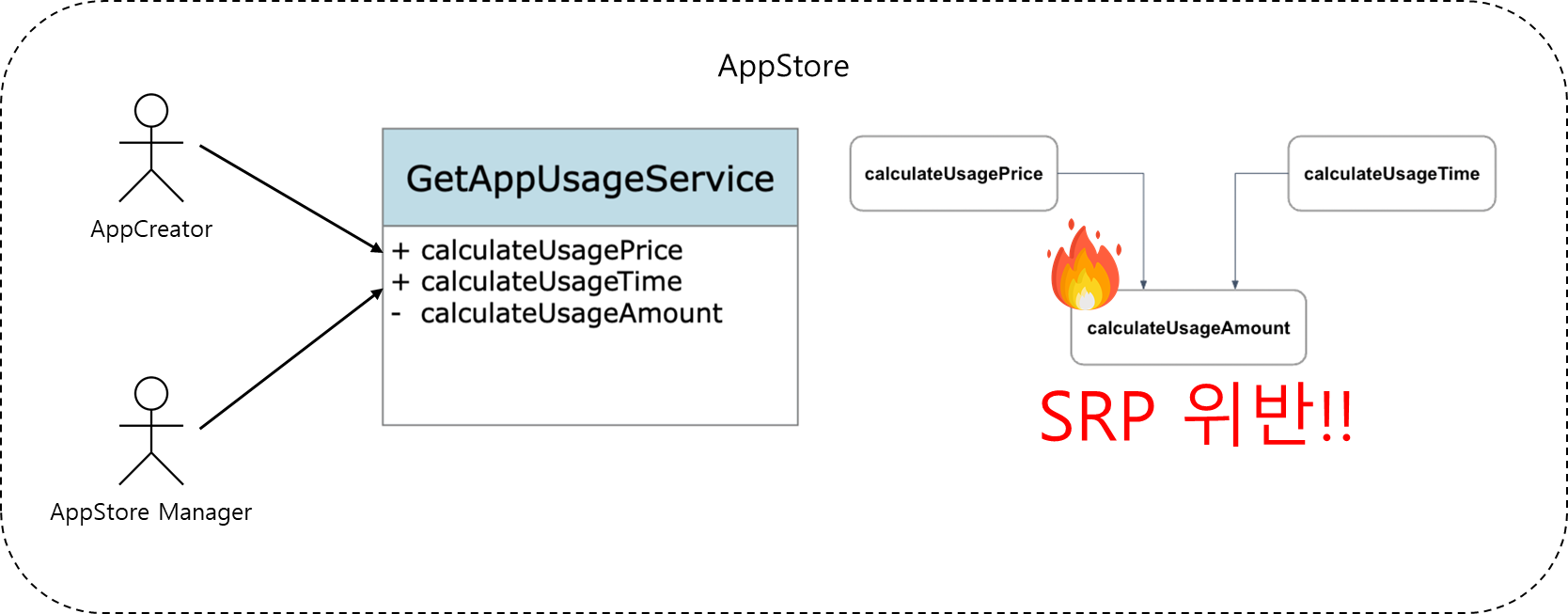
SRP를 위반하면 안되는 이유는 액터의 요구사항이 점점 달라지기 때문이다. 예를 들어 앱의 관리자는 앱의 사용 시간 보고를 “분” 단위에서 “초” 단위로 변경하기를 원하고, 이를 위해 앱의 사용량을 측정하는 메소드에도 변경이 필요하다고 해보자. 만약 앱의 사용량을 측정하는 메소드를 변경하게 된다면, 의도치 않은 영향이 사용 금액에도 영향을 줄 수 있다. 그리고 사용 금액과 관련된 부분은 회사의 돈과 관련된 부분이기 때문에 치명적인 영향을 줄 수 있다.
이러한 문제가 발생하는 이유는 SRP를 위반하기 때문이며, 하나가 아닌 여러 액터를 책임지면서 변경의 이유가 여러 개이기 때문이다. 이러한 상황을 예방하기 위해서는 액터를 기준으로 모듈을 나누는 것이 좋다고 판단했다.

그렇다면 각각의 서브 모듈을 독립적인 서비스로 배포해야 하나 고민될 수 있다. 하지만 독립적인 모듈이라고 하더라도 반드시 별도의 서비스로 분리시킬 필요는 없다.
로버트 마틴은 컴포넌트가 서비스화될 가능성이 있다면 컴포넌트 결합을 분리하되 서비스가 되기 직전에 멈추는 방식을 선호한다고 한다. 왜냐하면 가능한 한 오랫동안 동일한 주소 공간에 남겨둠으로써 서비스에 대한 선택권을 열어둘 수 있다기 때문이다. 이 방식을 사용하면 초기에는 컴포넌트가 소스 코드 수준에서 분리된다. 그러다가 개발, 배포, 운영 문제가 등장하면 서비스 수준으로 전환하면 된다.
따라서 서비스의 초기라면 모듈은 나누되 하나의 서비스로 배포되도록 전략을 가져가는 것이 좋다.
2. 멀티 모듈 설계 및 운영 시의 주의사항
[ 유스케이스는 공통 모듈에 담지 않기 ]
비즈니스 로직은 시스템의 필요성에 따라 핵심 비즈니스 로직과 유스케이스로 나눌 수 있다.
- 비즈니스 로직
- 핵심 비즈니스 로직: 시스템 없이도 존재하는 비즈니스 로직
- 유스케이스: 시스템이 있어야만 유효한 비즈니스 로직
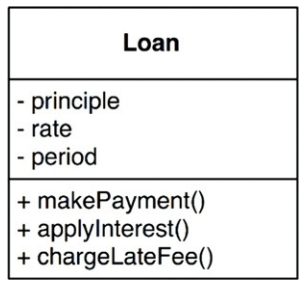
핵심 비즈니스 로직은 시스템 없이도 존재하는 비즈니스 로직이다. 예를 들어 은행이 대출금에 N%의 이자를 부과하여 돈을 버는 것은 은행의 비즈니스 로직이다. 이것은 시스템이 있으면 편리하지만, 시스템이 없어도 직원이 계산기를 두드려 고객에게 청구할 수 있다. 이러한 핵심 비즈니스 로직은 데이터를 필요로 하는데, 이를 핵심 비즈니스 데이터라고 부른다.
핵심 비즈니스 로직과 핵심 비즈니스 데이터는 근본적으로 결합되기 때문에 하나로 묶기 좋은데, 우리는 이것을 도메인 엔티티 혹은 도메인 객체라고 부른다. 결국 핵심 비즈니스 로직은 도메인 엔티티가 갖는 비즈니스 로직이다.
반면에 어떤 비즈니스 로직은 반드시 시스템이 있어야만 의미를 갖는데, 이를 유스케이스라고 부른다. 예를 들어 은행이 대출 견적을 제공해주려고 하는데, 고객의 개인 정보를 받고 신용도를 조회하여 신용도가 500 이상인 경우에만 제공할 수 있다고 하자. 이러한 비즈니스 로직은 시스템을 통해서만 존재할 수 있기 때문에 이를 우리는 유스케이스라고 부른다. 유스케이스에는 입력과 출력 그리고 처리 과정이 기술된다. 결국 유스케이스는 우리에게 흔히 익숙한 애플리케이션 계층 혹은 서비스 계층에 해당한다고 볼 수 있다.

그리고 이 중에서 유스케이스는 공통 모듈에 담지 않기로 결정했다. 유스케이스를 공통 코드로 뺐더니, 사이드 이펙트가 발생하기 쉬울 뿐만 아니라 예외 케이스를 위한 분기 처리도 들어가게 되면서 많은 문제가 발생하였다. 이는 서로 다른 액터를 위한 로직들이 혼용되기 때문이며, 결국 SRP를 위반하기 때문이다. 따라서 공통 모듈에는 유스케이스가 아닌 도메인 엔티티와 관련된 코드만을 추가하기로 하였다.
이렇게 하면 비슷해 보이는 코드들이 여럿 생기는데, 코드가 비슷하다고 해서 모두 중복은 아니다. 예를 들어 비슷한 코드라고 하더라도 서로 다른 액터를 처리하고 있다면 이것은 “진짜 중복”이 아니므로 이를 “우발적 중복”이라고 부른다. 따라서 중복이 발생했다면 이것이 “진짜 중복”인지 고민해볼 필요가 있다.
그럼에도 불구하고 진짜 중복이 보인다면, 중복을 허용하거나 공통 API 등을 통해 해결할 수 있다. 공통 API를 통해 처리하면 트랜잭션이 신경쓰일 수 있는데, 실제 운영을 하다 보면 트랜잭션 문제는 생각보다 발생하지 않을 것이다.
참고로 지나치게 공통 API를 이용하여 해결한다면 초거대 API 서버가 탄생하게 되므로 정말 중복이 심각해지는 경우에만 고려하는 것이 좋다.
[ 자동 빈 등록 방식 사용하지 않기 ]
코어의 인프라 모듈에 존재하는 인프라 구성들을 스프링 컨테이너에 등록해주어야 하는데, 이때 다음과 같이 컴포넌트 스캔 기반의 자동 등록 방식을 사용하지 않는 것이 좋다.
@Configuration(proxyBeanMethods = false)
@ComponentScan("com.mangkyu.appstore")
class InfraConfig {
}
예를 들어 인프라 구성 중에 통계 데이터베이스 구성이 있고, 일부 모듈에서는 통계 데이터베이스 연결이 불필요하다고 하자. 이때 컴포넌트 스캔 기반의 자동 등록 방식을 사용한다면, 통계 데이터베이스가 불필요한 모듈에서까지 데이터베이스 커넥션을 잡아먹게 된다. 그렇다고 특정 모듈에서만 통계 데이터베이스 설정을 제거하는 것은 상당히 까다롭다.
즉, 컴포넌트 스캔 기반의 자동 등록 방식을 사용해서는 인프라 구성을 제어할 수 없는 것이다. 또한 해당 방식은 어떤 인프라 구성들이 존재하는지, 무엇이 현재 모듈에 적용되는지 명시적으로 파악하기가 어렵다.
따라서 인프라 구성에 대한 제어권을 획득할 수 있는 방법을 사용하는 것이 좋은데, Spring 프레임워크에서 제공하는 ImportSelector를 이용하여 이를 구현해보도록 하자.
먼저 인프라 구성 타입을 추상화한 인터페이스를 생성한다.
해당 인터페이스를 구현한 클래스는 다른 모듈에서 적용될 수 있음을 나타낸다.
public interface AppStoreConfig {
}
모든 인프라 구성들은 해당 인터페이스를 구현한다. 구성 클래들에는 자동 빈 스캔 방식에 의해 등록되지 않도록 @Component를 포함한 하위 애노테이션들이 존재하지 않는다.
@EnableAsync
public class AsyncConfig implements AppStoreConfig {
...
}
@EnableTransactionManagement
@EntityScan("com.mangkyu.appstore")
@EnableJpaRepositories("com.mangkyu.appstore")
public class JpaConfig implements AppStoreConfig {
...
}
이제 구성 클래스들을 모아둔 enum 클래스를 하나 생성한다.
이를 통해 인프라 구성들이 존재하는지, 무엇을 적용할 지 손쉽게 파악할 수 있다.
@Getter
@RequiredArgsConstructor
public enum AppStoreConfigGroup {
ASYNC(AsyncConfig.class),
JASYPT(JasyptConfig.class),
JPA(JpaConfig.class),
;
private final Class<? extends AppStoreConfig> configClass;
}
그리고 적용할 인프라 구성을 명시할 @Enable 어노테이션과 어노테이션에 존재하는 인프라 구성을 적용시켜 줄 ImportSelector를 구현한다. ImportSelector는 애플리케이션이 실행되는 시점에 해당 어노테이션에 붙은 Enum 값들을 기반으로 동적으로 구성 파일들을 불러온다.
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import org.springframework.context.annotation.Import;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Import(AppStoreConfigImportSelector.class)
public @interface EnableAppStoreConfig {
AppStoreConfigGroup[] value();
}
ImportSelector를 구현할 때는 ImportSelector의 하위 인터페이스인 DeferredImportSelector를 사용하면 된다. DeferredImportSelector는 모든 @Configuration 빈들이 처리된 후에 동작하는 ImportSelector이다. 선택된 설정들이 @Conditional 조건을 갖고 있는 경우에 유용하다.
이를 처리하기 위해 EnableAppStoreConfig의 value에 할당된 Enum 값들을 모두 불러온 후에 configClass 값을 가져와야 한다. 이러한 역할을 담당하는 ImportSelector 구현체는 다음과 같이 만들어줄 수 있다.
class AppStoreConfigImportSelector implements DeferredImportSelector {
@Override
public String[] selectImports(AnnotationMetadata metadata) {
return Arrays.stream(getValues(metadata))
.map(v -> v.getConfigClass().getName())
.toArray(String[]::new);
}
private AppStoreConfigGroup[] getValues(AnnotationMetadata metadata) {
Map<String, Object> attributes = metadata.getAnnotationAttributes(EnableAppStoreConfig.class.getName());
return (AppStoreConfigGroup[]) MapUtils.getObject(attributes, "value", new AppStoreConfigGroup[]{});
}
}
그러면 이제 다음과 같이 개별 모듈들에서 적용할 인프라 구성을 동적으로 그리고 명시적으로 선택할 수 있다. 이를 통해 인프라 구성에 대한 제어권을 획득할 수 있게 된 것이다.
@Configuration(proxyBeanMethods = false)
@EnableAppStoreConfig({
AppStoreConfigGroup.ASYNC,
AppStoreConfigGroup.JASYPT,
AppStoreConfigGroup.JPA,
})
class InfraConfig {
}
[ 엄격하게 공통 모듈 관리하기 ]
공통 모듈은 필요하지만, 잘못 설계되고 제대로 관리되지 않는 공통 모듈은 오히려 많은 문제를 야기한다. 공통 모듈이라는 것은 모든 모듈이 의존한다는 뜻이고, 변경이 모든 모듈에 영향을 끼칠 수 있음을 의미하기 때문이다. 따라서 공통 모듈은 가장 엄격하게 관리되어야 한다. 공통 모듈을 관리하기 위한 많은 방법들이 있다.
- 컴파일 제한: 언어(package-private 가시성 등) 또는 빌드 도구를 활용한 컴파일 제한
- 빌드 제한: 빌드 도구 또는 ArchUnit 라이브러리 등을 활용한 빌드 제한
- 머지 제한: Merge를 위한 최소 Approve 수 제한 등
- 기타: Github Actions를 이용한 변경 모듈 라벨링 등
가시성 문법을 이용한 방법
가장 기본적이고, 선호되는 방법은 언어 차원에서 제공하는 가시성 문법을 이용하는 것이다.
이 클래스는 앞서 살펴본 ImportSelector 클래스인데, 해당 클래스는 infra 외의 다른 모듈들에서는 사용될 일이 없기 때문에 가시성을 package-private으로 해두었음을 확인할 수 있다.
개인적으로는 default 접근 제어자를 package-private으로 해두고, 필요한 경우에만 열어주는 방식으로 개발을 하고 있다. 컨트롤러와 컨트롤러의 입/출력 DTO 등 많은 부분에 대한 가시성을 낮춤으로써 컴파일 제한을 걸어줄 수 있다.
class AppStoreConfigImportSelector implements DeferredImportSelector {
@Override
public String[] selectImports(AnnotationMetadata metadata) {
return Arrays.stream(getValues(metadata))
.map(v -> v.getConfigClass().getName())
.toArray(String[]::new);
}
private AppStoreConfigGroup[] getValues(AnnotationMetadata metadata) {
Map<String, Object> attributes = metadata.getAnnotationAttributes(EnableAppStoreConfig.class.getName());
return (AppStoreConfigGroup[]) MapUtils.getObject(attributes, "value", new AppStoreConfigGroup[]{});
}
}
빌드 도구를 이용한 방법
그 다음으로 빌드 도구를 이용해 제한하는 방법도 있다. 예를 들어 gradle은 의존성을 위해 implementation과 api 등과 같은 문법을 제공하고 있는데, 이 둘은 전이 의존성의 관점에서 차이가 있다. 전이 의존성이란 C가 B를 의존하고, B가 A를 의존할 때, C도 A에 의존하는 것을 전이 의존성(Transitive Dependency)이라고 한다.
api는 전이 의존성에 해당하는 클래스를 컴파일 경로에 노출시킨다는 특징이 있다. 아래의 그림에서 B가 A를 api로 의존하고 있기 때문에 A에 대한 전이 의존성이 있는 C도 A의 클래스를 사용할 수 있게 되는 것이다.

만약 이것을 implementation으로 바꾼다면 컴파일 에러가 발생하면서 Hello 클래스를 사용할 수 없게 된다.

누군가는 api가 더 좋은거 아니냐고 반문할 수 있겠지만, 좋은 시스템은 제약이 있는 시스템이다. api를 사용하면 불필요한 컴파일 의존성이 허용되므로 이를 사전 차단하기 위해 api를 전혀 사용하지 않는 것이 좋다. 만약 C에서도 A의 클래스를 직접 참조해야 한다면 C에서 A를 implementation 해주면 된다. 추가로 api를 사용하면 재컴파일에 의해 불필요한 빌드 시간이 생긴다고 한다. 자세한 내용은 api와 implementation의 차이를 다루는 포스팅을 참고하도록 하자.
ArchUnit 라이브러리를 이용한 방법
아래의 그림은 ArchUnit 라이브러리를 사용하는 모습인데, 이를 통해 의존성 방향이나 클래스의 가시성 등을 검사하는 자동화된 테스트 코드를 작성할 수 있다. 따라서 컨벤션이나 제약을 준수하는지 검사하고자 하는 경우에 유용하다.

GitHub를 이용한 방법
GitHub를 통해 코드 리뷰를 강제하는방법도 있다. 공통 코드는 가급적이면 추가되지 않아야 하고, 추가할 때에도 모든 팀원들의 코드 리뷰를 거치는 것이 좋다. 이를 통해 해당 코드가 공통 모듈에 추가되는 것이 적절한지 검증받을 수 있을 뿐만 안이라, 다른 팀원들도 해당 코드를 인지하여 추후에 재사용할 수 있을 것이다.

위와 같이 설정한다면, 어프룹을 얻은 후에야 머지를 할 수 있게 제한된다.

이것들 외에도 다양한 방법들이 있으니, 운영하면서 각 팀에 맞게 부족한 부분들을 채워나가는 것이 좋다.
[ 많은 결정 사항들을 미루기 ]
멀티 모듈 구조를 만들다보면 여러가지 결정의 순간들을 만나게 된다. 액터 기반으로 세분화된 apis의 서버 모듈 각각을 독립적인 서비스로 분리해야 하나 혹은 global-utils를 jar 형태로 라이브러리화해서 관리해야 하나 고민할 수도 있다. 이것들 외에도 수많은, 왠지 정답인 것 처럼 보이는 결정사항들을 만나게 된다. 하지만 그럴 때면 로버트 마틴이 했던 다음의 얘기를 떠올리고 결정 사항을 미루는 것이 좋다.
A good architecture allows you to defer critical decisions.
(좋은 아키텍트는 결정되지 않은 사항들을 최대화한다.)
- Robert C. Martin -
apis 모듈들을 독립적인 서비스로 나누는 것은 많은 장점이 있다. 하지만 실제 서비스를 운영하는 관점에서 그리고 금전적인 관점에서는 오히려 비용이 증가하게 된다.
만약 우리가 프로덕션에서 7개의 환경을 운영하고 있다고 하자. 기존에는 1개였던 서버를 모듈에 따라 독립적인 서비스로 관리하면 순식간에 관리해야 할 서버가 (7 * 모듈의 수)로 늘어나게 된다. 운영 비용이 상당히 증가 할 것이기 때문에 생존을 위해 서비스를 분리하지 않으면 안되겠다 싶을 때까지 미루는 것이 좋다.
global-utils의 경우에는 당장 라이브러리화 해서 얻는 장점이 없다. 오히려 jar를 업로드하기 위한 번거로운 작업들이 필요하므로 새로운 프로젝트가 생성되면 그때 다시 검토하는 것이 좋다.
결정 사항을 미루라는 조언은 애플리케이션 개발에도 일맥상통한다는 특징이 있다. 테이블 설계부터 캐시 적용 그리고 추상화까지 많은 부분에서 결정사항을 미룸으로써 변경에 유연하게 대응할 수 있었다.
예를 들어 데이터베이스 변경을 DBA에게 요청드려야 하는 상황이라고 하자. 만약 테이블 설계를 미루지 않았다면 요구 사항이 변경됨에 따라 혹은 설계가 변경됨에 따라 DBA에게 잦은 변경 요청을 드렸어야 할 것이다.
소프트웨어 개발 원칙 중에 YAGNI 법칙이라고도 있다. 어떤 작업을 함에 있어서 “내가 지금 필요하지도 않은 것을 미리 하고 있지는 않은지" 고민해보는 것이 좋다.
또 하나 중요한 것은 이러한 결정들이 1회성이 아니라는 점이다. 새로운 요구사항이 들어오고 애플리케이션이 확장되면서 이러한 결정들은 수시로 재검토될 필요가 있다. 그래야만 시스템 아키텍처도 계속해서 진화하고, 더욱 복잡한 요구사항에 손쉽게 대응할 수 있다.
이렇듯 결정을 미뤄야 하는 이유는 어떤 구조가 더욱 적합한지 현재로써 판단하기 힘들기 때문이다. 또한 프로젝트가 계속 진화함에 따라 최적인 구조가 달라질 수도 있다. 따라서 불필요한 초기의 결정 사항들을 최대한 미루도록 하자.
[ 모듈은 최대한 단순하게 ]
멀티 모듈을 지나치게 세분화한다면 모듈 구조를 처음 접하는 팀원들에게 또 하나의 인지 부하를 줄 수 있다. 또한 대부분의 경우에는 지나치게 모듈화해서 얻는 장점이 없다고 판단했다. 따라서 모듈의 구조는 최대한 단순하고 직관적이게 가져가는 것이 좋다고 판단했다.
[ 기타 멀티 모듈 팁들 ]
- Gradle 멀티 모듈 네이밍 컨벤션
- 테스트를 위한 Gradle 플러그인
- 스프링 프레임워크가 제공하는 모듈화 도구(스프링 모듈리스, Spring Modulith)
- 외부 프로젝트를 서브 모듈로 옮기기 위한 Git SubTree
위의 내용은 절대적인 기준이 아니며, 상황에 따라 달라질 수 있음을 참고해주시면 좋을 것 같습니다. 또한 해당 내용은 인프콘 2023에서 발표한 내용이니, 인프콘 영상을 통해서도 참고 하실 수 있습니다. 발표자료는 여기서 확인하실 수 있고, 예시로 설계된 구조는 깃허브에서 확인하실 수 있습니다.
'Server' 카테고리의 다른 글
| [Redis] 레디스가 제공하는 분산락(RedLock)의 특징과 한계 (9) | 2023.10.10 |
|---|---|
| [Infra] 서비스 메시(Service Mesh)의 등장과 쿠버네티스(Kubernetes)의 SidecarContainers (2) | 2023.10.03 |
| [Gradle] Gradle Java 플러그인과 implementation와 api의 차이 (9) | 2023.05.16 |
| [Nginx] Nginx 예시/샘플 설정 공유 및 설정 시의 주의사항 (5) | 2023.04.18 |
| [ELK] 파일비트(Filebeat)와 로그스태시(Logstash)에 대한 설정 예시 (0) | 2023.01.24 |
