
티스토리 뷰
[Server] 프로메테우스와 푸시 게이트웨이의 한계(Prometheus and limits of Push Gateway)
망나니개발자 2026. 5. 12. 10:00서버를 운영하다 보면 가장 먼저 마주치는 결정 중 하나가 “메트릭을 어떻게 수집할 것인가” 입니다. 이번 포스팅에서는 프로메테우스(Prometheus)가 채택한 pull 방식과 그 대척점에 있는 push 방식이 무엇이고 어떤 차이가 있는지 정리해보도록 하겠습니다.
1. 프로메테우스에 대하여(About Prometheus)
[ 프로메테우스란? ]
프로메테우스는 SoundCloud에서 2012년부터 개발한 오픈소스 시계열 모니터링 시스템이다. 이후 Kubernetes에 이어 CNCF의 두 번째 졸업 프로젝트가 되면서 사실상 클라우드 네이티브 환경의 표준 모니터링 도구로 자리잡았다. 프로메테우스의 특징들로는 다음과 같은 것들이 있다.
- 시계열 데이터베이스(TSDB) 내장 — 별도 외부 저장소 없이 자체 저장
- PromQL — 라벨 기반의 강력한 쿼리 언어
- Pull 기반 메트릭 수집 — 모니터링 서버가 능동적으로 데이터 조회
- 다차원 데이터 모델 — metric_name{label1="...", label2="..."} 형태로 풍부한 차원 표현
- Service Discovery 통합 — Kubernetes / Consul / EC2 등에서 target 자동 발견
[ Pull 모델과 Push 모델 ]
Pull 모델(Pull Model)
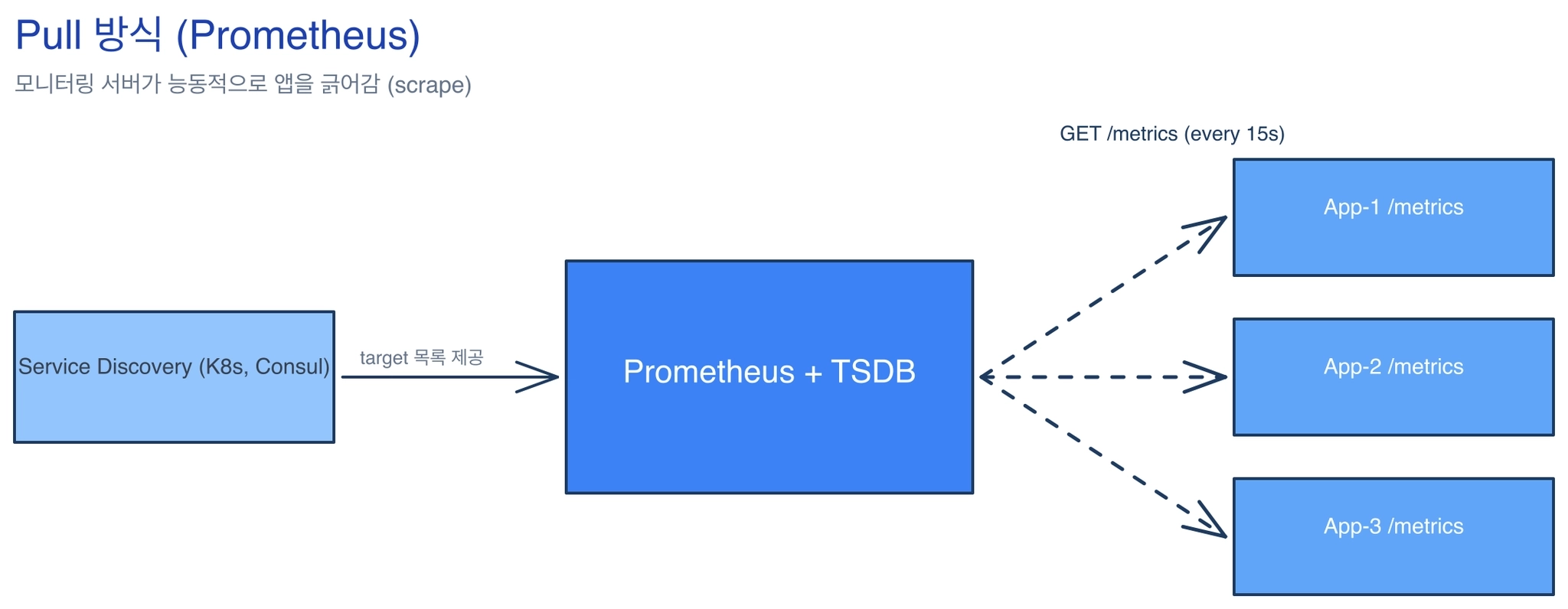
Pull 모델이란 서버가 GET /metrics 같은 HTTP 엔드포인트만 띄워두면, 서버가 정해진 주기(보통 15s/30s)로 그 엔드포인트를 scrape(긁어감) 해가는 방식을 말한다. 기본적으로 프로메테우스가 pull 모델 방식이다.
scrape 결과는 다음과 같은 텍스트 포맷이 된다.
# HELP request_count 처리한 요청 수
# TYPE request_count counter
request_count{method="GET", status="200"} 1523
request_count{method="POST", status="500"} 12
pull 모델에서 메트릭 서버는 데이터를 가져올 서비스 목록을 알아야 한다. 이를 위해 쿠버네티스와 같은 인프라 기술들과 연결되어 함께 활용된다. 주기적으로 가져올 서버들이 등록되면, 메트릭 서버는 해당 서버들을 주기적으로 호출하며 정보를 가져온다. 메트릭 서버를 여러 대 둘 때 흔히 빚어지는 문제는 여러 서비스가 같은 출처에서 데이터를 중복해서 가져오는 부분으로, 이를 위해 모종의 중재 메커니즘이 필요하다.
Push 모델(Push Model)
Push 모델이란 앱이 능동적으로 자기 메트릭을 외부 수집기에 전송하는 방식을 말한다. OpenTelemetry / Datadog / New Relic 등은 처음부터 push 모델을 기본으로 한다.

푸시 모델의 경우 대상 서버에 통상 수집 에이전트가 존재하여, 서버가 생산하는 지표 데이터를 받아 모은 다음 주기적으로 메트릭 서버에 전달한다. 간단한 카운터 지표의 경우에는 수집기에 보내기 전에 에이전트가 직접 데이터 집계 등의 작업을 처리할 수도 있다. 데이터를 집계(aggregation)하여 전달하는 방식은 메트릭 서버의 부하를 줄이는 효과적인 방법이다. 데이터 전송 트래픽의 양이 막대하여 메트릭 서버가 일시적으로 전송되는 데이터를 처리하지 못하게 되어 오류를 반환하면, 에이전트는 내부의 소규모 버퍼에 데이터를 일시적으로 보관한 다음(디스크에 기룩해 둔다든지 하여) 나중에 재전송할 수도 있을 것이다. 하지만 만일 에이전트가 위치한 서버 클러스터가 자동 규모 확장이 가능하도록 설정되어 있다면, 서버가 동적으로 추가되거나 삭제되는 과정에서 해당 데이터는 소실될 수도 있다.
Pull 모델과 Push 모델에 대한 비교
Pull 모델의 장점과 단점은 다음과 같이 정리할 수 있다.
- 장점(Pros)
- 앱 단순화 — 앱은 endpoint만 띄우면 끝. 어디로 보낼지 알 필요 없음
- target 헬스 체크 자동 — scrape 실패 = 앱 down 으로 자연스럽게 감지
- 중앙 집중 제어 — scrape 주기, 리트라이, target 목록을 모니터링 서버에서 관리
- 푸시 폭주 위험 없음 — 앱이 트래픽 폭주하더라도 메트릭은 정해진 주기로만 흐름
- 단점(Cons)
- 단명 잡에 부적합 — 5초만에 끝나는 배치는 30초 scrape 주기로 잡힐 수가 없음
- 방화벽/네트워크 — 모니터링 서버가 모든 target에 inbound 접근 가능해야 함
- target 발견 의존성 — Service Discovery가 잘 동작해야 동적 환경에서 의미가 있음
이와 반대로 Push 모델의 장점과 단점은 다음과 같이 정리할 수 있다.
- 장점(Pros)
- 단명 워크로드 자연스러움 — 앱이 자기 시점에 보낼 수 있음
- 방화벽 친화적 — 앱이 outbound 한 방향만 열려있으면 됨
- 수집기 분리 가능 — 앱은 수집기 위치만 알면 되고, 저장소 종류에 무관해질 수 있음 (특히 OTLP)
- 단점(Cons)
- 앱 책임 증가 — 어디로, 얼마나 자주 보낼지 앱이 알아야 함
- 수집기 부하 집중 — 모든 앱이 같은 수집기로 push → 단일 병목 가능
- target health 추적이 어려움 — push가 안 오면 “안 보낸 건지” “죽은 건지” 구분이 모호
- 메트릭 폭주 위험 — 앱 수가 늘어나면 push 트래픽도 선형 증가
이를 표로 정리하면 다음과 같다.
| 항목 | Pull (Prometheus) | Push (PushGateway / OTLP) |
| 메시지 방향 | 모니터링 서버 → 앱 | 앱 → 수집기 |
| 앱 책임 | endpoint 노출만 | 수집기 위치 + 전송 주기 관리 |
| Health 체크 | scrape 실패로 자동 감지 | 별도 메커니즘 필요 |
| 단명 잡 | 부적합 | 적합 |
| 네트워크 | 모니터링 서버 → 앱 inbound 필요 | 앱 → 수집기 outbound만 |
| 트래픽 모양 | 일정 (scrape 주기) | 가변 (앱 push 시점에 따라) |
| 동적 target | Service Discovery 필요 | 자체 식별 (URL/라벨) |
2. 푸시 게이트웨이의 한계(Limits of PushGateway)
[ 푸시 게이트웨이란? ]
프로메테우스는 기본적으로 Pull 모델로 설계되어 있다. 하지만 일부 애플리케이션의 경우 Pull 모델로는 부적합한데, 대표적으로 수명이 짧은 배치 잡 등이 그러하다. 왜냐하면 5초 만에 끝나는 배치는 30초 scrape 주기로 잡힐 수가 없기 때문이다.
이런 케이스를 위해 등장한 어댑터가 PushGateway다. 배치 앱이 종료 직전에 자기 metric을 PushGateway에 push 해두고 죽으면, Prometheus가 평소처럼 PushGateway를 scrape해서 가져간다. 즉 push 모델을 pull 모델 안으로 끼워맞춘 것이다.

배치 애플리케이션 관점에서 이러한 흐름을 정리하면 다음과 같다.
- 배치 앱이 종료 직전 POST /metrics/job/<job-name>/instance/<id> 형태로 PushGateway에 metric 전송
- PushGateway는 받은 metric을 자기 메모리에 보관 (디스크에 주기적으로 persist)
- Prometheus가 정해진 scrape 주기로 PushGateway의 /metrics 엔드포인트를 scrape
- 결과적으로 Prometheus TSDB에는 다른 서비스 metric과 동일한 형태로 저장됨
여기서 중요한 건 PushGateway가 최종 저장소가 아니라는 점이다. 단지 push한 값을 Prometheus가 나중에 가져갈 수 있게 보관해두는 캐시에 가깝다. 결국 모든 데이터는 Prometheus의 TSDB가 들고 있게 된다.
[ 푸시 게이트웨이의 설계 의도 ]
푸시 게이트웨이는 초기부터 짧은 수명 등으로 인해 프로메테우스가 직접 scrape 할 수 없는 작업의 메트릭을 push 방식으로 전달하기 위해 설계되었다. 대표적으로 빠르게 실행 및 종료되는 배치 잡의 경우가 적합한 용도라고 공식 깃헙에서 얘기한다. 따라서 여러 포스팅에서도 처리량이 늘어났을 때의 한계를 설명하고 있다.
먼저 프로메테우스 공식 블로그의 When to use the Pushgateway 페이지에서는 푸시 게이트웨이를 제한적인 용도로 사용해야 하며, 여러 인스턴스가 하나의 푸시 게이트웨이를 사용하면 단일 장애 지점이자 병목이 될 수 있다고 설명하고 있다.

[ 푸시 게이트웨이의 내부 구현과 한계 ]
푸시 게이트웨이의 한계는 운영 옵션이 아니라 내부 구현 자체에서 비롯된다. 데이터가 어디에 어떻게 저장되는지 → 요청이 어떻게 처리되는지 → 그 구조에서 어떤 한계가 어떻게 나오는지 순서로 살펴보자.
데이터 저장을 위한 3단 메모리 맵 구조
푸시 게이트웨이는 받은 메트릭을 3단 중첩 형태의 메모리 맵에 저장한다.

각 단계의 의미는 다음과 같으며, 중첩 구조이므로 저장된 시계열(time series)의 총 수는 ① × ② × ③ 이다.
- Grouping — 어떤 인스턴스가 보낸 데이터인지 식별. (job, instance, ...) 같은 라벨 조합이 key임
- Metric Family — 그 인스턴스가 노출하는 메트릭 이름 (예: request_count, error_count)
- Metric Point — 같은 metric 이름이지만 라벨 값이 다른 데이터 포인트 (예: {adType="A"}, {adType="B"})
푸시 게이트웨이의 Grouping key는 클라이언트가 push하는 URL path로 지정된다. 프로메테우스는 첫 번째 라벨으로는 반드시 job-name을 넣도록 하고 있고, 이후 추가적인 key-value가 필요하다면 자유롭게 추가 가능하도록 다음과 같이 Path를 설계해두었다.
POST /metrics/job/<job-name>/instance/<id>/<key>/<value>/...
예를 들어 다음과 같이 URL에 따라 Grouping key가 설정되는 것이다.
- POST /metrics/job/batch-A → {job="batch-A"}
- POST /metrics/job/batch-A/services/mangkyu → {job="batch-A", services="mangkyu"}
- POST /metrics/job/batch-A/services/mangkyu/pods/1 → {job="batch-A", services="mangkyu", pods="1"}
그리고 grouping key는 맵 구조이므로 다음과 같이 key를 기반으로 동작한다.
- 같은 key로 push → 기존 값을 덮어쓰기
- 다른 key로 push → 새 entry 생성
따라서 5분마다 뜨고 죽는 배치가 있다면, pods 같이 단조 증가하는 휘발성 라벨에 의해 매번 새로운 키가 적재되는 것이다. 푸시 게이트웨이는 자동 TTL이 없어서 외부 cron이 DELETE를 호출해주지 않는 한 절대 사라지지 않는다. 이로 인해 불필요한 메모리를 많이 차지할 수 있다.
글로벌 락으로 보호되는 메모리 맵
그리고 이 메모리 맵은 단 하나의 RWMutex로 보호된다. 단 하나의 RWMutex가 push 쓰기, scrape 읽기, 헬스체크, 디스크 persist를 모두 보호한다. 따라서 persist 중에는 push가 통째로 막히고, push 폭주 시 scrape 응답도 함께 늘어진다. 이는 푸시 게이트웨이의 성능을 저하시키는 대표적인 부분이다.
lock sync.RWMutex // Protects metricFamilies.
요청 처리 흐름
위에서 설명하였듯 클라이언트가 Push로 요청을 보내면, Prometheus가 Scrape 방식으로 가져가게 된다. 이때 푸시 게이트웨이 내부에서는 푸시 게이트웨이의 핵심 흐름은 다음과 같다.

- HTTP handler가 요청을 받아 writeQueue 채널에 넣음
- 백그라운드의 단일 goroutine loop이 큐에서 한 개씩 꺼내 순차 처리함
- 다음의 세가지 처리 단계를 거침
- 일관성 검증(consistency check) — 들어온 메트릭이 기존에 저장된 메트릭들과 충돌하지 않는지 검사함. 이 검사는 저장된 모든 시계열을 한 번 순회해야 함
- 메모리 맵 갱신 — RWMutex의 write Lock을 획득해 메모리 맵을 업데이트한 뒤 락을 해제함
- 디스크 persist — 메모리만 있으면 재시작 시 모두 날아가니, 주기적으로 디스크 파일에 스냅샷을 저장함 (기본 5분)
위 구조를 알면 푸시 게이트웨이의 한계가 어디서 나오는지 자연스럽게 보이는데, 먼저 큐의 크기는 1000으로 하드 코딩 되어있어 임의로 변경이 어렵다.
const (
writeQueueCapacity = 1000
)
이러한 부분은 이슈로 등록되기도 했었지만, 메인테이너는 1000이 어느 정도 버퍼링은 제공하되 메모리를 과도하게 쓰지 않기 위한 대략적인 값이며, 이것이 문제가 되는 상황이라면 큐 크기를 더 키워도 근본적인 해결책은 아닐 가능성이 높다고 설명한다.
또한 요청을 처리하는 goroutine이 1개 뿐이라, 병렬 처리가 불가능하며 worker pool, sharding, fan-out 같은 병렬 처리 메커니즘이 전혀 없다. 그런데 일관성 검증은 모든 맵을 순회해야 하므로, 처리하는 메트릭이 많아질수록 점점 일관성 검증이 O(N)으로 소요 시간이 늘어나기까지 한다.
그렇다고 파드를 늘린다고 하여도, 라운드 로빈 방식으로 푸시 게이트웨이가 요청을 받게 될테니, 동일한 정보가 푸시 게이트웨이의 파드에 중복 적재될 가능성이 높다.

PushGateway로 트래픽을 감당하기 어려운 상황에서는 결국 스케일 업이나 스케일 아웃이 아닌, 근본적인 해결 방식의 전환이 필요하다. 그것은 결국 앞서 설명한 OTLP 기반의 푸시 방식으로의 전환일 것이다.
'Server' 카테고리의 다른 글
| [AI] AI Harness(하네스) 구축을 위한 shim 아키텍처 with Busy Box pattern and PATH 하이재킹 (1) | 2026.05.05 |
|---|---|
| [Kafka] 카프카 파티션 증설 시 컨슈머의 auto.offset.reset 설정 주의사항 (0) | 2026.04.28 |
| [Server] 실용적인 아키텍처 패턴을 찾아서(Practical Architecture Pattern) (11) | 2025.11.25 |
| [Server] 운영 환경을 위한 실용적인 로그 레벨(Practical Log Level) (0) | 2025.11.11 |
| [Server] MCP 서버 프로토콜, SSE에서 Streamable HTTP 방식으로의 대변경 (11) | 2025.08.12 |
