
티스토리 뷰
1. JVM 내부의 힙 객체의 헤더 (Heap Object Header on JVM Internals)
[ 객체의 메모리 레이아웃과 객체 헤더 ]
객체의 메모리 레이아웃
다음의 HotSpot JVM 객체 메모리 구조에서 보이듯이, 모든 자바 객체는 인스턴스 데이터(payload) 외에도 객체의 헤더나 정렬 패딩을 위한 메모리 공간이 존재함을 알 수 있다.

위와 같은 여러 정보들이 모여서 하나의 객체가 되는데, 그 중에서도 우리가 눈여겨볼 부분은 객체의 헤더 부분이다. 배열의 길이는 우리가 이미 알고 있기에, 그 중에서 마크 워드와 클래스 워드에 집중해서 살펴보도록 하자.
마크 워드(mark word)
마크 워드(mark word)는 포인터가 아니라 그 자체로 데이터를 담고 있는 비트 필드(bit field)로, 각 객체 별로 고유하게 관리되는 메타데이터가 저장된다. 대표적으로 해시 코드는 객체의 메묄 주소를 가리키어 각 객체 별로 고유하게 할당되기에, 마크 워드에 할당된다. 그 외에도 Generational GC(세대별 GC)를 위한 나이 및 객체가 GC의 대상으로 수집되었는지 여부를 표시하는 마킹 비트 등이 존재한다.
- Lock 정보: 경량(lock-free), 모니터 락(Heavyweight Lock) 등 동기화 상태
- GC Age: GC 구현을 위한 객체의 나이
- HashCode: 객체의 해시코드 값으로, hashCode()가 처음 호출될 때 저장됨
- Unused: 미사용 구간
마크 워드에는 위의 정보들이 순차적으로 비트 단위로 인코딩되어 저장된다. 참고로 위의 설명에도 적혀있듯이, HashCode는 객체의 생성 초기에는 0으로 존재하다가, hashCode()가 처음 호출될 때 할당된다.
클래스 워드(Klass word)
클래스 워드(Klass word)는 포인터로, 해당 객체의 클래스 메타데이터가 존재하는 메모리 주소를 가리킨다. 클래스에 종속적이라 모든 객체마다 동일한 메타데이터는 하나로 관리하면 되기 때문에, 이를 클래스 공유 메타데이터라고도 한다. 대표적으로 클래스 정보(klass)가 클래스 워드를 통해 얻어와지는 정보 중 하나로, 해당 객체가 어떤 클래스의 인스턴스인지를 표현한다.
- 클래스 정보 (InstanceKlass 구조체 주소): 해당 객체가 어떤 클래스의 인스턴스인지 나타냄
- VTable (Virtual Method Table) 포인터: 가상 메서드 테이블 주소 (다형성을 지원하기 위한 메서드 테이블)
- 필드 정보: 필드의 오프셋, 타입 정보
- 정적 변수(Static Fields): 해당 클래스의 정적 필드에 대한 정보
자바는 개발자들을 위해 클래스 정보를 표현하는 Class 타입을 제공하여, 클래스에 대한 원하는 정보를 획득하고 객체를 생성할 수 있는 등의 기능을 제공한다. 하지만 JVM 내부적으로 관리하는 Klass는 개발자들에게 친숙한 Class와는 다른 개념이다.
JVM은 내부적으로 빌드를 하고 클래스를 로딩할 때, 클래스에 대한 메타데이터가 필요한데, 클래스 파일에서 뽑아내는 클래스의 정보가 바로 Klass인 것이다. JVM은 얻어낸 Klass 정보를 바탕으로 자바를 위한 복제본 혹은 미러(mirror)를 생성하는데, 이것이 바로 Class 객체로 자바에 반환되는 것이다.
klass word는 모든 클래스가 공유하는 메타데이터 정보이기 때문에 JVM Metaspace라는 별도의 영역에서 저장 및 관리된다.

이러한 객체의 헤더 부분이 메모리 상에서 어떻게 구성되는지를 쉽게 표현하면 다음과 같다. 마크 워드는 메타데이터로 힙 내부에 존재하지만, 클래스 워드는 클래스 정보를 가리키는 포인터이기에 최종적으로 메타스페이스 영역을 향한다.

배열의 길이
자바 배열의 경우 배열 길이도 객체 헤더에 저장한다. 객체 헤더에 저장되는 객체 타입은 배열에 담긴 ‘원소’의 타입에 해당한다. 따라서 배열 길이까지 알아야 배열 객체가 차지하는 메모리 크기를 제대로 계산할 수 있다. 배열의 길이 정보는 해당 객체가 배열이 아니라면 존재하지 않는다. 따라서 객체 헤더의 길이는 배열 유무에 따라 달라질 수 있다.
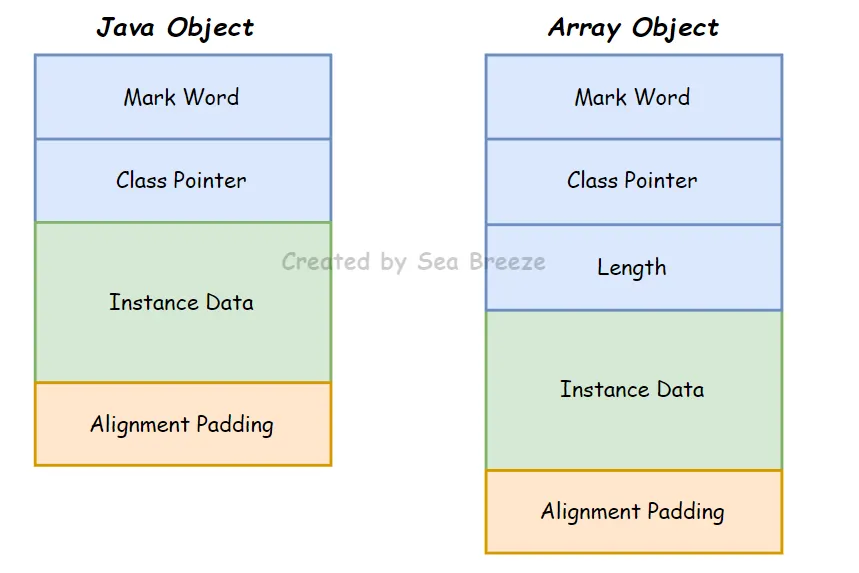
인스턴스 데이터와 정렬 패딩
객체 레이아웃의 두 번째 부분인 인스턴스 데이터는 객체가 실제로 담고 있는 정보다. 예컨대 프로그램 코드에서 정의한 다양한 타입의 필드 관련 내용, 부모 클래스 유무, 부모 클래스에서 정의한 모든 필드가 이 부분에 기록된다. +XX:ComactFields 매개 변수를 true로 설정하면(기본값이 true임) 하위 클래스의 필드 중 길이가 짧은 것들은 상위 클래스의 변수 사이사이에 끼워 넣어져서 공간이 조금이나마 절약된다.
정렬 패딩 부분은 존재하지 않을 수도 있으며, 특별한 의미 없이 자리를 확보하는 역할만 한다. 핫스팟 가상 머신의 자동 메모리 관리 시스템에서 객체의 시작 주소는 반드시 8바이트 정수배여야 한다. 달리 말하면 모든 객체의 크기가 8바이트의 정수배여야 한다는 뜻이다. 따라서 인스턴스 데이터가 조건을 충족하지 못하는 경우에만 패딩으로 채운다.
[ synchronized와 함께 동적으로 변하는 마크 워드 ]
기본적인 마크 워드의 구조
마크 워드가 차지하는 크기는 (참조 압축 기능을 켜지 않으면) 32비트 가상 머신에서는 32비트이고, 64비트 가상 머신에서는 64비트이다. 그리고 앞서 설명하였듯 64비트 JVM 기준에서 마크 워드의 구조는 다음과 같다.
┌───────────────────────────────┬─────────────────────────┬────┬────┐
│ Unused │ Hash Code │Age │Lock│
│ (27b) │ (31b) |(4b)│(2b)│
└───────────────────────────────┴─────────────────────────┴────┴────┘
하지만 현실적으로 객체는 아주 많은 런타임 데이터를 필요로 해서, 모든 것을 헤더에 담을 수 없다. 따라서 주어진 한정된 메모리를 최대한 효율적으로 사용해야 하는데, 이를 위해 마크 워드의 데이터 구조는 동적으로 의미가 달라지게 된다.
경량 락(Thin Lock)의 사용
자바 언어는 한 번에 하나의 스레드만 실행해야 하는 임계 영역을 손쉽게 지정할 수 있도록 synchronized 키워드를 제공한다. synchronized는 monitor 기반의 동기화 메커니즘(monitor)를 통해 동시성 상황을 제어한다. 이때 자바는 내부적으로 최적화를 통해, synchronized 블록일지라도 단일 스레드가 접근하는 케이스와 멀티 스레드가 접근하는 케이스를 다르게 대응한다.
아직 객체가 synchronized 블록에 진입하지 않아 잠금되지 않은 경우에는 마크 워드의 마지막 두 비트가 01 값을 가진다. 그러다가 스레드가 synchronized 영역에 진입하면 현재 스택 프레임에 락을 위한 락 레코드가 생성된다. 이후 JVM은 CAS(Compare-And-Swap) 연산을 통해 객체의 마크 워드에 있는 정보를 락 레코드에 저장하고, 마크 워드에는 락 레코드의 포인터를 넣으면서 잠금 bit를 00으로 바꾸어 객체 정보를 백업하게 된다. 이러한 잠금 방식을 경량 락(Thin Lock)이라고 하며, 잠금이 걸린 객체를 경량 잠금된 객체(Lightweight Locked Object)라고 한다.
┌──────────────────────────────────────────────────────────────┬────┐
│ Lock Record Pointer │Lock│
│ (62b) │(2b)│
└──────────────────────────────────────────────────────────────┴────┘
만약 이 연산이 실패하면 객체가 이미 잠겨있다는 것이므로, JVM은 먼저 마크 워드가 현재 스레드의 메서드 스택을 가리키는지 검사한다. 만약 그렇다면 자신 스레드가 해당 객체의 락을 소유하고 있다는 것이므로 안전하게 실행을 계속할 수 있다. 만약 동일한 스레드가 연속적으로 synchronized를 만난 재귀적 잠금 케이스라면, 락 레코드는 객체의 마크 워드 대신 0으로 초기화하여 이미 현재 스레드가 잠금을 소유중임을 나타낸다.
만약 다른 스레드가 해당 객체의 synchronized 블록에 접근하지 않으면, 이 상태로 잠금이 해제된다. 대부분의 경우 단일 스레드만 synchronized 영역에 접근하고 나가기 때문에, 경량 략까지만 사용된다. 하지만 다른 스레드가 접근하면 상황이 달라지는데, 이 상황이 되면 확장 락(Inflate Lock)을 사용하게 된다.
확장 락(Inflate Lock)의 사용
현재 스레드가 객체의 락을 소유하지 않아서 CAS 연산에 실패했다면, 새로운 스레드가 synchronized 블록에 진입했음을 의미한다. 그러면 자바는 기존의 경량 락을 확장 락으로 확장시키는데, 이제서야 비로소 스레드가 잠금 해제까지 대기하는 무거운 모니터(Heavyweight monitor) 기반의 블로킹(blocking) 방식으로 동작하게 된다. 그리고 해당 시점에는 잠금 비트가 10으로 설정된다.
자바가 내부적으로 경량 락(Thin Lock)과 확장 락(Inflate Lock)을 분리시킨 이유는 대부분의 객체가 하나의 특정 스레드에 의해서만 잠기고 잠금이 해제되기 때문이다. 즉, 지금까지의 내용을 요약하면 보통 단일 스레드가 synchronized에 접근하고 나가기 때문에, 먼저 CAS 방식(스핀락)으로 처리하다가, 다른 스레드가 진입하면 블로킹 방식으로 확장시킨다는 것이다.
제거된 편향 비트(Deprecated Biased Bit)와 잠금 비트(Lock Bit)의 구분
편향 락(Biased Locking)은 JVM 내부에서 사용되는 동기화 관련 최적화 기법 중 하나로, “한 스레드가 계속 같은 객체에 대해 락을 획득한다면, 매번 락/언락하는 것이 아니라 그 스레드에게 잠금을 편향시키자”는 개념이다. 참고로 해당 기능은 Java 15 부터 성능과 복잡도의 이유로 기본적으로 제거되었고, Java 19에서 완전히 제거되었다. 따라서 중요하지 않은 내용이니 넘어가도 좋다.
과거에는 마크 워드에 편향 락 여부를 표시하는 비트가 존재했다. 만약 클래스에 대한 편향 락이 활성화되어 있다면, 처음 한 스레드(A)가 synchronized 블록에 진입한 후 JVM은 마크 워드에 “이 객체는 스레드 A에게 편향되었음(biased)”을 기록한다. 이후 스레드 A는 같은 객체를 락 경쟁 없이 빠르게 사용할 수 있다. 그러다가 다른 스레드(B)가 해당 객체를 사용하려고 하면, 그때 편향 해제(revocation) 과정이 발생하면서 다음 락 처리 과정이 진행된다.
편향 락은 첫 번째로 락을 획득 시도할 때, 원자적 CAS 연산을 사용하여 락을 걸게 된다. 그러면 현재 스택 프레임에 락을 위한 락 레코드가 생성되며, 기존 마크워드 정보를 락 레코드에 저장하게 된다. 이후 마크 워드에는 스레드의 ID를 저장시키면서, 편향 비트를 활성화(1)시킨다, 이때 잠금 비트는 01 상태로 유지된다. 이렇게 설정된 객체는 해당 스레드에 편향(biased)되었다고 말하며, 이후 동일한 스레드에 의한 잠금과 잠금 해제는 원자적 연산이나 마크 워드 업데이트가 필요하지 않다. 심지어 스택에 있는 락 레코드는 편향된 객체에 대해서는 절대 검사되지 않으므로, 초기화되지 않은 채로 남아 있다.
이후 다른 스레드가 편향된 객체의 synchronized에 접근하면, 해당 객체는 편향이 해제되며 일반적인 방식으로 잠긴 것처럼 보여져야 한다. 따라서 편향을 소유한 스레드의 스택을 탐색하고, 객체와 관련된 락 레코드들을 다음 락 처리 방식(경량 락, Thin Lock)에 맞게 조정한 후, 가장 오래된 락 레코드를 객체의 마크 워드에 설치한다. 이 작업을 위해 모든 스레드는 일시 중지되어야 하며, 객체의 해시 코드(identity hash code)에 접근할 때도 편향이 취소되며, 이는 해시 코드 비트가 스레드 ID와 공유되기 때문이다.
JVM은 클래스를 로딩하거나 초기화를 할 때, “이 클래스의 인스턴스들이 편향 락을 사용할 수 있다”고 표시한다. 이후 이 클래스의 인스턴스가 synchronized 블록에 접근하게 되면, 편향 락의 유/무에 따라 잠금 메커니즘이 동작하게 되는 것이다.
이렇듯 잠금에는 여러 단계가 존재하는데, 이를 그림으로 표현하면 다음과 같다. 그리고 마크 워드는 이러한 기법을 통해 작은 공간에 가능한 한 많은 정보를 담고, 객체 상태에 따라 공간을 재활용할 수 있게 되었다. 참고로 아래의 그림은 과거 편향 락이 존재하던 시절의 그림이라 현재의 JVM 마크 워드 구성과 일부 다를 것이다.

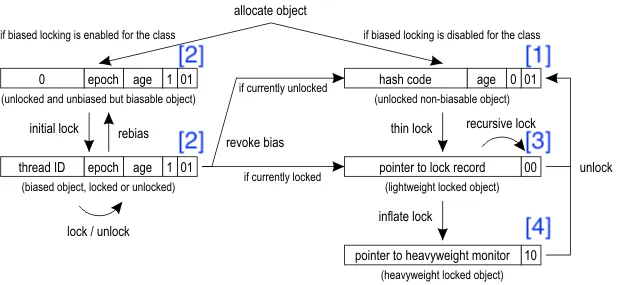
앞서 설명하였듯 자바에서 객체의 크기를 구하려면 기본적으로 객체의 헤더 크기에 변수의 크기(원시 타입인 경우) 또는 참조의 크기(참조 타입인 경우)를 더해주어야 한다.
관련 포스팅
- JVM 내부의 힙 객체 헤더(Heap Object Headers on JVM Internals)
- 힙 객체 헤더의 비효율과 이를 줄이기 위한 새로운 자바 객체 헤더(New Java Object Header: Compact Object Headers)
참고 자료
- https://www.infoq.com/articles/inline-classes-java/
- https://wiki.openjdk.org/display/HotSpot/Synchronization#Synchronization-Agesen99
- https://wiki.openjdk.org/display/HotSpot/Synchronization
- https://dev.to/dayanandaeswar/how-to-estimate-java-object-size-1jgp
- https://dzone.com/articles/whats-wrong-with-small-objects-in-java
- https://www.baeldung.com/jvm-compressed-oops
