
티스토리 뷰
1. 제품은 가설의 조합이다.
[ 될 놈 그리고 안될 놈]
기업으로서의 구글은 실패가 혁신의 불가피한 부산물임을 알고 있기에 관대하게 실패를 그대로 인정해준다. 하지만 구글의 직원 개개인은 분명 실패를 두려워 하고 있었고, 대부분은 이미 성공했거나 잘 알려진 제품 관련 부서에서 일하는 쪽을 선호했다. ‘성공’ 하면 떠오르는 사람이 되고 싶고, 실패는 피하고 싶기 때문이다.
하지만 모두가 성공한 제품에서 일할 수는 없으며, 우리는 계속해서 시장에 새로운 제품을 출시해야 한다. 현실은 다음과 같기에 실패를 존중하는 편이 이롭다.
대부분의 신제품은 시장에서 실패한다. 유능하게 실행해도 마찬가지다.
대부분의 제품이 실패하는 이유는 처음부터 제품 아이디어가 잘못되었기 때문이다. 우리는 제품을 제대로 만들지만, ‘될 놈’을 만들지 않는 것이다. 시장에 맞지 않는 것으로 밝혀질 제품에 시간과 노력, 능력을 낭비한 것이다. 시장에서 성공하는 몇 안 되는 아이디어에는 공통점이 있는데, 바로 처음부터 ‘될 놈’이라는 점이다.
제대로 만들기 전에, ‘될 놈’을 만들어라.
[ 직접 수집하는 데이터의 필요성 ]
광범위한 시장조사에도 불구하고 실패했던 수 많은 제품을 뜯어보니, 이들은 대부분 실제 시장을 조사한 게 아니라 상상 혹은 생각 속에서 시장 조사된 것이었다. 가령 ‘이러한 제품이 있다면 쓰실건가요?’와 같은 질문들은 모두 상상속에서 내린 의사결정이기에 시장을 조사한 것이 아니다.
생각만으로는 제품이 ‘될 놈’인지 아닌지 결정할 수 없기에, ‘될 놈’은 실제 세상에서 실험을 통해 발견되어야 한다. 그렇지 못하면 ‘안 될 놈’에 과잉 투자하거나 ‘될 놈’을 계속 추진하지 못하는 등의 오판을 내릴 수 있다. 아이디어 전달 문제, 예측력 문제, 적극적 투자가 없다는 문제, 확증 편향 문제를 고려하면, 아이디어의 성공 가능성을 오판할 방법은 너무나 많기에, 성공 여부는 반드시 데이터로 판단해야 한다.
구글의 핵심 운영 원칙 중 하나로 ‘의견보다 데이터(Data Beats Opinions)’가 있다. 의사결정 과정을 위한 데이터는 몇 가지 핵심 기준을 충족시켜야 한다.
- 신선함: 데이터는 따끈따끈한 것이어야 하며, 새로 나온 것일수록 더 좋다. 몇 년 전에는 진실이었던 것이 지금은 아닐 수도 있기 때문이다. 사람들의 태도나 기대가 휙휙 빠르게 바뀌는 첨단기술 사업이나 온라인 세상에서는 특히 그러하다.
- 확실한 관련성: 해당 데이터는 지금 평가하려는 특정 제품이나 의사 결정에 직접적으로 적용할 수 있어야 한다. 당연하다고 생각할 수 있지만, 실제 의사결정 과정에는 별 연관성 없는 데이터가 자주 끼어든다.
- 알려진 출처: 의사결정을 내릴 때 다른 기업에서 혹은 다른 프로젝트를 위해 수집된 데이터에 의존해서는 안 된다. 그들이 데이터 수집과 필터링 과정에서 어떤 기법이 사용되었는지, 어떤 편향이나 영향력, 동기가 작용했을지 알 수 없다.
- 통계적 유의성: 데이터는 통계적으로 유의미하며, 우연에 좌우되지 않도록 충분히 큰 샘플을 사용해야만 한다. 따라서 개인적인 경험이나 일회성 이야기를 데이터로 제시하지 마라. 구글에서는 “일화는 데이터가 아니에요”라는 합창을 듣게 된다.
다른 이들의 데이터에 의존해 내 아이디어의 성공 여부를 결정해서는 안 된다. 그런 유혹이 일겠지만, 이는 게으르고 위험한 시도다. 왜냐하면 다른 이들의 데이터는 ‘다른 사람이, 다른 프로젝트를 위해, 다른 시기에, 다른 곳에서, 다른 방법과 다른 목적으로 수집하고 편집한 모든 시장 데이터’이기 때문이다. 그들의 경험과 결과, 데이터가 여러분의 아이디어에도 반드시 적용되리라는 법은 없다. 물론 전적으로 무시하라는 뜻은 아니고, 배울 수 있는 부분이 있다면 배워가야 한다.
따라서 우리의 아이디어를 검증하기 위한 데이터는 반드시 직접 수집해야 하며, ‘신선하고, 관련성이 있고, 믿을 만하고, 통계적으로 유의미’해야 한다.
[ XYZ 가설 세우기 ]
데이터를 수집해야 하는 이유는 우리의 제품이 ‘될 놈’인지 판단하기 위함이며, 그 기준이 바로 가설이다. 린 스타트업에서 강조하는 요소 중 하나는 가설을 검증할 수 있는 최소한의 기능이 포함된 제품, 즉 최소 기능 제품이다. 따라서 제품은 가설의 조합으로 이뤄져야 한다.
구글에는 ‘모호한 용어를 피하고 가능하다면 늘 숫자를 사용하라’는 습관이 있다. ‘의견보다 데이터’가 더 중요하다면 그 데이터를 표현하는 최고의 방법은 ‘숫자로 이야기’하는 것이다. 가령 ‘회원가입 버튼을 조금 더 넓게 만들면 클릭을 좀 더 받을 수 있을 것 같아.’ 보다는 ‘회원가입 버튼을 20퍼센트 더 넓게 만들면 가입자가 최소 10퍼센트는 늘 것 같아.’와 같이 검증 가능한 가설이 좋다. 따라서 모든 가설은 다음의 ‘XYZ 가설’로 표현되어야 한다.
적어도 X 퍼센트의 Y는 Z할 것이다.
X는 타겟 시장의 구체적 퍼센티지, Y는 타겟 시장을 명확하게 설명하는 말, Z는 시장이 우리의 아이디어에 어떤 식으로 호응할 것 같은지에 대한 기대를 나타낸다. X, Y, Z는 경험에 기초한 추측에서부터 시작하면 된다. 물론 최초 숫자는 근사치조차 못 미칠 수 있지만, 실험을 통해 조정해나가며 ‘애매모호함’을 제거하는 것이 좋다.
Y의 범위가 너무 크다면, 가설의 범위를 좁혀 들어감으로써 ‘당장 실행 가능하고 검증 가능한’ 가설을 얻어야 한다. 예를 들어 “적어도 10퍼센트의, 대기질지수가 100 이상인 도시에 사는 사람들은, 120달러짜리 휴대용 오염 탐지기를 구매할 것이다.”와 같은 가설은 출발점이 되기에는 너무 크다. 즉, ‘검증 가능’하지 않기에 타겟 범위를 적절한 크기의 여러 가설들로 축소시킬 필요가 있다. 하나의 XYZ 가설이 좁은 범위 여러 개의 xyz 가설들로 분할되는 것이다.
[ 빠른 실행을 통한 가설 검증 ]
데이터를 확보하고 가설을 검증하려면, 일단 제품을 만들어야 한다. 전통적으로 제품은 “기획-생산-판매”의 순차적인 프로세스로 만들어졌다. 과거에는 시장이 기대하던 바가 비교적 명확했고, 그런 기대를 만족시킬 수 있는 좋은 품질의 제품을 만들기만 하면 고객은 기꺼이 돈을 지불했다.
하지만 이 같은 성공 방정식은 더 이상 유효하지 않다. 고객의 취향이 굉장히 세분화됐고, 기획과 생산 단계에 아무리 많은 노력을 기울이더라도 막상 제품을 시장에 내놓기 전까지는 이 제품이 성공할지 확신하기 어렵다. 많은 시간과 노력을 투자해서 만든 제품이 알고 보니 아무도 원하지 않는 제품이라는 점을 뒤늦게 발견하는 것만큼 나쁜 일은 없다.
따라서 아이디어를 빠르게 제품으로 만들고, 고객이 제품에 대해 어떻게 반응하는지를 측정한 후, 그 결과를 통해 배움을 얻고 지속적으로 제품을 개선해 나가는 “린 스타트업” 방법론이 필요하다. “아이디어-개발-측정-개선”으로 이어지는 피드백 순환고리(feedback loop)를 최대한 빨리 진행하면서 작은 성공을 쌓아 서비스를 점진적으로 개선해야 한다. 아무도 원하지 않는 제품을 오랜 기간 열심히 만드는 것은 어리석은 일이다. 처음부터 무작정 제품의 완성도를 높이는 데 시간과 노력을 투자하지 말고, 빠른 출시와 지속적인 개선을 통해 점진적으로 완성도를 높여야 한다.
실행할 때에는 다음의 4가지 전략들에 기초하여 실행하는 것이 바람직하다. 실패는 두렵지만 빠르게 마주하고 검증할수록 우리에게 이롭다.
- 생각은 글로벌하게, 테스트는 로컬하게
- 내일보다는 오늘 테스트하는 게 낫다
- 싸게, 더 싸게, 제일 싸게 생각하라
- 고치고 뒤집고 다 해보고 그만둬라
[ 낭비하지 말고 학습하라 ]
오늘날 우리는 물건을 만드는 데 효율성을 과시하지만, 우리 경제는 여전히 믿을 수 없을 정도로 낭비가 심하다. 이러한 낭비는 일을 비효율적으로 해서 발생하는 것이 아니라 산업 차원에서 하지 않아도 될 일을 하기 때문에 발생한다. 사람의 시간 오용을 하는 것은 인간 창의력과 잠재력을 부주의하게 낭비하는 죄이다. 노동자에게 더 열심히 일하라고 촉구하는 것은 불충분하다. 현재 우리는 잘못된 일을 너무 열심히 하고 있으며, 기능적 효율성에 초점을 맞추다가 혁신의 진정한 목표를 놓쳤다. 혁신의 목표는 현재 모르는 것을 학습하는 것이다.
2. 데이터 분석을 통해 ‘될 놈’ 찾기
[ 제품-시장 적합성(PMF, Product-Market Fit) ]
현실에서는 리소스나 일정 상의 제약이 있기 때문에, 첫 출시에는 계획했던 모든 기능을 담을 수 없다. 그러다 보니 서비스 출시 후 기대만큼의 반응이 없는 경우 “아직 계획했던 만큼의 기능이 완성되지 않아서”라고 합리화를 하고, 일단 신규 기능을 추가하는 경우가 많다. 하지만 안타깝게도 이 판단은 이 시점에 할 수 있는 최악의 선택이다. 미래를 알 수는 없지만 몇 개의 새로운 기능을 추가한다고 해서 이러한 문제가 해결되지 않을 확률이 훨씬 더 높다. 일단 지금 상황에서의 문제는 무엇일까? 그건 바로 “무엇이 문제인지를 모르겠다는 것”이다.
먼저 우리의 제품을 아무도 원하지 않는데, 우리가 계속해서 만들고 있을 수 있다. 따라서 우리는 먼저 ‘우리의 제품이 강력히 시장 수요를 충족시키는가?’ 즉, 제품-시장 적합성(Product-Market Fit, PMF)을 찾아야 한다. 만약 우리의 제품이 PMF를 만족하지 못한다면, 아무도 원하지 않는 제품을 만들고 있을 뿐이다. PMF를 찾았는지 확인할 수 있는 방법은 리텐션 플래토(Retention Plateau)의 생성 여부를 보는 것이다.
흔히 유지율이라고 부르는 리텐션(Retention)은 사용자들이 특정 서비스에 얼마나 꾸준히 남아서 활동하는지에 대한 지표다. PMF를 만족하는 서비스는 초기 일정 기간이 지나면 그래프의 기울기가 완만해지면서 리텐션이 안정적으로 유지되는 패턴을 보이는데, 이렇듯 시간이 지남에도 불구하고 리텐션이 평평하게 유지되는 구간이 리탠션 플래토다. 아래의 그림에서 초록색 제품은 PMF를 찾았기에 일정 수준으로 리텐션이 유지되며 리텐션 플래토가 생성된 반면, 파란색 제품은 그렇지 못했다.
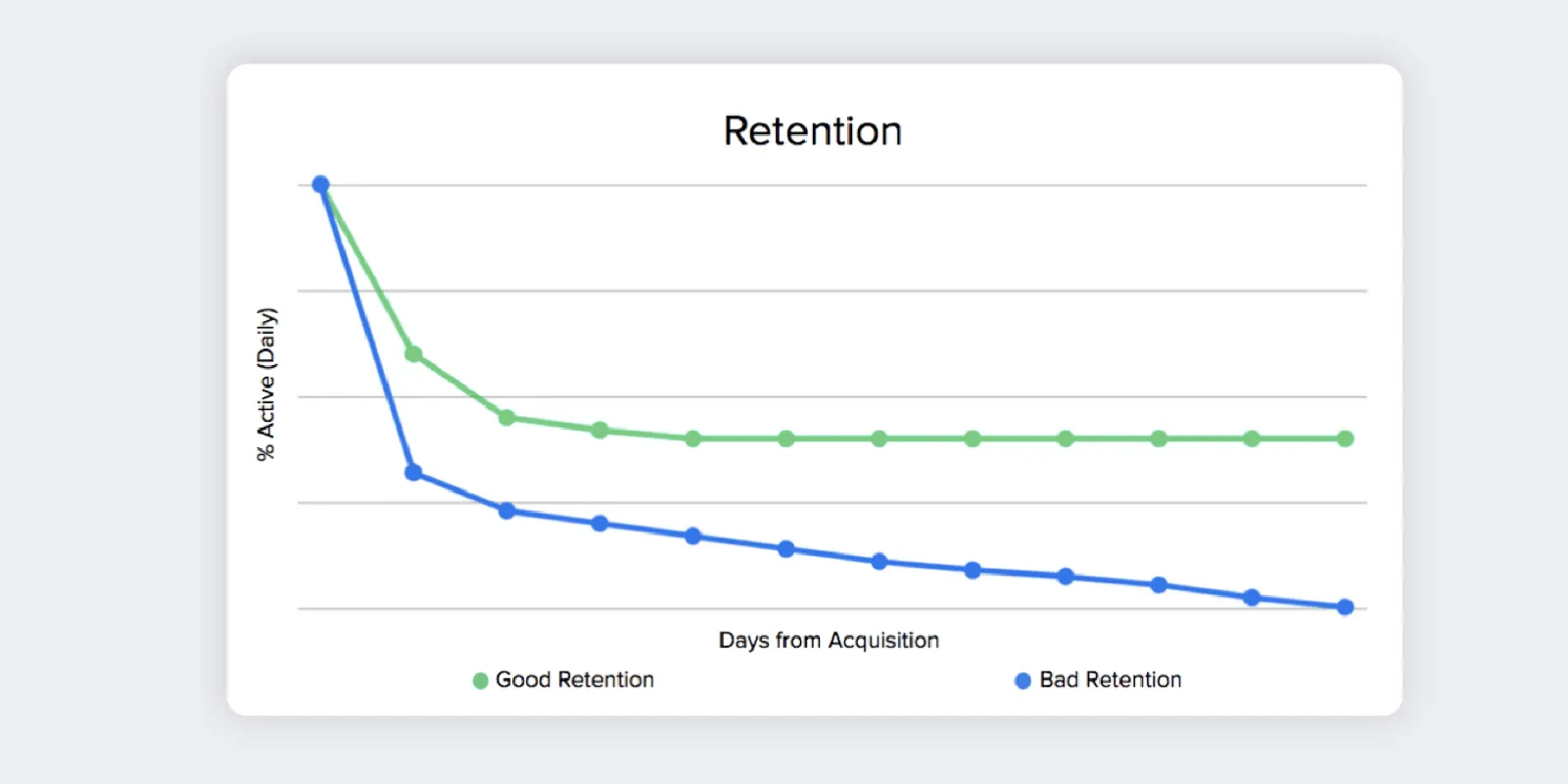
리텐션 플래토가 생성되었다는 것은 제품에 소비자의 가치가 존재하므로 계속해서 방문하게 된다는 것이다. 따라서 우리는 시장 뿐만 아니라 고객들까지 찾은 것이다. 이렇듯 리텐션은 매우 중요한 지표인데, 리텐션에 영향을 미치는 핵심 기간은 서비스를 사용하기 시작한 직후부터 수 일 이내다. 따라서 서비스 온보딩 과정을 주의깊게 챙길 필요가 있다.
그 외에도 전환율을 보아야 한다. 전환율(Conversion Rate)은 한 단계에서 다음 단계로 넘어가는 사용자의 비율을 의미한다. 서비스의 핵심 사용 경로에 대한 전환율 지표를 확인하는 것은 PMF를 점검하기에 유용하다. 참고로 전환율은 해당 사용자가 어떻게 인입되었는지에 따라 차이를 보일 수 있다.
마지막으로 순수 추천 지수(Net Promoter Score, NPS) 역시 볼 수 있다. NPS는 소비자로 하여금 이 서비스의 추천 정도를 평가하도록 하여 획득하는 지표이다. 이는 결국 서비스에 대한 만족도를 상징하는데, 실제로 신규 서비스의 성공을 가늠할 수 있는 좋은 방법은 충성 사용자를 살펴보는 것이다. 서비스를 적당히 좋아하는 1000명의 사용자보다는 서비스를 열렬히 사랑하는 100명의 충성 사용자를 확보했을 때 그 서비스가 성공할 확률이 크게 높아진다.
만약 PMF를 찾지 못했다면, 우리의 제품이 ‘될 놈’이 아니기에 반복된 과정을 통해 PMF를 찾아갈 필요가 있다. 물론 PMF를 찾아서 리탠션 플래토가 형성되었더라도, 그 수치가 너무 낮다면 다시 피봇할 필요도 있다. 첫 번째 아이디어는 ‘안 될 놈’이었더라고 몇 군데만 손보면 ‘될 놈’이 될지도 모른다. 그러니 테스트하고, 고치고, 반복해야 한다.
[ 사용자 분석과 UT ]
PMF를 찾았는데 리텐션 플래토가 지나치게 낮게 형성되었다고 하자. 이때 우리는 브레인스토밍을 통해 새로운 제품을 기획하거나, 미뤄뒀던 새로운 기능을 추가하거나 잔존율이나 전환율을 개선하는 기능을 추가해서는 안 된다. 예를 들어 ‘푸시 기능’은 제품의 리텐션과 전환율을 높여주겠지만 결국 PMF를 찾은 것은 아니므로, 일시적으로 지표를 높일 수는 있어도 결국 회귀하게 될 것이다. 따라서 리텐션과 전환율은 PMF를 찾고 난 이후의 결과로 봐야 하며, 이 지표 자체를 개선하는 것을 지금 해서는 안 된다. 대신 분석과 조사를 먼저 해야 한다.
유지 그룹에 대한 Data Analysis
리텐션 플래토가 생겼기에 우린는 이탈하는 사용자와 남는 사용자를 구분해서 바라볼 필요가 있다.
먼저 서비스에 남는 사용자들은 제품의 핵심 가치를 통해 아하 모먼트(Aha Moment)를 경험했기 때문인데, 아하 모먼트를 경험한 유저의 95%는 지속된 리텐션을 보인다고 한다. 예를 들어 페이스북의 경우 ‘가입 후 10일 이내에 7명의 친구와 연결시키는 것’이 아하 모먼트였으며, 사용자가 몇 억명이 모일 때까지 유효했다고 한다.
따라서 최대한 인입되는 사용자들이 아하 모먼트를 경험할 수 있도록 해야 한다. 참고로 아하 모먼트를 경험시켜서 약 20~30%의 상승률을 높일 수 있는데, 이는 은탄환(Silver-Bullet)이 아님에 유의해야 한다.
이탈 그룹에 대한 Usability Test
우리는 UT(Usability Test)를 통해 이탈하는 사용자들을 이해해야 한다. 이들이 이탈하는 이유는 우리의 서비스가 그들의 유스케이스를 충족시켜주지 못했기 때문일 것이다. 따라서 UT의 결과는 리텐션을 높여서 리텐션 플래토를 형성하는 데 도움을 주지 못할 것이다.
대신 이미 리텐션 플래토를 형성했고 리텐션을 높이는 데 한계에 도달한 상황에서, 새로운 유스케이스를 추가하여 진입되는 사용자의 수를 늘리고 또 다른 제품으로 리텐션을 쌓는 데 활용될 수 있다. UT는 이어서 살펴볼 CC를 상승시켜 MAU를 높일 수 있기 때문에 매우 중요하다. 우리는 UT를 통해 우리가 채워주지 못하는 부분을 이해하고, 어떤 부분을 개선해야 하는지 확인해야 한다.
[ Carrying Capacity ]
우리가 여러 가지 개선들을 통해 어느 정도 제품이 갖춰진 상황에서, 우리의 서비스가 성장할 수 있는 최종 종착지 혹은 최대MAU를 측정할 수는 없을까?
호수의 물이 차오를 수 있는 높이는, 유입되는 물의 양과 소실되는 비율에 결정된다. 우리의 서비스 역시 마찬가지다. 호숫가의 물을 사용자의 집합이라고 보면, 이는 인입되는 사용자의 수(Inflow)와 나가는 비율(Churn)에 따라서 결정될 것이다.
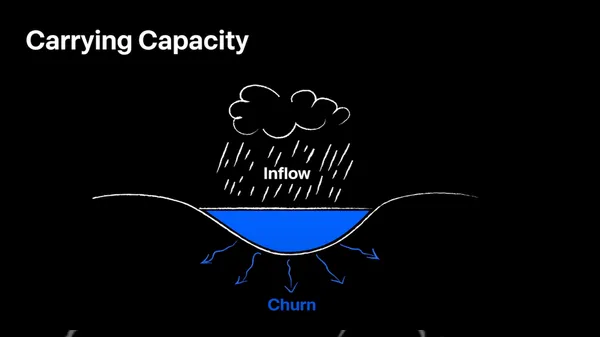
여기서 인입은 광고나 푸시, 마케팅 등을 걷어냈을 때를 기준으로 계산해야 한다. 오가닉하게 진입한 사용자들을 기준으로 우리의 서비스가 최종적으로 도달할 수 있는 사용자의 수가 바로 CC(Carrying Capacity)인 것이다. 참고로 여기서 인입되는 숫자와 다르게 나가는 비율인 이유는, 이탈이라는 것은 남아있는 수에 비례하여 결정되기 때문이다.
CC = number of New Daily Customers / percentage of lost customers each day
예를 들어 매일 7500명이 인입되고 1%의 비율로 빠져나가는 서비스라고 하면, 우리의 서비스가 도달할 수 있는 사용자의 수는 75만명인 것이다. 물론 마케팅이나 광고 등의 효과로 일시적으로 이 수치를 넘어설 수 있겠지만, 결국 CC를 향해 귀신같이 복구될 것이다.
이를 통해 우리는 인입되는 사용자의 수 뿐만 아니라 이탈하는 사용자의 비율(Churn Rate) 역시 중요함을 깨달을 수 있다. 만약 CC의 개선에 한계를 부딪힌 상황이라면, 새로운 제품으로 CC를 더하는 것도 CC를 개선하는 방법이니 참고하도록 하자.
[ AARRR ]
ARRRR은 스타트업의 성장을 위해 관리해야 하는 주요 지표들의 모음이다. 우리는 고객 유치(Acquistion), 활성화(Activation), 리텐션(Retention), 수익화(Revenue), 추천(Referral)의 다섯 가지 주요 지표들을 모니터링하고 관리해야 한다.
고객 유치(Acquistion)
고객 유치는 사용자를 우리 서비스로 데려오는 것과 관련된 활동을 의미한다. 유입 효과를 판단하기 위한 장소 정보를 소스(Source)라고 하며, facebook, instagram 등이 소스에 해당한다. 반대로 매체(Medium)는 유입 방식으로, email, cpc(클릭 광고) 등이 존재한다. 똑같은 내용이라도 강조하는 메시지가 다를 수 있는데, 이를 캠페인(Campaign)이라고 한다. 예를 들어 전단지의 절반은 "30% 할인"이라는 캠페인을 강조하고, 나머지 절반은 "3개월 등록 시 1개월 무료"라는 캠페인을 강조하는 것이다.
웹에서의 유입 경로 확인을 위해서는 URL 뒤에 파라미터를 붙이는 UTM 파라미터가 가장 널리 활용된다. 하지만 모바일 앱에서 링크를 클릭한 후 앱스토어로 이동한 다음에 앱을 설치하고 실행하면, 그 과정에서 UTM 파라미터가 유실되기에 모바일 앱에서는 어트리뷰션(Attribution)이라는 개념이 사용된다. 어트리뷰션 서비스들은 클릭을 통해 앱스토어로 이동한 사용자와 스토어에서 앱을 설치하고 실행한 사용자를 기술적으로 매핑한 다음, 어떤 클릭이 앱 설치와 가입에 더 많이 기여했는지 확인할 수 있게 한다.
일반적으로 고객 유치를 위해 앱 안의 특정 화면으로 이동하는 딥 링크(Deep Link)가 사용된다. 앱을 설치한 사용자들이 딥 링크를 클릭하면 웹 브라우저 대신 모바일 앱이 실행되면서 앱 내의 적합한 랜딩 페이지가 보여지는 것이다. 하지만 딥 링크는 링크를 클릭하는 사람의 휴대폰에 해당 앱이 설치돼 있을 때만 정상적으로 동작하기에, 고도화된 디퍼드 딥 링크가 사용된다. 디퍼드 딥 링크는 앱이 설치돼 있는 사람은 곧바로 해당 앱의 랜딩 페이지로 이동시키고, 앱이 설치돼 있지 않은 사람은 스토어로 이동해서 앱을 설치하게 한 후 앱을 실행하면 그때 미리 정의한 랜딩 페이지로 이동시킨다. 디퍼드 딥 링크를 사용하면 사용 맥락을 유지시킨다는 장점 외에도 어트리뷰션의 측정 범위가 넒어진다는 장점이 있다.
고객 유치 과정의 핵심은 고객 유치에 기여(Attribution)한 채널의 성과를 판단할 수 있는 모델을 만드는 것이다. 각 채널별 데려온 사용자 수 뿐만 아니라 꾸준한 활동 여부, 결제로 전환되는 비율 등을 바탕으로 각 채널의 가치를 정확히 판단하고, 이를 통해 전체적인 마케팅 전략을 수립하거나 예산을 분배해야 한다. 따라서 자발적으로 우리 서비스를 찾아오는 고객(Organic)과 비용을 통해 마케팅으로 우리 서비스를 찾아온 고객(Paid)을 나누어 보아야 한다. 참고로 ‘Direct’ 혹은 ‘Organic’이라는 의미는 ‘자발적으로 우리 서비스를 찾아온’이 아닐 수 있다. 왜나하면 해당 정보가 유실될 경우 정확한 식별이 불가능하기 때문이다. 따라서 유입 채널을 정확하게 추적하고, 성과를 정확히 판단할 필요가 있다.
고객 유치 성과 측정을 위해서 고객 획득 비용(Customer Acquisition Cost, CAC)이 활용될 수 있는데, 이는 한 명의 사용자를 데려오기 위해 지출하는 평균 비용을 의미한다. 고객 획득 비용 활용의 핵심은 채널별, 캠페인별, 광고별, 날짜별 데이터를 쪼개서 보는 것이다. 이를 통해 “어느 채널에 얼마의 기간 동안 어느 캠페인으로 얼마의 예산을 집행할 것인가” 확인하여 보다 구체적이고 체계적인 예산 수립을 할 수 있을 것이다.
활성화(Activation)
고객 유치를 통해 데려온 사용자가 우리 서비스의 핵심 가치를 경험하게 만드는 것이 중요하다. 따라서 사용자 중심의 아하 모먼트를 파악하고 이를 경험하게 해야 한다. 이를 위해 이탈 사용자들이 어느 단계에서 이탈하는지 퍼널 전환율을 분석해야 한다
전환율 지표는 사용자를 여러 그룹으로 쪼개서 볼 때 훨씬 더 강력한 의미를 지닌다. 이처럼 특성에 따라 여러 집단으로 분류한 사용자 그룹을 코호트(Cohort)라고 한다. 코호트 별로 전환율을 나누어 살펴보면 각 퍼널에 영향을 미치는 선행지표를 발견하기 쉬워진다. 퍼널 분석의 진정한 가치는 주요 퍼널에서의 단편적인 전환율을 계산하는 데 있는 것이 아니라 전환율에 영향을 미치는 유의미한 선행지표를 발견하는 데 있다. 결국 우리는 “전환된 사용자와 전환되지 않은 사용자는 무엇이 다른가?”를 발견해야 한다.
리텐션(Retention)
리텐션은 활성화 과정을 통해 경험한 핵심 가치를 꾸준히 경험하게 하는 수준이다. 리텐션은 일반적으로 접속을 기준으로 하는데, 보통 접속이나 로그인을 기준으로 하는 이유는 그 것이 유의미한 행동이며, 이러한 행동이 반복되는지 살펴보는 것이 중요하기 때문이다.
리텐션을 측정하는 방법으로는 클래식 리텐션 또는 Day N 리텐션(특정 일에 이벤트를 발생시킨 유저의 비율)과 범위 리텐션(특정 기간에 이벤트를 발생시킨 유저의 비율), 롤링 리텐션(더 이상 해당 이벤트가 발생하지 않는 비율) 등이 존재한다. 그 외에도 DAU / MAU로 계산하여 약식으로 보는 리텐션 지표인 인게이지먼트(Engagement)도 존재한다. 이를 통해 매일 동일한 사용자가 반복적으로 들어오는지 혹은 날마다 새로운 사용자가 들어오는지를 가늠할 수 있다.
리텐션은 쪼개서 볼 때 의미 있기 때문에 코호트에 따라 살펴볼 필요가 있으며, 일반적으로 날짜를 기준으로 나누어 살펴본다. 만약 리텐션은 초기에 리텐션이 떨어지는 속도를 늦추거나, 안정화된 이후 기울기를 평평하게 유지해야 한다.
리텐션은 아주 어렵게 개선하더라도 그 효과가 한참 뒤에나 나타나며, 특히 잘 하고 있을 때일수록 더 세심하게 측정하고 관리해야 한다.
수익화(Revenue)
수익화와 관련해서는 여러 가지 지표들이 존재한다.
- 인당 평균 매출(ARPU, Average Revenue Per User): 시작과 끝이 있는 특정 기간에 대한 지표로, 통상 월 기준으로 집계함, 월 매출 / MAU로 구할 수 있음
- 결제자 인당 평균 매출(ARPPU, Average Revenue Per paying User): ARPU와 유사하지만 전체 사용자가 아닌 “결제자”만을 대상으로 함
- 고객 생애 가치(Lifetime Value, LTV): 한 명의 사용자가 진입한 순간부터 이탈하는 순간까지의 전체 활동 기간에 누적해서 발생시키는 수익
- 고객 생애 매출(Lifetime Revenue, LTR): 고객 생애 가치를 계산하기 위해서는 매출과 비용을 모두 계산해야 하지만 고객 생애 매출을 계산할 때는 비용을 고려하지 않은 값
고객 생애 매출은 전체 회원을 대상으로 하는 하나의 지표 보다는 “가입 시점”으로 코호트를 나누고, 코호트별로 고객 생애 매출의 추이 변화를 살펴보는 편이 훨씬 더 유용하다. 이처럼 기간 별로 고객 생애 매출이 증가하는 추이를 구한 후 고객 획득 비용(Customer Acquisition Cost, CAC)과 비교하여 서비스의 수익 모델이 잘 동작하고 있는지, 마케팅 비용을 적절하게 사용하고 있는지 등을 확인할 수 있다. 건강하게 성장하고 있는 서비스라면 LTR이 CAC를 빠르게 따라잡고 장기적으로 CAC의 몇 배수까지 높아져야 한다.
멜론, 넷플릭스와 같이 월별 이용금액을 지불하는 서비스라면, 월별 반복 매출(Monthly Recurring Revenue, MRR) 지표를 볼 수 있고, 그 과정에서 다음과 같이 여러 요소들로 나누어 분석할 수 있다.
- 기준(Base) MRR: 전월 기준 매출
- 신규(new) MMR: 신규 고객으로 인해 증가한 매출
- 이탈(Chrun) MRR: 기존 고객 이탈로 인해 감소한 매출
- 업그레이드(Upgrade) MRR: 기존 고객 대상 크로스셀(cross-sell), 업셀(up-sell)로 인해 증가한 매출
- 다운그레이드(Downgrade) MRR: 기존 고객의 요금제 하향조정(plan downgrade)로 인해 감소한 매출
수익화 지표는 개인별 편차가 상당히 크기 때문에, 수익화의 성패는 고수익 창출 유저들(고래, whale)에 달려있다. 따라서 요약된 수익화 지표와 함께 사용자를 다양한 방식으로 그루핑하고 각 그룹에 맞는 운영 및 수익화 전략을 세워야 한다. 서비스 출시 초기에는 수익 모델이 포함되지 않아도 수익화에 대한 로드맵은 명확하게 존재해야 한다. 매출은 특정 부서의 역할 혹은 책임이 아니라 서비스를 만들고 운영하는 모든 사람들이 함께 해야 한다.
3.6 추천(Referral)
추천은 오가닉(Organic) 유입의 하나로, 기존 사용자의 추천이나 입소문을 통해 새로운 사용자를 데려오는 것을 의미한다. AARRR에서 이야기하는 추천은 일회성 이벤트 보다는 “서비스 내에 입소문을 통해 선순환 구조를 어떻게 구축할 것인가”라는 구조적인 문제에 더 가깝다. 일반적으로 친구 초대에 대한 보상은 유료 마케팅 채널을 통한 고객 획득 비용의 50~70% 수준에서 결정되는 경우가 많다.
각 서비스는 바이럴 계수(Viral Coefficient)를 통해 추천 엔진이 얼마나 효과적으로 동작하는지 확인할 수 있다.
바이렬 계수 = 사용자 수 * 초대 비율 * 인당 초대한 친구 수 * 전환율 / 사용자 수
추천 시스템의 효과를 분석할 때는 바이럴 계수와 함께 초대 주기를 꼭 고려해야 한다. 초대 주기를 빠르게 만들어서 같은 기간에 더 많은 사이클을 돌릴 수 있다면 추천 효과를 극대화할 수 있을 것이다. 또한 목표 시장에서의 포화도(Sature) 수준과 함께, 추천으로 유입된 사용자의 장기적인 경험 수준은 바이럴 계수에 잘 드러나지 않는다는 점도 유의해야 한다.
아무리 추천으로 많은 사용자를 불러와도 활성화와 유지율이 잘 준비되지 않으면 의미 없는 지출만 하게 될 것이다. 실제로 AARRR의 주창자인 데이브 맥클루어는 활성화와 유지율을 가장 우선적으로 개선하고, 그다음으로는 고객 유치와 추천을 개선하고, 마지막으로 수익화를 챙겨야 한다는 얘기한다.
오늘날 AI가 빠르게 발전하고 있고, 개발자의 입장에서 코드 작성에 대한 가치는 폭락하고 있다. 그렇다면 우리는 어떠한 대응을 해나가야 할까?
대부분의 전문가들은 1인 창업의 시대가 도래할 것으로 보고 있다. 혼자서 개발도 하고, 기획도 하고, 데이터도 분석하면서, 제품 전략과 방향성을 결정하는 것이다. 대용량 트래픽으로 인한 최적화나 장애 대응 등이 필요하면 고급 엔지니어가 필요할 수 있다. 하지만서비스 초기에는 많은 트래픽도 없고, 될 놈인지 일단 빠르게 검증하는 것이 중요하기에, 이는 꽤나 현실적으로 보인다.
따라서 우리는 문제 상황에서 빠른 해결력 뿐만 아니라 제품을 올바르게 기획하고 준비할 수 있는 능력을 두루 갖추어야 할 필요가 있다. 이를 위해 우리는 적어도 프로덕트에 가까워지고, 관련 지식들을 배우고, 학습할 필요가 있다.
물론 좋은 제품을 기획하는 사람이 되는 것은 차원이 다르고, 좋은 제품을 기획하기 위해서는 또 많은 학습이 필요하다. 하지만 먼저 이러한 용어들에 친숙해지고, 업무 환경에서 PO들의 업무 진행을 보면서 이러한 부분에 대해 감을 익히는 것만으로도 큰 도약을 해냈다고 생각한다.
다음은 대표적인 좋은 제품 전략을 위해 도움이 되는 글들의 일부이다.
- What are Some Decisions Made by the “Growth Team” at Facebook that Helped Facebook Reach 500 Million Users?
- 바이럴은 과학이다 (Effects of Viral Coefficient, Retention Rate, and Cycle Time on Viral Expansion)
- Business Development In Silicon Valley Is Now API-Centric, Not People-Centric
특히나 ‘바이럴은 과학이다’ 글은 바이럴 계수와 확산 등에 대한 개념을 설명하는데, 바이럴의 바이러스 감염 사이클과 3가지 중요 사항에 대해 설명한다. 매우 중요한 내용이니, 해당 포스팅을 직접 참고하도록 하자.
- 한 명의 감염자가 한 명을 초과하여 감염시켜야 한다
- 바이러스에 감염된 고객이 감염상태로 머물러야 한다
- 몇 명을 감염시키느냐 보다 얼마나 빠른 시간내에 감염시키는가가 더 중요하다
참고 자료
- 린 스타트업
- 그로스 해킹
- 아이디어 불패의 법칙
- 토스 PO 세션 유튜브
- https://slate.com/human-interest/2012/05/what-are-some-decisions-made-by-the-growth-team-at-facebook-that-helped-facebook-reach-500-million-users.html
- https://organicmedialab.com/2015/09/30/effects-of-viral-coefficient-retention-rate-and-cycle-time-on-viral-expansion/
'나의 공부방' 카테고리의 다른 글
| [Image] 소벨 필터(Sobel Filter)란? (1) | 2026.03.17 |
|---|---|
| [Slack] 슬랙봇 DM 및 채널 메시지 연동하여 운영 자동화하기 (0) | 2025.02.11 |
| [개발서적] 구글 엔지니어는 이렇게 일한다 핵심 내용 정리 및 요약 (8) | 2024.12.10 |
| [Tool] 유용한 MacOS 앱 및 크롬 익스텐션(Chrome Extensions) 정리 (7) | 2024.10.29 |
| [개발서적] 단위 테스트(Unit Testing) 핵심 내용 정리 및 요약 (16) | 2024.10.15 |
