
티스토리 뷰
이직을 하게 되면서, 기존에 자바만 사용하다가 처음으로 코틀린을 사용하게 되었다. 코틀린으로 작성된 코드를 읽는데, 지나치게 kotlin-specific 한 문법들이나 인지 부하를 초래하는 코드들로 인해 코드가 전혀 읽히지 않았다. 그래서 코틀린 공식 문서를 포함하여 책 3권 및 코틀린 관련 많은 영상들을 참고하여, 코틀린을 입문할 때 알면 좋은 내용들을 정리하였다.
1. 자바 개발자가 코틀린을 입문할 때 알면 좋은 내용들 모음
[ 코틀린 공통 ]
코틀린의 설계 목적
컴퓨터가 인식할 수 있는 코드는 바보라도 작성할 수 있지만,
인간이 이해할 수 있는 코드는 실력 있는 프로그래머만 작성할 수 있다.
- 마틴 파울러(Martin Fowler), 리팩터링 -
“개발자가 코드를 작성하는 데는 1분 걸리지만, 이를 읽는 데는 10분이 걸린다"
- 로버트 마틴(Robert Martin), 클린 코드 -
프로그래밍에서는 쓰기 보다 읽기가 중요하므로, 항상 가독성을 생각해서 코드를 작성해야 한다. 코틀린 역시 간결성이 아닌, 가독성(readability)을 높이는 데 목표를 두고 설계된 프로그래밍 언어이다.
가독성이란 코드를 읽고 얼마나 빠르게 이해할 수 있는지를 의미하는데, 이는 우리의 뇌가 얼마나 많은 관용구(구조, 함수, 패턴)에 익숙해져 있는지에 따라 다르다. 다음 중 어떤 것이 더 좋은 코드일까?
// 구현 A
if (person != null & person.isAdult) {
view.showPerson(person)
} else {
view.showError()
}
// 구현 B
person?.takeIf {it.isAdult }
?.let(view::showPerson)
?: view.showError()
코틀린 초보자에게는 일반적인 관용구를 사용하는 A가 더 읽고 이해하기 쉬울 것이고, 코틀린 숙련자라면 구현 B를 쉽게 읽을 것이다. 하지만 숙련된 개발자만을 위한 코드는 좋은 코드가 아니며, 구현 A와 B는 비교조차 할 수 없을 정도로 A가 훨씬 가독성 좋은 코드이다. 또한 구현 A는 구현 B보다 수정(if 블록에 작업을 추가하는 경우) 및 디버깅도 쉽다. 이처럼 일반적이지 않고 “굉장히 창의적인” 구조는 유연하지 않고 지원도 제대로 받지 못한다.
따라서 기본적으로 “인지 부하”를 줄이는 방향으로 코드를 작성해야 하며, 그 이유로 뇌는 짧은 코드를 빠르게 읽을 수 있겠지만, 익숙한 코드는 더 빠르게 읽을 수 있기 때문이다.
코틀린의 컴파일러(Kotlin Compiler)
코틀린 컴파일러는 JVM에서 실행될 수 있는 바이트코드가 포함된 클래스 파일을 생성하는 것이지, 자바 코드를 생성하는 것이 아니다. 만약 자바 소스 코드를 생성했다면 코틀린 트랜스파일러가 더욱 바람직한 이름이었을 것이다.
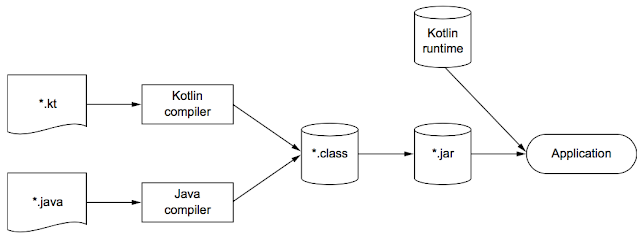
코틀린은 자바 컴파일러가 아닌 코틀린 컴파일러에 의해 컴파일 되기 때문에 자바를 사용할 때와 다른 부분이 있다. 대표적으로 체크 예외를 잡아서(catch) 핸들링 여부를 검사하는 부분이 있다. 자바에서는 체크 예외와 언체크 예외를 구분하고, 체크 예외가 던져지면(throws) 이를 반드시 잡거나 다시 던져야 한다. 하지만 이는 자바 컴파일러가 검사하는 기능이며, 코틀린에서는 모든 예외를 언체크 예외로 인식한다. 따라서 던져지는 체크 예외를 핸들링하지 않아도 코틀린에서는 문제가 되지 않는다. 이러한 컴파일러의 차이에 의해 구현 레벨에서도 다른 부분이 있다.
불변성(Immutability)
코틀린은 변경 가능성보다 불변성을 선호하며, 기본적으로 모든 것이 불변이다. 클래스 역시 final로 선언되며 변수들 역시 기본적으로 불변이다. 따라서 초기화 후에 변경되지 않는다면 var이 아닌 val을 사용해야 하며, 컬렉션의 경우에도 가능하면 불변 컬렉션 인터페이스를 사용할 것을 권장한다.
null 처리를 위한 안전 호출(safe call)과 엘비스 연산자(Elvis operator)
코틀린은 기본적으로 null을 허용하지 않는다. 따라서 null은 중요한 메시지를 전달하는 데 사용되어야 하며, 다른 개발자가 보았을 때 의미 없는 경우에 null을 사용하지 말아야 한다. 클래스 생성 이후에 확실하게 값이 설정된다면 lateinit과 notnull 델리게이트를 사용할 수 있다.
만약 null을 반환할 가능성이 있다면 다음과 같이 타입 뒤에 ?를 붙여서 표현한다.
fun length(): Int? = null
null인 경우를 위해 안전 호출(safe call)과 엘비스 연산자(Elvis operator)를 제공한다.
안전 호출은 값이 널이면 null을 반환하고, null이 아닐 경우에만 호출을 진행한다. 호출을 통해 반환된 값이 null인 경우, null이 아닌 기본값을 반환하기를 원하는 경우를 위해서는 elvis 연산자를 제공한다. 안전 호출 결과의 추론 타입도 nullable 타입이므로, 엘비스 연산자와 함께 사용하는 것이 좋다.
// middle이 null일 경우 0을 반환
// middle이 not-null일 경우 length를 호출함
// length 호출 결과가 null일 경우 0을 반환
// length 호출 결과가 not-null일 경우 호출한 값을 반환
var p = Person(first = "North", middle = null, last = "West")
val middleNameLength = p.middle?.length ?: 0
또한 연쇄 호출을 묶을 때(Wrap chained calls)는 다음 줄에 . 또는 ?를 한 줄 들여쓰기로 넣는 것을 권장한다.
val anchor = owner
?.firstChild!!
.siblings(forward = true)
.dropWhile { it is PsiComment || it is PsiWhiteSpace }
원시 타입(primitive type)과 래퍼 타입(wrapper type)
코틀린은 원시 타입(primitive type)과 래퍼 타입(wrapper type)을 구분하지 않는다. 항상 래퍼 클래스를 사용하면 성능적으로 비효율적이므로, 최대한 효율적인 방식으로 동작하고자 노력하였다.
대부분의 경우 코틀린의 Int 타입은 자바 int 원시 타입으로 컴파일 된다. 하지만 null을 반환하거나 컬렉션과 같은 제네릭 클래스를 사용하는 등의 이유로, 원시 타입으로의 컴파일이 불가능하면 래퍼 타입을 사용한다.
// int 원시 타입으로 컴파일 됨
fun getAge(): Int {
return 15
}
// Integer 래퍼 타입으로 컴파일 됨
fun getAge(): Int? {
return null
}
if와 when 문법
코틀린은 가독성 높은 분기 처리를 위해 when 문법을 제공한다. 이진 조건에서는 when 보다 if 사용을 권장하며, 3개 혹은 그 이상의 선택지가 주어진 경우에 when의 사용을 권장한다.
if (x == null) ... else ...
when (x) {
ACTIVE -> // ...
INACTIVE -> // ...
ELSE -> // ...
}
플랫폼 타입(Platform Type)
코틀린에서 다른 프로그래밍 언어(대표적으로 자바)를 호출해야 하는 경우가 있다. 코틀린은 기본적으로 not-null 그리고 불변 속성에 해당하지만 자바는 그렇지 않은데, 이로 인해 다른 프로그래밍 언어에서 호출된 타입이 nullable 한지 코틀린의 입장에서는 알 수 없다.
따라서 nullbale 여부를 알 수 없는 경우에 String! 처럼 타입 이름 뒤에 ! 기호를 붙여서 표기하는 타입을 플랫폼 타입이라고 한다. 물론 ! 기호가 타입에 직접 드러나지는 않지만 코드 힌트에 드러난다.
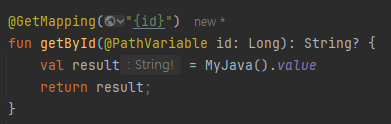
플랫폼 타입을 알아야 하는 이유는 값을 활용할 때 NPE가 나기 때문이며, 만약 직접 조작할 수 있는 자바 코드라면 @Nullable과 @Notnull을 붙여주어 해결하는 것이 좋다.
public class MyJava {
public String getValue() {
return null;
}
}
class MyJavaTest {
@Test
fun statedType() {
// stated 타입은 값을 가져올 때 NPE가 발생하므로 null 객체를 쉽게 파악 가능
val value: String = MyJava().value
println(value.length)
}
@Test
fun platformType() {
// platform 타입은 값을 활용할 때 NPE가 발생함
val value = MyJava().value
println(value.length)
}
}
네임드 아규먼트(Named arguments)
코틀린은 메서드가 동일한 타입의 매개변수가 많은 경우 네임드 아규먼트를 사용할 것을 권장한다. 또는 단위를 명확히 알 수 없는 경우에도 적합하다. 이를 통해 자바에서 롬복 기반의 빌더 패턴에 대한 단점을 거의 극복할 수 있다.
sleep(100) // sleep 단위를 알 수 없음
sleep(timeMillis = 100) // sleep 단위를 알 수 있음
drawSquare(x = 10, y = 10, width = 100, height = 100, fill = true)
object 키워드
object 키워드는 싱글턴을 매우 간단하게 정의하도록 도와준다. 이를 통해 매번 반복되는 싱글턴 클래스의 구현을 만들어주지 않아도 된다.
object StringUtils {
fun toLowerCase(input: String): Boolean {
return input.toLowerCase()
}
}
코틀린은 클래스 내부에 선언할 수 있는 companion object도 제공하는데, 이를 통해 상수 등을 선언할 수 있다. 즉, 인스턴스 메서드는 아니지만 어떤 클래스와 관련된 메서드와 팩터리 메서드를 담을 때 쓰인다.
@Service
class SignUpService {
fun signUp(input: SignUpInput) {
delaySignUp(DELAY_MINUTES)
}
companion object {
private const val DELAY_MINUTES: Long = 5
}
}
by 대리자
다른 클래스의 인스턴스가 포함된 클래스를 만들고, 그 클래스에 연산을 위임하려면 by 키워드를 사용할 수 있다. 코틀린에서 by 키워드는 포함된 객체에 있는 모든 public 함수를 해당 객체를 담는 컨테이너를 통해 노출시킬 수 있다. 이러한 by 대리자는 일급 객체를 사용하는 경우에 매우 유용하다.
예들 들어 다음과 같이 카드 목록을 포함하는 일급 객체가 있다고 할 때, by 대리자 문법을 활용해 컬렉션에 연산을 위임시키면 용이하다.
data class Cards(
val cards: List<Card>,
) : List<Card> by cards {
fun hasActiveCard(user: User): Boolean {
return cards.any{ it.status == CardStatus.ACTIVE }
}
}
val isEmpty = cards.isEmpty()
lazy 대리자
어떤 속성이 필요할 때까지 해당 속성의 초기화를 지연시키고 싶은 경우 lazy 키워드를 사용할 수 있다. 참고로 lazy 대리자의 속성을 전달할 수 있는데, 기본값은 SYNCHRONIZED이다. 각각의 속성은 다음의 특징을 갖는다.
- SYNCHRONIZED: 오직 하나의 스레드만 Lazy 인스턴스를 초기화할 수 있게 락을 사용함
- PUBLICATION: 초기화 함수가 여러 번 호출될 수 있지만 첫 번째 리턴값만 사용됨
- NONE: 락이 사용되지 않음
일반적인 코틀린 대리자는 표준 라이브러리의 Delegate 인스턴스의 일부인데, lazy는 그 자체로 최상위 함수라는 점에서 특징적이다.
data class Student(
val name: String,
var score: Int,
) {
val emptySize: Int by lazy(LazyThreadSafetyMode.SYNCHRONIZED) {
println("@@@@@@Initialize by lazy")
score
}
}
연산자 오버로딩
코틀린은 덧셈, 뺄셈, 나눗셈 등과 같은 산술 연산자 오버로딩 기능을 제공한다. 연산자 오버로딩은 연산의 키워드 앞에 operator 키워드를 붙여주면 구현할 수 있으며, 우선순위는 기본 연산자에 대한 우선순위와 동일하다. 참고로 피연산자 타입은 동일하지 않아도 되며, 코틀린은 교환 법칙(a op b == b op a)을 제공하지도 않는다.
data class Point(val x: Int, val y: Int) {
operator fun plus(other: Point): Point {
return Point(x + other.x, y + other,y)
}
}
코틀린은 산술 연산자 오버로딩 뿐만 아니라 여러 가지 오버로딩 키워드를 제공하는데, 정리하면 다음과 같다. 해당 내용을 숙지하기 보다는 필요할 때 찾아보는 형태로 인지하도록 하자.
- 산술 연선자 오버로딩
- a + b: plus
- a - b: minus
- a % b: mod
- a / b: div
- a * b: times
- 단항 연산자 오버로딩
- +a: unaryPlus
- -a: unaryMinus
- !a not
- ++a, a++: inc
- —a, a—: dec
- get/set 연산자 오버로딩
- val num = p[1]
- p[1] = num
- in 연산자 오버로딩
- in 연산자는 컬렉션에 객체가 들어있는지 검사함, CONTAINS에 대응됨
- a in c ⇒ c.contains(a)
- 비교 연산자 오버로딩
- 동등 연산자: override 키워드를 붙여주면 자동으로 상위 클래스의 operator 지정이 적용됨, equals로 컴파일
- 바교 연산자: Comparable 인터페이스의 compareTo를 호출하는 방식으로 컴파일됨
참고로 코틀린은 plus와 같은 연산자를 오버로딩 하면 그와 관련된 복합 대입 연산자(+=)도 함께 지원한다. 만약 해당 연산이 객체에 대한 참조를 다른 참조로 바꾸기보다 원래 객체의 내부 상태를 변경하게 만드려면 plusAssign, timeAssign 등을 사용할 수 있다.
- a += b → a = a.plus(b)
- a += b → a.plusAssign(b)
plus와 plusAssign 연산 모두를 제공하면 컴파일이 두 방향으로 될 수 있으므로 동시에 정의 불가능하다. 또한 기본적으로 컬렉션에 대한 연산 역시 +는 새로운 컬렉션을 += 변경을 적용한 복사본을 반환하는 형태로 되어있다는 부분도 참고하면 좋다.
operator fun<T> MutableCollection<T>.plusAssign(element: T) {
this.add(element)
}
코틀린은 또한 Infix 키워드를 통한 중위 연산자를 제공하는데, 해당 예시 코드는 다음과 같다.
infix fun Int.plus(n: Int): Int {
return this + n
}
fun main() {
println(5 plus 10)
}
코틀린은 상당히 편리하게 마법같은 기능들을 사용할 수 있게 해주지만, 해당 기능을 과도하게 사용하는 것은 새로운 개발자로 하여금 새로운 런닝 커브와 인지 부하를 초래할 수 있다. 따라서 항상 이러한 개념들을 적용할 때는 많은 부분들을 고려하고 트레이드오프 해야 한다.
[ 함수 ]
함수의 선언
코틀린은 백틱을 활용한 메서드와 변수의 선언을 제공하는데, 테스트에서는 이를 허용한다. 마찬가지로 밑줄을 이용한 선언도 테스트에서는 허용한다.
class MyTestCase {
@Test fun `ensure everything works`() { /*...*/ }
@Test fun ensureEverythingWorks_onAndroid() { /*...*/ }
}
함수의 이름과 관련해서는 다음과 같은 내용들에 충실하기를 권장한다.
- 메서드가 객체를 변경하는지 아니면 새 객체를 반환하는지도 이름에 명시해야 함
- 무의미한 Manager, Wrapper와 같은 이름도 지양해야 함
- 약어를 사용하는 경우 두 글자로 구성된 경우 대문자로, 더 긴 경우 첫 글자만 대문자로 표시함 ex) IOStream, HttpInputStream
class Members(
private val members: List<Member>
) {
// sort는 메서드가 객체를 변경함을 의미함
fun sort() {
members = members.sort()
}
// sorted는 메서드가 새로운 객체를 반환함을 의미함
fun sorted() {
return Members(members.sort())
}
}
expression body 표현식
코틀린은 간단한 함수라면 일반적인 block body가 아닌 expression body 사용을 권장한다. 만약 한 줄에 놓이지 않는다면 = 까지를 첫 줄에 두고, 나머지는 다음 줄로 분리하고 네 번 띄울 것을 권장한다.
fun foo(): Int { // bad
return 1
}
fun foo() = 1 // good
fun f(x: String, y: String, z: String) =
veryLongFunctionCallWithManyWords(andLongParametersToo(), x, y, z)
디폴트 파라미터(Default Parameter)
자바와 다르게 코틀린은 함수의 파라미터에 디폴트 값을 설정할 수 있는 기능을 제공한다. 이를 통해 불필요한 메서드 오버로딩을 줄일 수 있다.
// Bad
fun foo() = foo("a")
fun foo(a: String) { /*...*/ }
// Good
fun foo(a: String = "a") { /*...*/ }
자바 프로젝트를 코틀린으로 전환하다 보면 자바에서 코틀린 코드를 호출해야 하는 경우가 있다. 하지만 자바에는 디폴트 파라미터라는 개념이 없으므로, 자바에서 코틀린 함수를 호출하는 경우에는 모든 인자를 명시해야 한다. 만약 자바에서 코틀린 함수를 자주 호출해야 한다면 @JvmOverloads 애노테이션을 함수에 추가할 수 있다. 그러면 코틀린 컴파일러는 자동으로 맨 마지막 파라미터로부터 파라미터를 하나씩 생략한 오버로딩 메서드를 추가해준다.
함수형 메서드
코틀린은 자바보다 많은 함수형 메서드를 제공하는데, 이를 통해 생산성을 많이 높일 수 있다. 대표적으로 다음의 함수형 메서드들을 개발할 때 자주 사용하게 될 수 있다.
- withIndex: 인덱스와 값을 같이 순회하고 싶은 경우
- associate, associateWith: 특정 값을 기준으로 맵을 만들 수 있음
- ifEmpty: 컬렉션이 비어있는 경우 기본값 처리 가능
- sortedWith & compareBy: 다수의 속성으로 오름차순 정렬할 수 있음
- chunked: 컬렉션을 같은 크기로 나누고 싶은 경우
- windowed: 정해진 간격으로 컬렉션을 따라 움직이는 블록을 원하는 경우
- filterIsInstance, filterIsInstanceTo: 타입으로 컬렉션 필터링하기 원하는 경우
참고로 함수형 메서드의 람다 파라미터(Lambda parameters)는 짧고 중첩되지 않는 경우에는 관례로 it 키워드로 접근한다. 만약 중첩된 람다의 경우에는 파라미터를 명시해야 한다.
val result = listOf("A", "B").filter { it -> it.startsWith("A") } // it 생략 가능
val result = listOf("A", "B").filter { it.startsWith("A") }
모든 컬렉션 처리 메서드는 비용이 많이 든다. 표준 컬렉션 처리는 내부적으로 요소들을 활용해 반복을 돌며, 내부적으로 계산을 위해 추가적인 컬렉션을 만들어 사용한다. 시퀀스 처리도 시퀀스 전체를 랩하는 객체가 만들어지며, 조직을 위해서 또 다른 추가적인 객체를 만들어 낸다. 두 처리 모두 요소의 수가 많다면, 꽤 큰 비용이 들어간다. 따라서 적절한 메서드를 활용해서, 컬렉션 처리 단계 수를 적절하게 제안하는 것이 좋다.
시퀀스(Sequence)의 사용
코틀린은 Iterable 타입에 대해서도 filter, map과 같은 스트림 처리 연산을 제공한다. 하지만 Iterable은 처리 연산을 사용할 때마다 연산이 즉시 수행되어 새로운 컬렉션이 생성된다. 즉 아래의 경우 2번의 filter 연산을 위해 2번의 list가 새롭게 생성된 것이다.
val result = listOf("A", "B")
.filter { it.startsWith("A") }
.filter { it.startsWith("B") }
코틀린은 자바의 stream과 마찬가지로 성능 상의 이점을 위해 지연(lazy) 처리를 지원하는 sequence를 제공한다. 따라서 시퀀스의 처리 연산들을 사용하면, 데코레이터 패턴으로 꾸며진 새로운 시퀀스 리스트가 리턴되고, 최종적인 계산은 toList 또는 count 등의 최종 연산이 이루어질 때 수행된다.
val result = listOf("A", "B")
.asSequence()
.filter { it.startsWith("A") }
.filter { it.startsWith("B") }
이와 같은 시퀀스의 지연 처리는 다음과 같은 장점을 가진다.
- 자연스러운 처리 순서를 유지함
- 최소한만 연산함
- 무한 시퀀스 형태로 사용할 수 있음
- 각각의 단계에서 컬렉션을 만들어 내지 않음
하지만 컬렉션 전체를 기반으로 처리해야 하는 연산은 시퀀스를 사용해도 빨라지지 않는다. 현재 유일한 예로 코틀린 stdlib의 sorted가 있는데, sorted는 Sequence를 List로 변환한 뒤에, 자바 stdlib의 sort를 사용해 처리한다. 문제는 이러한 변환 처리로 인해서, 시퀀스가 컬렉션 처리보다 느려진다는 것이다. sorted를 빼야 한다는 의견도 있지만, 정렬 처리는 일반적으로 사용되는 처리이므로 시퀀스에도 들어간 것이다.
자바 스트림(Java Stream)과 코틀린 시퀀스(Kotlin Sequence)의 차이
자바 8의 스트림도 lazy 하게 작동하며, 마지막 처리 단계에서 연산이 일어난다. 다만 코틀린의 시퀀스와는 다음과 같은 세 가지 큰 차이점이 있다.
- 코틀린의 시퀀스가 더 많은 처리 함수를 갖고 있음(확장 함수를 사용해서 정의되어 있으므로), 그리고 사용하기 더 쉬움(이는 자바 스트림이 나온 이후에 코틀린 시퀀스가 나와서 몇 가지 문제를 해결했기 때문임). 예를 들어 최종 연산을 collect(Collectors.toList())가 아닌 toList()로 가능함
- 자바 스트림은 병렬 모드로 실행할 수 있음. 이는 멀티 코어 환경에서 굉장히 큰 성능 향상을 가져옴. 다만 몇 가지 결함이 있으므로 주의해서 사용해야 함
- 코틀린의 시퀀스는 코틀린 멀티 플랫폼에서 모두 사용할 수 있음. 하지만 자바 스트림은 코틀린/JVM에서만 동작하며, 그것도 JVM이 8버전 이상일 때만 동작함
이펙티브 코틀린의 저자는 병렬 모드로 성능적 이득을 얻을 수 있는 곳에서만 자바 스트림을 사용하고, 이외의 일반적인 경우에는 코틀린 시퀀스를 사용하는 것이 좋다고 한다. 코틀린 stdlib 함수를 사용하면, 모든 플랫폼에서 활용할 수 있는 공통 모듈의 코드가 더 깔끔해진다.
영역 함수(scope function)
영역 함수는 특정 객체의 컨텍스트 내에서 코드 블록을 실행하기 위한 함수들이다. 람다 표현식이 제공된 개체에서 영역 함수를 호출하면 임시 범위가 형성되며, 이 범위에서는 이름 없이 객체에 접근할 수 있다.
기본적으로 모든 영역 함수는 객체에서 코드 블록을 실행하는 동일한 작업을 수행하는데, 다른 점은 블록 내에서 이 객체를 사용하게 되는 방식과 전체 표현식의 결과이다. 다음은 영역 함수 중 let을 사용하는 예시 코드이다.
Person("Alice", 20, "Amsterdam").let {
println(it)
it.moveTo("London")
it.incrementAge()
println(it)
}
영역 함수를 이용함으로써 우리는 해당 연산들이 Person이라는 객체 내에서 수행됨을 손쉽게 파악할 수 있다. 만약 영역 함수가 없었더라면 변수 할당과 그에 대한 연산을 반복해야 했을 것이다.
val alice = Person("Alice", 20, "Amsterdam")
println(alice)
alice.moveTo("London")
alice.incrementAge()
println(alice)
영역 함수는 새로운 기술적 기능은 요구하지 않으며, 더욱 간결하고 가독성 높은 코드를 작성할 수 있게 해준다. 영역 함수들 간에는 유사점이 많아서 적합한 함수를 선택하는 것이 까다로울 수 있는데, 이에 대한 선택은 의도와 사용의 일관성에 따라 달라진다. 올바른 영역 함수를 선택하기 위해 다음의 차이점을 이해하면 좋다.
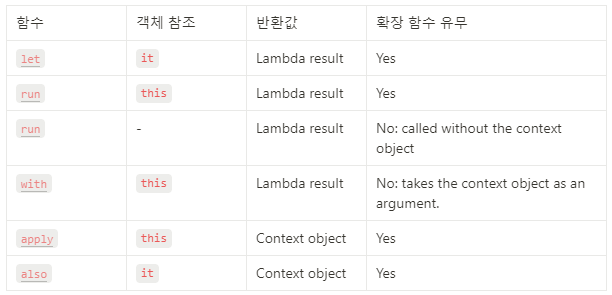
먼저 영역 함수의 컨텍스트 객체에 대한 참조가 람다 수신자(this) 인지 람다 인수(it)인지에 따라 다르다. 객체 참조가 람다 수신자(this)로 사용되면 this를 생략하여 코드를 간결하게 만들 수 있다. 하지만 이로 인해 인지 부하를 초래하여 혼란을 줄 수 있으므로, 주로 객체의 함수를 호출하거나 프로퍼티에 값을 할당하여 객체의 멤버에 대해 작업하는 람다에는 this를 사용할 것을 권장한다.
val adam = Person("Adam").apply {
age = 20 // same as this.age = 20
city = "London"
}
println(adam)
반대로 객체가 주로 함수 호출에서 인수로 사용되는 경우나 코드 블록에서 여러 변수를 사용하는 경우에는 람다 인수(it)로 객체를 참조할 것을 권장한다.
fun getRandomInt(): Int {
return Random.nextInt(100).also {
writeToLog("getRandomInt() generated value $it")
}
}
val i = getRandomInt()
println(i)
그 다음으로 영역 함수를 선택할 때 고려해야 하는 부분은 반환값이다. 반환값은 크게 컨텍스트 객체를 반환하거나 람다 결과를 반환할 수 있다.
컨텍스트 객체를 반환하면 계속해서 메서드 호출을 체이닝(chaining)할 수 있고, return 문에서도 사용될 수 있으므로 이러한 상황에서 용이하다.
val numberList = mutableListOf<Double>()
numberList.also { println("Populating the list") }
.apply {
add(2.71)
add(3.14)
add(1.0)
}
.also { println("Sorting the list") }
.sort()
fun getRandomInt(): Int {
return Random.nextInt(100).also {
writeToLog("getRandomInt() generated value $it")
}
}
val i = getRandomInt()
반면에 람다 결과를 반환하는 경우에는 결과를 새로운 변수에 할당하거나 반환값을 무시하고자 할 때 사용될 수 있다. 그러면 위의 내용들을 고려하여 구체적으로 각각의 영역함수를 사용하는 케이스들을 살펴보도록 하자.
val numbers = mutableListOf("one", "two", "three")
with(numbers) {
val firstItem = first()
val lastItem = last()
println("First item: $firstItem, last item: $lastItem")
}
let
- 호출 chain의 결과를 바탕으로 연산이 필요한 경우
- null이 아닌 값에 대한 연산이 필요한 경우(안전 호출 연산자와 결합되어)
- 제한된 범위의 로컬 변수를 도입하여 가독성을 높이는 경우
val numbers = mutableListOf("one", "two", "three", "four", "five")
numbers.map { it.length }.filter { it > 3 }.let {
println(it)
// and more function calls if needed
}
val str: String? = "Hello"
//processNonNullString(str) // compilation error: str can be null
val length = str?.let {
println("let() called on $it")
processNonNullString(it) // OK: 'it' is not null inside '?.let { }'
it.length
}
with
- "이 객체를 사용하여 다음을 수행합니다."로 코드를 읽기 쉽게 만들고 싶은 경우
- 값을 계산하는 데 사용되는 속성이나 함수가 있는 도우미 객체를 도입할 때
val numbers = mutableListOf("one", "two", "three")
with(numbers) {
println("'with' is called with argument $this")
println("It contains $size elements")
}
val numbers = mutableListOf("one", "two", "three")
val firstAndLast = with(numbers) {
"The first element is ${first()}," +
" the last element is ${last()}"
}
println(firstAndLast)
run
- 람다 내부에서 객체를 초기화하고 반환값을 계산하는 경우(확장 함수 run)
- 식이 요구되는 여러 문이 필요할 때, “코드 블록을 실행하고 결과를 계산하라”고 표현하고 싶은 경우
// 확장 함수인 경우
val service = MultiportService("<https://example.kotlinlang.org>", 80)
val result = service.run {
port = 8080
query(prepareRequest() + " to port $port")
}
// 확장 함수가 아닌 경우
val hexNumberRegex = run {
val digits = "0-9"
val hexDigits = "A-Fa-f"
val sign = "+-"
Regex("[$sign]?[$digits$hexDigits]+")
}
apply
- 값을 반환하지 않고 주로 수신자 객체의 멤버를 대상으로 작업하는 경우
- 대표적으로 객체를 구성할 때 사용되는데, “객체에 다음의 값을 할당하세요”라고 읽을 수 있음
- 복잡한 처리를 위해 여러 호출 체인(call chain)이 필요한 경우
val adam = Person("Adam").apply {
age = 32
city = "London"
}
println(adam)
also
- 객체에 대한 참조가 필요하거나 외부 스코프에 의해 this가 숨겨지기를 원치 않는 경우
- “객체에 대해 다음의 추가적인 작업을 수행합니다”라고 읽을 수 있는 경우
val numbers = mutableListOf("one", "two", "three")
numbers
.also { println("The list elements before adding new one: $it") }
.add("four")
확장 함수를 선택하는, 보다 짧고 명시적인 기준을 세우면 다음과 같다. 물론 사용 사례가 겹칠 수 있으므로 프로젝트 혹은 팀의 규칙에 따라서도 선택할 수 있다.
- null이 아닌 객체에서 람다 실행하는 경우: let
- 지역 범위(local scope) 에서 표현식을 변수로 도입하는 경우: let
- 객체를 구성하는 경우: apply
- 객체를 구성하고 결과를 실행하는 경우: apply
- 표현식이 요구되는 실행 문인 경우: 확장 함수가 아닌 run
- 부가적인 기능을 수행하는 경우: also
- 객체에 대한 함수 호출을 그룹핑하는 경우: with
그 외에도 takeIf와 takeUnless와 같은 문법도 제공하는데, 각각 다음과 같다.
- takeIf: 조건을 만족하면 해당 값을 반환하고, 그렇지 않으면 null을 반환함
- takeUnless: 조건을 만족하면 null을 반환하고, 그렇지 않으면 해당 값을 반환함
앞서 설명하였듯 코틀린은 가독성을 위해 설계된 프로그래밍 언어이며, 코틀린에 특수한 관용구를 많이 사용하는 코드는 인지부하로 인해 가독성을 낮출 수 있다. 따라서 일반적인 관용구를 중심으로 사용하되, 코틀린 전용 관용구를 사용하는 비용을 지불할 가치가 있는 경우에만 영역 함수와 같은 특수 문법을 사용하는 것이 좋다. 실제로 코틀린 공식 문서에서는 영역 함수를 사용하여 코드를 더 간결하게 만들 수 있지만, 코드를 읽기 어렵게 만들고 오류를 일으킬 수 있으므로 과도하게 사용하지 말 것을 권장한다. 또한 현재 컨텍스트 객체와 this 또는 it의 값을 혼동하기 쉬우므로, 영역 함수를 중첩하지 말고 연결(chaning)할 때는 주의하라고 한다.
최상위 함수 선언
자바에서는 하나의 자바 파일에 최소한 하나의 클래스가 존재해야 한다. 하지만 코틀린에서는 코틀린 파일에 클래스가 없어도 된다. 예를 들어 다음과 같이 코틀린 파일에 최상위 함수 혹은 속성을 선언할 수 있는 것이다.
var hehe = 10
fun getValue(): Any {
return 7
}
이것이 가능한 이유는 코틀린 컴파일러가 컴파일하면서 하나의 클래스를 정의하고, 이를 static 메서드와 static 변수로 바꾸기 때문이다. 따라서 무의미한 클래스를 정의할 필요 없이 간결하게 util성 클래스를 생성할 수 있다.
확장 함수 (Extension Function)
코틀린은 매우 유용한 확장 함수 기능을 제공한다. 확장 함수는 어떤 클래스의 멤버 함수(member function)인 것처럼 호출할 수 있지만, 그 클래스의 밖에 선언된 함수이다. 확장 함수는 함수 이름 앞에 확장할 클래스의 이름만 붙여주면 된다. 예를 들어 확장 함수는 다음과 같이 선언하고 사용할 수 있다.
fun String.getLengthMinusOne(): Int = this.length - 1
val myLength = "MangKyu".getLengthMinusOne()
확장 함수는 수신 객체를 첫 번째 인자로 받는 static 메서드로 컴파일하는 일종의 문법적 편의(syntatic sugar)라고 볼 수 있다. 따라서 클래스의 일부가 아니라 클래스 바깥에 선언되는 정적 메서드이므로 오버라이드할 수 없다.
코틀린은 이러한 확장 함수를 매우 잘 활용하고 있는데, 자바 표준 라이브러리를 간결하게 사용할 수 있게 감싼 래퍼 클래스를 제공하고 있다.
개인적으로는 특정 유스케이스에 종속적인데 도메인 모델의 프로퍼티만 활용한다면, 해당 유스케이스 내부에 확장 함수를 구현하여 사용하는 것이 좋은 것 같다. 예를 들어 다음과 같이 카드 발급에 대한 공통 속성은 User라는 도메인 클래스에 정의하고, 그 외에 “KB 카드는 21세 이상부터 발급 가능하다”는 특정 유스케이스에 종속적인 기능은 유스케이스 내부에 구현해주는 것이다. 이를 통해 코드를 보다 가독성 좋고 도메인이 풍부한 것처럼 작성할 수 있다.
data class User(
val userNo: Long,
val age: Int,
) {
fun canIssueCard(user: User): Boolean {
return user.age >= 20
}
}
@Service
class IssueKbCardService{
fun canIssueCard(user: User) {
return user.canIssueKbCard()
}
}
private fun User.canIssueKbCard(): Boolean {
return this.age >= 21
}
코틀린 코딩 컨벤션 공식 문서에서도 확장 함수를 자유롭게 사용하되, API 오염을 최소화하기 위해 확장 함수의 가시성을 최대한 제한할 것을 권장한다.
inline 함수와 reified 키워드
코틀린은 람다를 무명 클래스로 컴파일 한다. 그렇다고 람다 식을 사용할 때마다 새로운 클래스를 만들지는 않고, 람다가 변수를 포획하면 람다가 생성되는 시점마다 새로운 무명 클래스 객체가 생긴다.
따라서 람다를 사용하는 구현은 똑같은 작업을 수행하는 일반 함수를 사용한 구현보다 덜 효율적이다. 그래서 inline 키워드를 제공하는데, inline 키워드를 어떤 함수에 붙이면 컴파일러는 그 함수를 호출하는 모든 문장을 함수 본문에 해당하는 바이트코드로 바꿔친다.
하지만 파라미터로 받은 람다를 다른 변수에 저장하고 나중에 그 변수를 사용한다면 람다를 표현하는 객체가 어딘가는 존재해야 하기 때문에 람다를 인라이닝 할 수 없는 상황도 있다.
참고로 코틀린은 reified 키워드도 제공하는데, inline 함수에 적용되는 reified 키워드는 타입을 보존하기 위해 사용된다.
예외 처리
코틀린은 자바와 동일하게 try-catch 기반의 예외 처리 기법을 제공한다. 몇 가지 다른 점은 자바8에 등장한 try-with-resources 대신 use 키워드를 사용해 해당 기능을 대체할 수 있다는 점이다.
FileInputStream("file. txt").use {
print(it)
}
또한 코틀린은 try-catch 기반의 문법을 대신할 수 있는 runCatching과 같은 캡슐화 블록을 제공한다. 이를 통해 훨씬 가독성 좋은 코드를 작성하도록 장려한다.
private fun getResult(id: Long): String? {
return runCatching {
call(id)
}.onFailure {
log.info("데이터 조회에 실패했습니다.", it)
}.getOrNull()
}
[ 클래스 ]
파일의 구성
코틀린 파일이 단일 클래스나 인터페이스만을 갖는다면, 파일 이름은 클래스의 이름이 되어야 한다. 하지만 코틀린은 하나의 파일에 여러 클래스를 정의할 수 있으며, 만약 하나의 파일이 여러 클래스 혹은 최상위 선언만을 갖는 경우, 해당 내용을 설명하는 적절한 이름을 사용해야 한다.
따라서 소스 파일에 연관된 여러 개의 클래스, 최상위 함수 혹은 프로퍼티 등을 배치하는 것이 권장되며, 이때 몇 백 라인을 넘지 않도록 합리적인 크기를 유지해야 한다.
class Member(
val id: Long,
val name: String,
val status: MemberStatus,
)
enum class MemberStatus {
ACTIVE,
INACTIVE,
LEAVE,
}
그렇다면 무엇을 기준으로 클래스 파일을 나눌 것인지도 상당히 중요한데, 시스템의 비즈니스를 위한 도메인이 명시적으로 드러나기 위해 도메인 파일을 분리하는 것이 괜찮은 것 같다. 반면에 DTO 같은 경우에는 굳이 드러내지 않아도 되는 인프라 정보이므로 하나의 파일로 관리해도 괜찮은 것 같다.
참고로 파일 하나에 여러 클래스를 넣을 경우, Naming Refactoring 시에 해당 파일명이 변경 되지 않는 케이스가 발생할 수 있으므로 주의해야 한다.
클래스의 가시성
코틀린은 private와 internal 클래스를 선언할 수 있다. 대신 코틀린은 자바의 package-private 가시성을 제공하지 않는데, package-private 가시성을 적극 활용하는 입장에서는 조금 아쉬운 부분이다.
- private 클래스: 최종적으로 pakcage-private 클래스로 컴파일됨
- internal 클래스: 동일한 모듈(한 번에 컴파일되는 코틀린 파일들) 내에서만 호출이 가능하며, 최종적으로 public 클래스로 컴파일됨
클래스의 생성자와 초기화 블록
코틀린의 생성자는 크게 주 생성자(primary constructor)와 부 생성자(secondary constructor)로 나뉘어진다. 그리고 객체 생성 이후에 초기화 로직을 추가할 수 있는 초기화 블록을 제공한다.
- 주 생성자: 클래스를 초기화할 때 주로 사용하는 간략한 생성자, 클래스 본문 밖에서 정의함
- 부 생성자: 클래스 본문 안에서 정의함
- 초기화 블록: 초기화 로직을 추가할 수 있음, 객체가 생성될 때 실행됨. 주 생성자는 제한적이기 때문에 별도의 코드를 포함할 수 없으므로 초기화 블록이 필요함
// Primary constructor in the class header
class Person(val name: String, var age: Int) {
// Class body
}
// Secondary constructor
class Person {
var name: String
var age: Int
// Secondary constructor
constructor(name: String, age: Int) {
this.name = name
this.age = age
}
init {
require(name.length > 5)
}
}
프로퍼티 선언
코틀린의 주생성자에 선언된 변수를 프로퍼티라고 부르는데, 코틀린의 프로퍼티는 자바 필드와 비슷해보이지만 완전히 다르다. 코틀린의 프로퍼티는 개념적으로 접근자(게터, 세터)를 나타내며, 데이터를 저장하는 레퍼런스를 저장하는 필드는 내부적으로 별도로 존재한다.
따라서 변수를 val로 선언하면 getter 메서드가 만들어지며, var로 선언하면 수정 가능하므로 setter 까지 만들어진다. 하지만 해당 프로퍼티의 가시성을 private으로 선언하면 getter 조차 만들어지지 않는다. 다음과 같이 프로퍼티에 접근하는 것은 필드의 게터를 호출하는 코드로 컴파일된다.
// Primary constructor in the class header
class Person(val name: String, var age: Int) {
// Class body
}
// Person의 getName을 호출하는 것임
Person("MangKyu", 20).name
클래스 내부에서는 함수를 선언할 수도 있지만, 프로퍼티를 선언할 수도 있다. 하지만 코틀린에서 프로퍼티는 필드가 아니라 접근자를 나타내므로 로직을 갖고 함수를 대체해서는 안된다. 즉, 프로퍼티는 상태 조회나 설정으로만 사용해야 한다. 코틀린 공식 문서에서는 다음과 같은 상황들에 한해 함수보다 프로퍼티를 선언하라고 권장하고 있다.
- throw가 발생하지 않음
- 연산 비용이 저렴하거나 첫 실행 이후 캐싱됨
- 객체의 상태가 바뀌지 않는다면, 항상 동일한 결과를 반환함
// name은 주생성자 안에 선언됨, 타입 선언이 필수임
class Task(
val name: String
) {
val length = name.length
fun getLength(): Int {
return name.length
}
}
프로퍼티와 함수 선언 외에도 커스텀 getter와 setter는 다음과 같이 사용할 수 있다.
// name은 주생성자 안에 선언됨, 타입 선언이 필수임
class Task(
val name: String
) {
val length = name.length
fun getLength
// priority는 클래스의 최상위 멤버로 선언됨
var priority = 3
set(value) {
field = value.coerceIn(1..5)
}
// 사용자 정의 getter
val isLowPriority get() = priority < 10
}
클래스의 레이아웃
코틀린은 클래스의 레이아웃 순서를 다음과 같이 배치할 것을 권장한다.
- 프로퍼티 선언과 초기화 블록(Property declarations and initializer blocks)
- 부 생성자(Secondary constructors)
- 메서드 선언(Method declarations)
- 동반 객체(Companion Object)
또한 배치하는 경우에는 다음의 내용들을 고려하라고 한다.
- 메서드 선언은 알파벳 순이나 가시성에 따라 정렬하지 말고, 확장 함수와 일반 함수 역시 구분하지 말 것
- 대신 클래스를 위에서 아래로 읽는 사람이 흐름을 따라갈 수 있도록 배치할 것
- 중첩 클래스는 해당 클래스를 사용하는 코드 옆에 배치시킴
- 클래스가 외부에서 사용되는데, 내부에서 참조되지 않는 경우 컴패니언 객체 뒤의 마지막에 배치시킴
// 1. 프로퍼티 선언과 초기화 블록(Property declarations and initializer blocks)
class Member(
val id: Long,
val name: String,
val status: MemberStatus,
) {
constructor(name: String) : this (
id = 0L,
name = name,
status = MemberStatus.ACTIVE,
)
init {
require(name != null)
}
fun leave() {
if (isActive()) {
status = MemberStatus.LEAVE
}
}
private fun isActive() {
status != MemberStatus.LEAVE
}
companion object {
private val logger = KotlinLogging.logger { }
}
}
데이터 클래스
데이터 클래스는 equals, hashcode, toString 등이 완벽하게 갖춰진 엔티티를 나타내는 클래스이다.
일반적으로 데이터 클래스는 모든 프로퍼티를 읽기 전용으로 만들어 불변 클래스로 만들라고 권장한다. 데이터 클래스를 불변으로 설계하면 속성을 변경하기 어려우므로, 이를 더 쉽게 사용할 수 있게 copy 메서드를 지원한다. copy를 이용하면 일부 프로퍼티가 변경된 새로운 객체를 얻을 수 있다.
Seald 클래스
Sealed 클래스는 다른 클래스가 상속을 받지 못하도록 제한하는 클래스이다. 다른 클래스의 상속을 막기 위해 sealed 클래스는 바이트코드로 변환할 때 private 생성자를 사용하여 제한한다. 따라서 하위 클래스를 정의할 때는 반드시 상위 클래스와 동일한 곳에 위치시켜야 한다.
Seald 클래스를 사용하면 switch 문과 같이 타입 검사를 할 때, 누락되는 클래스가 없돌고 컴파일러의 도움을 받을 수 있다. 참고로 자바와 다르게 코틀린에서 오버라이딩하는 메서드는 반드시 override 키워드를 붙여주어야 한다.
sealed class Animal {
abstract fun getInfo(): String
}
data class Dog(val name: String) : Animal() {
override fun getInfo() = "This is a dog named $name."
}
data class Cat(val name: String, val age: Int) : Animal() {
override fun getInfo() = "This is a cat named $name, and it is $age years old."
}
data class Fish(val color: String) : Animal() {
override fun getInfo() = "This is a $color fish."
}
일반적으로 null 반환을 통해 실패 케이스를 나타낼 수도 있지만. 만약 추가 정보가 필요하다면 실패를 나타내는 sealed 클래스를 반환해서 처리하는 것도 괜찮다고 한다.
인라인 클래스(Inline class)와 타입 별칭(Type alias)
기본 생성자 프로퍼티가 하나인 클래스 앞에 Inline을 붙이면, 해당 객체를 사용하는 위치가 모두 해당 프로퍼티로 교체된다. 이러한 inline 클래스는 타입만 맞으면 값을 바로 집어넣을 수 있고, inline 클래스의 메서드는 모두 정적 메서드로 만들어진다. 이러한 inline 클래스는 타입 오용으로 발생하는 문제를 막을 때 유용하게 사용될 수 있다.
inline class Name(private val value: String) {
}
// 코드
val name: Name = Name("MangKyu")
// 컴파일 때 다음과 같은 형태로 바뀜
val name: String = "MangKyu"
이와 비슷한 타입 별칭(typealias) 기능도 존재하는데, 이를 통해 타입에 새로운 이름을 붙여 줄 수 있다. typealias는 길고 반복적으로 사용해야 할 때 많이 유용한데, 타입을 구분해주지는 않으므로 동일한 타입을 혼용해서 사용할 수 있다. 따라서 자주 사용되는 함수형 타입 혹은 타입 파라미터를 갖는 타입이라면, type alias 사용을 권장한다.
typealias MouseClickHandler = (Any, MouseEvent) -> Unit
typealias PersonIndex = Map<String, Person>
[ 스프링 프레임워크와의 결합 ]
kotlin-spring 플러그인을 통한 프록시 문제 해결
스프링은 프록시 기반 기술을 많이 활용한다. 프록시라 함은 기본적으로 상속이 사용된다는 의미인데, 코틀린 클래스는 기본적으로 final 클래스이므로 불변으로 닫혀있다. 따라서 상속을 열어주는 open 플러그인의 사용이 필요한데, 현재는 그 보다 유용한 kotlin-spring 플러그인으로 스프링 관리 빈을 open 클래스로 만들어주면 된다.
data 클래스로 영속성 엔티티 구현하기
기본 생성자 문제는 no-arg 플러그인을 통해 인자가 없는 생성자를 추가하여 해결할 수 있고, 기본 생성자 추가를 호출하는 애노테이션을 정의할 수도 있다. kotlin-jpa 플러그인은 no-arg 플러그인을 기반으로 만들어 졌으며, @Entity, @Embeddable, @MappedSuperClass 애노테이션으로 자동 표시된 클래스에 기본 생성자를 추가해준다.
하지만 data 클래스는 양방향 연관 관계를 설정하는 경우 toString이나 hashCode를 호출할 때, 무한 순환 참조가 발생할 수 있으므로 data 클래스에 영속성 엔티티를 사용할 때 주의해야 한다.
코틀린은 다양한 문법성 편의를 제공하며, 이를 통해 더욱 직관적이고 생산성 높은 개발을 할 수 있다. 하지만 지나치게 많은 문법적 편의(syntax sugar)를 제공하여 예상치 못하게 동작하는 부분도 많다. 따라서 기초에 충실하여 코틀린의 동작과 문법적 기능들에 대해 올바르게 이용하고 사용할 필요가 있다.
또한 중요하지만 위에서 설명하지 않은 내용들도 많이 있다. 대표적으로 코틀린의 쿠루틴이나 공변성과 관련된 내용 혹은 최적화 기법들이 그러한데, 이러한 내용은 별도의 학습으로 습득해야 할 것이다.
혹시 위에서 다루지 않았지만 이 포스팅을 접할 다른 분들을 위해 추가되었으면 하는 내용이 있으면 댓글로 남겨주세요! 검토 후에 반영하도록 하겠습니다:)
참고 자료
- https://kotlinlang.org/docs/coding-conventions.html
- 이펙티브 코틀린
- 코틀린을 다루는 기술
- 코틀린 쿡북
- https://www.youtube.com/watch?v=ewBri47JWII
- https://www.youtube.com/watch?v=HhifPEExguA
- https://www.youtube.com/watch?v=bhI1hMOcT-4
- https://www.youtube.com/watch?v=MOUcWE-xvyI
- https://www.youtube.com/watch?v=PqA6zbhBVZc
- https://developer.android.com/codelabs/basic-android-kotlin-training-first-kotlin-program?hl=ko#3
- https://play.kotlinlang.org/koans/overview
'Java & Kotlin' 카테고리의 다른 글
| [Java] H2 데이터베이스에서 @Transactional(readOnly=true)일때 save를 호출하는 경우 (2) | 2024.06.11 |
|---|---|
| [JVM] JVM의 init 메서드, 객체의 초기화를 위한 인스턴스 초기화 메서드(instance initialization method) (0) | 2024.06.04 |
| [JVM] Jackson ObjectMapper의 성능을 높여줄 Blackbird 모듈 (0) | 2024.04.30 |
| [JVM] 리플렉션(Reflection)을 포함한 다양한 코드 접근 방식들의 성능 (1) | 2024.04.23 |
| [Kotlin] 공식문서로 Kotest에 대해 알아보기 (1) | 2024.04.09 |
