
티스토리 뷰
1. FlatMap을 통한 중첩 구조 제거
[ FlatMap이란? ]
만약 우리가 처리해야 하는 데이터가 2중 배열 또는 2중 리스트로 되어 있고, 이를 1차원으로 처리해야 한다면 어떻게 해야 할까? 이러한 경우에 map을 이용해도 결과는 2중 Stream의 형태일 것이다. 이처럼 중첩 구조를 한 단계 제거하기 위한 중간 연산이 필요한데, 이것이 바로 flatMap이다. flatMap은 Function 함수형 인터페이스를 매개 변수로 받고 있다.
예를 들어 다음과 같이 2중 리스트가 존재한다고 할 때, 이를 1중 리스트로 변환하기 위해서 flatMap을 이용할 수 있다.
// flatMap 함수
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
// [[a], [b]]
List<List<String>> list = Arrays.asList(Arrays.asList("a"), Arrays.asList("b"));
// [a, b]
List<String> flatList = list.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList());
마찬가지로 2차원 배열의 경우에도 flatMap을 이용해 1차원 배열의 Stream으로 차원을 낮출 수 있다.
Stream<String[]> strStream = Stream.of(
new String[] {"a", "b", "c"},
new String[] {"d", "e", "f"});
// map을 사용하면 2중 Stream이 반환됨
Stream<Stream<String>> stream = strStream.map(Arrays::stream);
// flatMap을 사용하면 1중 Stream으로 차원을 낮출 수 있음
Stream<String> stream = strStream.flatMap(Arrays::stream);
[ FlatMap의 동작 방식 ]
이번에는 FlatMap의 동작 방식에 대해 이해해보도록 하자.
예를 들어 ["Hello", "World"]를 갖는 String의 List가 존재한다고 할 때, 이를 1개의 알파벳씩을 갖도록 String으로 나누고, 중복된 알파벳을 갖지 않는 List로 변환하는 작업을 한다고 하자. 이러한 경우 Map을 이용하면 해결이 불가능하고 flatMap을 이용해야만 하는데, 두 함수의 동작 방식에 대해 자세히 알고 넘어가도록 하자.
1. Map을 적용할 경우
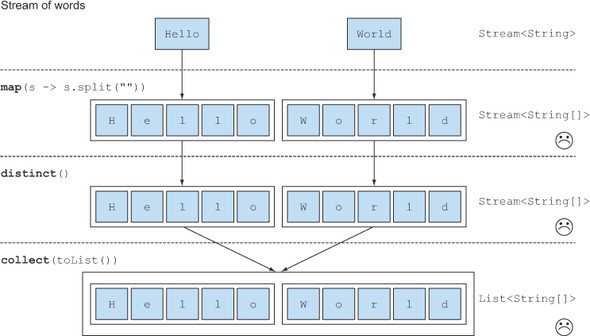
- Hello가 split("")에 의해 ["H", "e", "l", "l", "o"] 로 분리되고, World가 split("")에 의해 ["W", "o", "r", "l", "d"]로 분리된다.
- map에 의해 Stream의 소스가 ["H", "e", "l", "l", "o"] 와 ["W", "o", "r", "l", "d"] 로 변환된다.
- distinct()에 의해 중복된 소스가 제거된다. (해당 사항 없음)
- 2개의 ["H", "e", "l", "l", "o"] 와 ["W", "o", "r", "l", "d"]가 collect(toList())에 의해 수집된다.
위와 같은 처리 과정을 통해 2개의 String[]을 요소로 갖는 리스트 List<String[]>가 생성된다. 하지만 우리가 원했던 List<String>이 아니며, 이러한 경우에는 map으로 해결이 불가능하다. 위의 과정에서 필요한 것은 map에 의해 변환된 Stream의 소스인 String[] 를 String으로 flat하게 나열하는 것이며 이러한 필요에 의해 flatMap이 등장하게 되었다.
2. flatMap을 적용할 경우
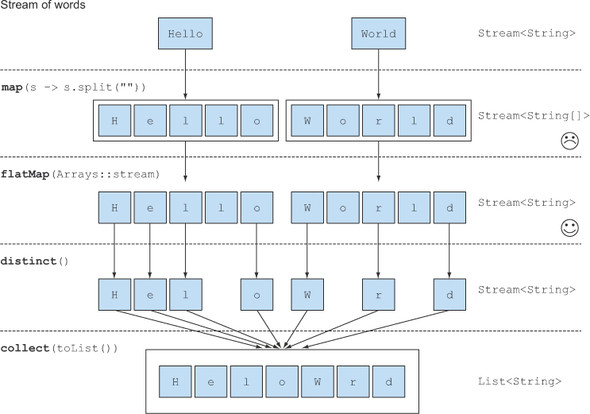
- Hello가 split("")에 의해 ["H", "e", "l", "l", "o"] 로 분리되고, World가 split("")에 의해 ["W", "o", "r", "l", "d"]로 분리된다.
- Arrays.stream(T[] array)를 사용해 ["H", "e", "l", "l", "o"] 와 ["W", "o", "r", "l", "d"]를 각각 Stream<String>으로 만든다.
- flatMap()을 사용해 여러 개의 Stream<String>을 1개의 Stream<String>으로 평평하게 합치고, Stream의 소스는 ["H", "e", "l", "l", "o", W", "o", "r", "l", "d"] 가 된다.
- distinct()에 의해 중복된 소스(l, o)가 제거된다.
- 중복이 제거된 ["H", "e", "l", "o", "W", "r", "d"]가 collect(toList())에 의해 수집된다.
3번의 과정에서 map을 사용하면 평평하게 펼치지 못하므로 Stream<Stream<String>>이 생성되었다. 하지만 flatMap을 이용함으로써 알파벳 String을 요소로 갖는 리스트 List<String>를 생성할 수 있었다.
[ FlatMap의 활용 예제 ]
예를 들어 국어 점수, 영어 점수, 수학 점수를 갖는 Student 클래스가 존재한다고 하자. Student 객체들이 저장된 student 리스트에서 모든 학생들의 모든 과목의 평균을 구해야하는 상황이라고 할 때, 이러한 flatMap을 이용하면 이를 쉽게 해결할 수 있다.
이 예제에서 Student 리스트는 Student보다 한 차원 높게 있으므로, 모든 점수들을 수평하게 갖는 Stream을 생성하기 위해 flatMap을 활용해 줄 수 있다. 추가로 이 예제에서는 모든 점수들이 int 값이므로 flatMapToInt를 활용할 수 있다. 이를 코드로 작성하면 다음과 같다.
import java.util.Arrays;
import java.util.List;
import java.util.stream.IntStream;
class Student {
private int kor;
private int eng;
private int math;
public Student(int kor, int eng, int math) {
this.kor = kor;
this.eng = eng;
this.math = math;
}
public int getKor() {
return kor;
}
public int getEng() {
return eng;
}
public int getMath() {
return math;
}
}
public class Main {
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student(80, 90, 75),
new Student(70, 100, 75),
new Student(85, 90, 85),
new Student(80, 100, 90)
);
students.stream().flatMapToInt(student ->
IntStream.of(student.getKor(), student.getEng(), student.getMath()))
.average()
.ifPresent(avg -> System.out.println(Math.round(avg * 10) / 10.0));
}
}
또한 flatMap을 이용하면 계층 구조를 지닌 클래스에서 Null 검사와 관련된 코드를 보다 가독성있게 사용할 수 있다. 예를 들어 아래와 같은 계층 구조를 지닌 Class가 있다고 하자.
class Outer {
Nested nested;
}
class Nested {
Inner inner;
}
class Inner {
String foo;
}
Outer로부터 String foo를 꺼내기 위해서는 NullPointerException을 막기 위해 아래와 같은 여러 번의 null 검사가 불가피하다. 하지만 이러한 부분 역시 flatMap을 사용하면 다음과 같이 코드를 가독성있게 작성할 수 있다.
// flatMap 적용 전
Outer outer = new Outer();
if (outer != null && outer.nested != null && outer.nested.inner != null) {
System.out.println(outer.nested.inner.foo);
}
// flatMap 적용 후
Optional.of(new Outer())
.flatMap(o -> Optional.ofNullable(o.nested))
.flatMap(n -> Optional.ofNullable(n.inner))
.flatMap(i -> Optional.ofNullable(i.foo))
.ifPresent(System.out::println);
2. Reduce를 통한 결과 생성
[ Reduce란? ]
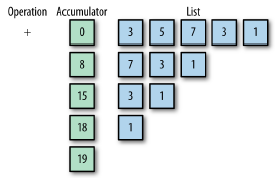
Reduce는 누산기(Accumulator)와 연산(Operation)으로 컬렉션에 있는 값을 처리하여 더 작은 컬렉션이나 단일 값을 만드는 작업이다. 예를 들어 다음과 같이 List<Integer>에서 총합을 구하는 연산은 sum 함수 말고 reduce로 처리할 수 있다. 또한 이러한 작업은 위의 그림에서 확인할 수 있듯이 Accumulator와 Operation를 사용한다.
list.stream()
.reduce(Integer::sum)
.get();
Stream API의 reduce 함수는 여러 요소들을 통해 새로운 결과를 만들어내는데, reduce 함수는 최대 3가지의 매개변수를 받을 수 있다.
- Accumulator: 각 요소를 계산한 중간 결과를 생성하기 위해 사용
- Identity: 계산을 처리하기 위한 초기값
- Combiner: Parlallel Stream에서 나누어 계산된 결과를 하나로 합치기 위한 로직
1. reduce(accumulator)
1개의 파라미터만을 갖는 reduce함수는 BinaryOperator를 매개변수로 받는다. BinaryOperator<T>는 같은 타입의 인자 2개를 받아 같은 타입의 결과를 반환하는 함수형 인터페이스이다. 예를 들어 모든 요소의 값을 더하는 경우에는 두 파라미터를 더한 값을 람다식으로 작성해주어야 하는데, 이에 대한 예제 코드는 아래와 같다.
// 1개 (accumulator)
Optional<T> reduce(BinaryOperator<T> accumulator);
OptionalInt reduced = IntStream.range(1, 4) // [1, 2, 3]
.reduce((a, b) -> {
return Integer.sum(a, b);
});
위의 코드를 실행하면 6(1+2+3)이 나오게 된다. 1개의 매개변수를 갖는 경우 Stream이 비어있을 수 있으므로 Optional을 반환하고 있다.
2. reduce(identity, accumulator)
2개의 파라미터를 갖는 reduce함수는 Generic 타입의 identity와 BinaryOperator를 매개변수로 받는다. 새롭게 추가된 identity는 계산을 처리하기 위한 초기값을 의미한다. 예를 들어 위의 총합 로직에 10을 초기값으로 두고 싶다면 다음과 같이 코드를 수정할 수 있다. (추가로 메소드 참조도 적용해보도록 하자.)
// 2개 (identity, accumulator)
T reduce(T identity, BinaryOperator<T> accumulator);
int reduced = IntStream.range(1, 4) // [1, 2, 3]
.reduce(10, (a, b) -> {
return Integer.sum(a, b);
});위의 코드를 실행하면 초기값 10이 더해져 16(10+1+2+3)이 나오게 된다. 매개변수로 초기값 Identity를 갖는 경우 Optional을 반환할 필요가 없기 때문에 원시값을 반환하고 있다.
3. reduce(identity, accumulator, combiner)
3개의 파라미터를 갖는 reduce함수는 Generic 타입의 identity와 BiFunction, BinaryOperator를 매개변수로 받는다.
BiFunction은 2개의 파라미터 타입과 1개의 반환형 모두를 Generic Type으로 갖지만, BinaryOperator는 BiFunction을 구현(Implements)하여 1개의 반환형만을 Generic Type으로 갖는다는 점에서 차이가 있을 뿐 거의 동일하다.
새롭게 추가된 combiner는 병렬 처리 시에 각자 쓰레드에서 실행된 결과를 마지막에 합치는 작업을 한다. 그렇기 때문에 기존의 코드에 combiner 코드를 추가하여도 ParallelStream으로 실행하지 않으면 combiner는 호출되지 않는다. (IntStream에는 3개의 파라미터를 갖는 reduce가 존재하지 않으므로 Stream.of()로 Stream을 생성해야 한다.)
// 3개
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
int reduced = Stream.of(1, 2, 3)
.reduce(10, Integer::sum, (a, b) -> {
System.out.println("combiner was called");
return a + b;
});
위의 코드를 실행하면 Parallel Stream이 아니기 때문에 Combiner 관련 출력이 찍히지 않는다. 그렇기 때문에 reduce를 병렬로 실행시키기 위해서는 parallel()함수를 추가해주어야 한다.
int reduced = Stream.of(1, 2, 3)
.parallel()
.reduce(10, Integer::sum, (a, b) -> {
System.out.println("combiner was called");
return a + b;
});
parallel()을 추가하여 해당 코드를 실행하면 Combiner는 2번 호출되고, 총합의 결과 reduced는 36이 된다. 그러한 이유는 reduce 로직이 병렬로 실행되는데, 초기값 10 역시 병렬로 갖게 되기 때문이다. 병렬로 더해진 각각의 값은 11(10+1), 12(10+2), 13(10+3) 이 되고, Combiner가 이를 합치게 된다. Combiner는 역순으로 12+13 = 25를 먼저 더하고, 그 다음 25+11 = 36을 더하여 총 2번 호출되며 최종적으로 36을 반환하게 된다.
그렇기 때문에 초기값이 모든 reduce 단계에 필요한 경우에는 초기 값을 Identity에 적어주고, 전체 단계 중 1회만 필요한 경우에는 초기값으로 0과 같은 값을 넘기고, 연산된 결과에 10을 더하도록 해야 한다.
int reduced = 10 + Stream.of(1, 2, 3)
.parallel()
.reduce(0, Integer::sum, (a, b) -> {
System.out.println("combiner was called");
return a + b;
});
여기서 또 주목해야 할 것은 ParallelStream의 경우 추가적인 연산인 Combiner가 처리된다는 것이다. 그렇기 때문에 간단한 작업에 ParallelStream을 적용하면 오히려 처리속도가 느려질 수 있음을 고려해야 한다.
3. Null-Safe한 Stream 생성하기
[ Null-Safe Stream 생성 ]
Java를 이용해 개발을 하다 보면 NPE(NullPointerException)가 매우 자주 발생하곤 한다. 물론 NPE를 방지하기 위해 null 여부를 검사하는 코드를 작성해줄 수 있지만, 이러한 코드는 상당히 가독성이 떨어지기 마련이다.
이러한 문제를 해결하기 위해 Java8부터는 Optional이라는 Wrapper 클래스를 제공하여 Null 관련 코드를 가독성있게 처리할 수 있도록 도와주고 있으며, Stream API 역시 Optional의 도움을 받아 Null-Safe한 Stream을 생성할 수 있다.
(Optional에 대해 잘 모른다면 여기를 참고해주세요!)
Null-Safe한 Stream을 생성하기 위한 함수는 다음과 같다.
public <T> Stream<T> collectionToStream(Collection<T> collection) {
return Optional
.ofNullable(collection)
.map(Collection::stream)
.orElseGet(Stream::empty);
}
collectionToStream 함수는 매개변수로 받은 Collection 객체를 이용해서 Optional 객체를 만들고 Stream을 생성한 후 반환하도록 하고 있다. 만약 파라미터로 받은 Collection이 null이라면 빈 Stream을 반환하므로 어떠한 경우에서도 Null이 발생하지 않는다. 이를 적용하여 작성한 코드를 살펴보면 아래와 같다.
List<String> nullList = null;
// NPE 발생
nullList.stream()
.filter(str -> str.contains("a"))
.map(String::length)
.forEach(System.out::println); // NPE!
// 빈 Stream으로 처리
collectionToStream(nullList)
.filter(str -> str.contains("a"))
.map(String::length)
.forEach(System.out::println); // []
물론 Optional은 코드의 가독성을 높여주지만 Wrapper 클래스를 사용하는 것일 뿐이다. Stream을 생성해야 하는 대상이 Null이 발생할 확률이 높을 경우에 이러한 코드를 적용해주는 것이 의미있을 것으며, 무의미하게 Optional을 남발하는 것은 바람직하지 않다.
4. 실행 순서에 대한 고려
[ Stream API의 실행 순서 ]
Stream API를 정확히 알고 사용하지 못하면 처리 속도의 지연을 야기할 수 있다. 그렇기 때문에 우리가 작성한 Stream API 코드가 어떻게 동작할 것인지 정확히 이해하고 있는 것이 중요하다.
예를 들어 다음과 같은 코드가 있다고 할 때, 이를 실행한 결과를 한번 예측해보고 확인해보도록 하자.
Stream.of("a", "b", "c", "d", "e")
.filter(s -> {
System.out.println("filter: " + s);
return true;
})
.forEach(s -> System.out.println("forEach: " + s));
/*
filter: a
forEach: a
filter: b
forEach: b
filter: c
forEach: c
filter: d
forEach: d
filter: e
forEach: e
*/
결과를 확인해보면 예상했던 것과 다를 것이다. 왜냐하면 모든 데이터에 대해 filter가 진행되고 forEach가 실행되는 수평적 구조로 순회하는 것이 아니라, 각각의 데이터에 대해 filter와 forEach가 먼저 수행하는 수직적 구조로 순회하기 때문이다. Stream API가 수직적 구조로 순회하는 이유는 다음의 코드를 보면 쉽게 이해할 수 있을 것이다.
Stream.of("a", "b", "c", "d", "e")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.anyMatch(s -> {
System.out.println("anyMatch: " + s);
return s.startsWith("A");
});
/*
map: a
anyMatch: A
*/
만약 위와 같은 코드가 있을 때, 수평적인 구조로 처리된다면 몇번 실행이 될까?
위의 코드는 우선 map에 따라 모든 데이터를 대문자로 변환하고, 변환된 데이터를 기준으로 "A"로 시작하는 문자열을 찾을 것이므로 map 5번 + anyMatch 1번 = 총 6번 실행이 될 것이다. 하지만 실제로(수직적인 구조) 위의 코드를 실행해보면 a를 대문자로 변환하고 바로 anyMatch를 실행할 것이므로 map 1번 + anyMatch 1번 = 총 2번 실행 될 것이다.
이러한 처리 방식은 각각의 원소에 대해 실제로 실행되는 연산의 수를 줄여줄 수 있다.
[ 실행 순서를 고려해야 하는 이유 ]
Stream API는 수직적인 구조로 진행이 되기 때문에 실행 순서를 고려하는 것이 상당히 중요하다. 잘못된 실행 속도는 연산의 횟수를 불필요하게 증가시키기 때문이다.
예를 들어 다음과 같은 코드가 존재한다고 할 때, 이를 실행한 결과는 어떻게 되겠는지 한번 예측해보자.
Stream.of("a", "b", "c", "d", "e")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("A");
})
.forEach(s -> System.out.println("forEach: " + s));
/*
map: a
filter: A
forEach: A
map: b
filter: B
map: c
filter: C
map: d
filter: D
map: e
filter: E
*/
우리가 예상했듯이 map과 filter는 모든 문자열에 대해 각각 5번 불러졌고, forEach는 1번만 불러졌다. 위의 코드는 최선인 것 처럼 보이지만 filter를 앞으로 당김으로써 실제 실행되는 연산의 수를 줄일 수 있다. 위의 코드를 다음과 같이 수정하여 실행해보자.
Stream.of("a", "b", "c", "d", "e")
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("a");
})
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.forEach(s -> System.out.println("forEach: " + s));
/*
filter: a
map: a
forEach: A
filter: b
filter: c
filter: d
filter: e
*/
위와 같이 수정된 코드는 filter가 5번, map과 forEach가 각각 1번씩 수행되었고, 동일한 입력과 결과에 대해 더 적은 연산으로 처리할 수 있게 되었다. 만약 처리해야 하는 데이터의 크기가 훨씬 많아지면 이는 성능의 차이를 야기할 것이다. 그렇기 때문에 Stream API를 사용할 때에는 반드시 연산 순서를 고려하여 코드를 작성해야 한다.
5. 병렬 스트림(Parallel Stream)의 활용
[ 병렬 스트림(Parallel Stream) 이란? ]
Stream은 아주 많은 양의 데이터를 처리해야 하는 경우에 런타임 성능을 높이기 위해 병렬로 실행할 수 있는 기능인 병렬 스트림(Parallel Stream)을 제공하고 있다. Parallel Stream은 내부적으로 fork & join을 사용하고 있으며, ForkJoinPool.commonPool()을 통해 사용가능한 공통의 ForkJoinPool의 갯수를 확인할 수 있다. 내재되어 있는 ThreadPool의 갯수는 최대 5개이며, 사용가능한 물리적인 CPU 코어의 수에 따라 다르게 설정된다.
ForkJoinPool commonPool = ForkJoinPool.commonPool();
System.out.println(commonPool.getParallelism());
또한 이 값은 다음과 같은 JVM의 매개변수를 통해 별도로 설정해줄 수 있다.
-Djava.util.concurrent.ForkJoinPool.common.parallelism=5
Collection은 원소들의 Parallel Stream을 생성하기 연산으로 parallelStream() 메소드를 제공하고 있다. 또한 순차 Stream으로 진행하는 중에 일부 연산만을 병렬로 처리하기 위해 중간 연산으로 parallel() 메소드 역시 제공하고 있다. 다음의 예제는 Parallel Stream의 실행 동작을 이해하기 위해 해당 로직을 처리한 쓰레드의 정보를 출력하고 있다.
Arrays.asList("a", "b", "c", "d", "e")
.parallelStream()
.filter(s -> {
System.out.format("filter: %s [%s]\n", s, Thread.currentThread().getName());
return true;
})
.map(s -> {
System.out.format("map: %s [%s]\n", s, Thread.currentThread().getName());
return s.toUpperCase();
})
.forEach(s -> System.out.format("forEach: %s [%s]\n", s, Thread.currentThread().getName()));
/*
filter: c [main]
filter: e [ForkJoinPool.commonPool-worker-3]
map: e [ForkJoinPool.commonPool-worker-3]
filter: a [ForkJoinPool.commonPool-worker-2]
map: a [ForkJoinPool.commonPool-worker-2]
filter: b [ForkJoinPool.commonPool-worker-1]
forEach: A [ForkJoinPool.commonPool-worker-2]
forEach: E [ForkJoinPool.commonPool-worker-3]
map: c [main]
filter: d [ForkJoinPool.commonPool-worker-2]
map: d [ForkJoinPool.commonPool-worker-2]
map: b [ForkJoinPool.commonPool-worker-1]
forEach: D [ForkJoinPool.commonPool-worker-2]
forEach: C [main]
forEach: B [ForkJoinPool.commonPool-worker-1]
*/
출력 결과를 확인하면 어느 쓰레드가 실제 Stream 연산을 수행하였는지 확인할 수 있다. 위에서 확인할 수 있듯이 Parallel Stream은 Stream연산을 실행하기 위해 공통의 ForkJoinPool에서 사용가능한 모든 쓰레드를 활용하고 있다. 또한 어떠한 쓰레드가 어떠한 작업을 할 지는 비결정적이기 때문에 실행에 따라 출력 결과는 달라질 수 있다.
[ 병렬 스트림(Parallel Stream) 의 정렬(Sort) ]
Stream에서 정렬이 어떻게 동작하는지 확인해보기 위해 위의 코드에 정렬을 위한 sorted를 추가하여 실행해보도록 하자.
Arrays.asList("a", "b", "c", "d", "e")
.parallelStream()
.filter(s -> {
System.out.format("filter: %s [%s]\n", s, Thread.currentThread().getName());
return true;
})
.map(s -> {
System.out.format("map: %s [%s]\n", s, Thread.currentThread().getName());
return s.toUpperCase();
})
.sorted((s1, s2) -> {
System.out.format("sort: %s <> %s [%s]\n", s1, s2, Thread.currentThread().getName());
return s1.compareTo(s2);
})
.forEach(s -> System.out.format("forEach: %s [%s]\n", s, Thread.currentThread().getName()));
/*
filter: c [main]
map: c [main]
filter: e [ForkJoinPool.commonPool-worker-3]
map: e [ForkJoinPool.commonPool-worker-3]
filter: a [ForkJoinPool.commonPool-worker-2]
map: a [ForkJoinPool.commonPool-worker-2]
filter: b [ForkJoinPool.commonPool-worker-1]
map: b [ForkJoinPool.commonPool-worker-1]
filter: d [main]
map: d [main]
sort: B <> A [main]
sort: C <> B [main]
sort: D <> C [main]
sort: E <> D [main]
forEach: C [main]
forEach: E [ForkJoinPool.commonPool-worker-2]
forEach: A [ForkJoinPool.commonPool-worker-1]
forEach: B [ForkJoinPool.commonPool-worker-3]
forEach: D [main]
*/
위의 코드를 여러 번 실행하면 비결정적인 Parallel Stream에 따라 출력 결과가 항상 바뀌어야 한다. 다른 출력 결과는 항상 바뀌지만 sort는 main Thread에서 순차적으로 실행되는 것을 확인할 수 있다. 이러한 이유는 Parallel Stream에서의 sort가 내부적으로 Java8의 새로운 메소드인 Arrays.parallelSort()를 사용하기 때문이다.
Javadoc을 살펴보면 다음과 같이 내용이 작성되어 있다.
The method uses a threshold value and any array of size lesser than the threshold value is sorted using the Arrays#sort() API (i.e sequential sorting). And the threshold is calculated considering the parallelism of the machine, size of the array and is calculated as:
이 메소드는 임계값을 사용하고 배열의 크기가 임계값보다 작으면 순차 정렬 방식인 Arrays의 sort() API를 대신 사용한다. 그리고 임계값은 컴퓨터의 병렬성, 배열의 크기 등에 따라 다음과 같이 계산된다.
즉, 어떤 임계값(Threshold)를 계산하여 배열의 길이가 그 크기보다 작으면 순차적인 정렬 방식(Sequential Sorting)인 Arrays.sort()를 이용한다는 것이다. 여기서 임계값은 결국 프로세스에 할당 가능한 배열의 길이일 것이다. 위의 예제에서는 Arrays.sort()가 사용되었지만, 만약 배열의 크기를 상당히 크게 한다면 parallelSort()가 사용될 것이다.
앞서 설명한대로 Parallel Stream의 경우 Combiner 등과 같은 추가적인 연산이 필요로 하게 된다. 그렇기 때문에 적절한 상황에 Parallel 하게 처리하도록 하는 것이 중요하다. 다음 장에서는 Stream API와 관련된 문제를 실제로 풀어보도록 하자.
관련 포스팅
- Stream API에 대한 이해 - (1/5)
- 람다식(Lambda Expression)과 함수형 인터페이스(Functional Interface) - (2/5)
- Stream API의 활용 및 사용법 기초 - (3/5)
- Stream API의 고급 활용 및 사용 시의 주의할 점 - (4/5)
- Stream API 연습문제 풀이 - (5/5)
참고 자료
- https://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/
- https://futurecreator.github.io/2018/08/26/java-8-streams/
- https://futurecreator.github.io/2018/08/26/java-8-streams-advanced/
- https://gist.github.com/gksxodnd007/8fa2cdf64911199a3cbca1ebfd273ce7
- http://iloveulhj.github.io/posts/java/java-stream-api.html
'Java & Kotlin' 카테고리의 다른 글
| [Java] Garbage Collection(가비지 컬렉션)의 개념 및 동작 원리 (1/2) (38) | 2021.01.27 |
|---|---|
| [Java] Stream API 연습문제 풀이 (5/5) (8) | 2021.01.25 |
| [Java] Stream API의 활용 및 사용법 - 기초 (3/5) (10) | 2021.01.25 |
| [Java] 람다식(Lambda Expression)과 함수형 인터페이스(Functional Interface) - (2/5) (15) | 2021.01.22 |
| [Java] Stream API에 대한 이해 - (1/5) (16) | 2021.01.22 |
