

티스토리 뷰
1. CUDA C 병렬 프로그래밍 고급 예제
[ Parallel Dot ]
아래의 예제는 동일한 크기의 A배열과 B배열의 index에 있는 숫자를 곱해 C배열에 대입하는 코드이다.
#include "device_launch_parameters.h"
#include <cuda_runtime.h>
#include <stdlib.h>
#include <stdio.h>
#define SIZE (2048 * 2048)
#define THREADS_PER_BLOCK 512
// __global__을 통해서 커널임을 표시한다. host에서 호출된다.
__global__ void dot(int *a, int *b, int *c, int n){
// 수많은 블록과 스레드가 동시에 처리한다.
// 위에서 정의한 index를 통해서 스레드들을 구별한다.
int index = threadIdx.x + blockIdx.x * blockDim.x;
c[index] = a[index] * b[index];
printf("%d = %d * %d\n", c[index], a[index], b[index]);
}
int main(){
int *a, *b, *c;
int *d_a, *d_b, *d_c;
int size = N * sizeof(int);
// 호스트의 메모리에 할당한다.
a = (int *)malloc(size);
b = (int *)malloc(size);
c = (int *)malloc(size);
// cudaMalloc(destination, number of byte)로 device의 메모리를 할당한다.
cudaMalloc(&d_a, size);
cudaMalloc(&d_b, size);
cudaMalloc(&d_c, size);
// 초기화
for (int i = 0; i<SIZE; ++i) {
a[i] = i;
b[i] = i;
c[i] = 0;
}
// cudaMemcpy(destination, source, number of byte, cudaMemcpyHostToDevice)로 호스트에서 디바이스로 메모리를 카피한다.
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_c, c, size, cudaMemcpyHostToDevice);
// 함수 호출을 위해서 새로운 신텍스 요소를 추가할 필요가 있다.
// 첫번째 parameter는 블럭의 수이다. 예제에서는 스레드 블럭이 하나이다.
// SIZE는 1024개의 스레드를 의미한다.
dot <<< SIZE / THREADS_PER_BLOCK , THREADS_PER_BLOCK >>>(d_a, d_b, d_c, SIZE);
//cudaMemcpy(source, destination, number of byte, cudaMemDeviceToHost)로 디바이스의 메모리(연산 결과 데이터)를 호스트에 카피한다.
cudaMemcpy(a, d_a, size, cudaMemcpyDeviceToHost);
cudaMemcpy(b, d_b, size, cudaMemcpyDeviceToHost);
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
for (int i = 0; i<SIZE; ++i) {
printf("c[%d] = %d\n", i, c[i]);
}
// 호스트의 메모리 할당 해제
free(a);
free(b);
free(c);
// cudaFree(d_a)를 통해 디바이스의 메모리를 할당 해제
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
add 함수는 deivce에서 실행되므로 device memory에 대한 pointer(Device Pointer)가 되어야 하며, cudaMalloc 함수를 통해 device의 메모리를 할당할 수 있다. (CPU)메모리에 대한 제어를 위해서 기존의 malloc, free, memcpy 대신 cudaMalloc, cudaFree, cudaMemcpy를 사용한다는 것을 제외하고는 거의 동일하다.
병렬처리를 위해서는 SIZE / THREADS_PER_BLOCK = 8192개의 블록을 사용하며, 각 블록은 THREADS_PER_BLOCK = 512 개의 쓰레드를 사용한다.
[ Why Threads(쓰레드를 사용하는 이유) ]
Thread를 사용하면 추상화 수준이 더해져 더욱 복잡해지며, 개발이 어려워진다.
하지만 그럼에도 불구하고 Thread를 사용하는 이유는 아래와 같다.
-
Communicate
-
Synchronize
예를 들어, 위의 예제를 조금 더 복잡하게 하여 A블록과 B블록의 각각의 인덱스를 곱하여 나온 값을 모두 더한 최종 합을 구하는 경우를 고려해보자.
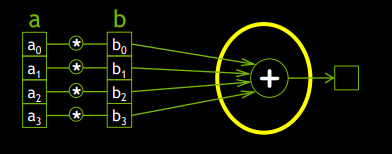
Thread를 이용하면, 각 블록에서 4개의 index에 대한 곱셈을 처리한 후 하나의 블록에서 블록의 합을 쉽게 구할 수 있는데, 그것은 각 블록의 쓰레드가 Shared Memory를 가지기 때문이다.

기존의 각 thread에서 private로 가지는 변수를 __global__ 키워드를 선언하여 Shared Memory에 곱셈의 값을 저장하면 최종 합을 쉽게 구할 수 있다.
__global__ void dot( int *a, int *b, int *c ) {
// 각각의 쓰레드는 A[인덱스] * B[인덱스]를 수행할 것이다.
int temp = a[threadIdx.x] * b[threadIdx.x];
// 각 쓰레드의 temp는 private이기 때문에 여기서 최종합을 계산할 수 없다.
// 그렇기 때문이 이 코드를 아래와 같이 수정할 것이다.
}
#define N 512
__global__ void dot( int *a, int *b, int *c ) {
// 결과를 저장하기 위한 블록의 Shared Memory를 선언한다.
__shared__ int temp[N];
temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x];
// 0번 쓰레드에서 합을 계산하도록 한다.
if( 0 == threadIdx.x ) {
int sum = 0;
for( int i = 0; i < N; i++ )
sum += temp[i];
*c = sum;
}
}
위의 코드에서는 0번 스레드로 하여금 모든 합을 구하도록 하고있는데, 이러한 코드는 당연히(?) 문제가 발생할 것이다. 그것은 바로 공유변수에 값이 Write되기 이전에 Read를 해버리는 문제가 발생하기 때문인데, 쉽게 설명하면 3번 쓰레드는 아직 곱샘을 수행하고 있는데 0번 쓰레드에서 공유 변수인 temp[3]을 Read하여 sum을 구하고 있기 때문이다.
이러한 문제를 해결하기 위해 synchronization(동기화) 처리를 해주어야 한다. 모든 스레드는 Block 단위로만 동기화가 가능한데, __syncthreads()라는 함수를 사용하면 블록 안의 모든 쓰레드가 __syncthreads()를 hit하기 전까지 기다리게 할 수 있다.
[ Parallel Dot to get Final Sum with Single block, Multi Thread ]
위에서 발생한 코드를 수정하여 1개의 블록, N개의 쓰레드에서 곱샘을 수행하고 최종합을 구하는 코드는 아래와 같다.
#include "device_launch_parameters.h"
#include <cuda_runtime.h>
#include <stdlib.h>
#include <stdio.h>
#define N 512
__global__ void dot(int *a, int *b, int *c){
__shared__ int temp[N];
temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x];
__syncthreads();
if(threadIdx.x == 0){
int sum = 0;
for(int i = 0 ; i < N ; i++){
sum += temp[i];
}
*c = sum;
}
}
int main(void){
int *a, *b, *c;
int *dev_a, *dev_b, *dev_c;
int size = N * sizeof(int);
// allocate host memories
a = (int *)malloc(size);
b = (int *)malloc(size);
c = (int *)malloc(sizeof(int));
// allocate device memories
cudaMalloc(&dev_a, size);
cudaMalloc(&dev_b, size);
cudaMalloc(&dev_c, sizeof(int));
// initialize variable
for (int i = 0; i < SIZE; ++i) {
a[i] = i;
b[i] = i;
}
// copy host memories to device memories
cudaMemCpy(dev_a, a, size, cudaMemcpyHostToDevice);
cudaMemCpy(dev_b, b, size, cudaMemcpyHostToDevice);
// run dot with N threads
dot <<< 1, N >>> (dev_a, dev_b, dev_c);
// copy device memories sum result(dev_c) to host memories(c)
cudaMemCpy(c, dev_c, sizeof(int), cudaMemCpyDeviceToHost);
// print result of final sum
printf("Final Sum: %d \n", *c);
free(a); free(b); free(c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
위의 코드는 분명히 정상적으로 작동 할 것이다. 하지만 우리는 위에서 1개의 블록에 대해 쓰레드만을 고려하고 있으므로, 위와 같이 1개의 블럭만을 사용하면 GPU를 효율적으로 사용할 수 없을 것이다. 그렇기 때문에 우리는 위의 코드를 multiblock을 사용하도록 변경해야 한다.
[ Parallel Dot to get Final Sum with Multi block, MultiThread ]
최종합을 구하기 위해서는 각 블록은 블록의 합을 먼저 구한 후에 블록의 합들을 모두 더해야 한다.
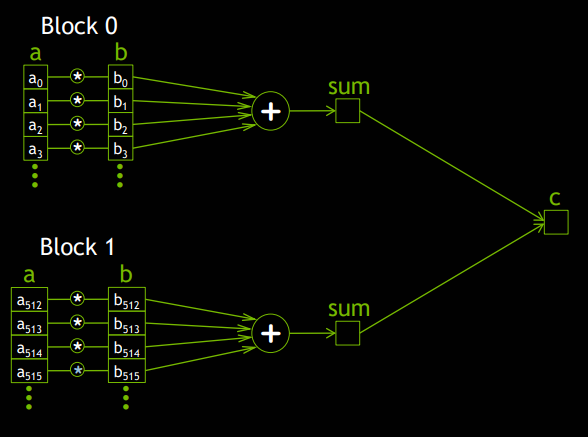
하지만 이렇게 블록단위로 계산을 한 후에 하나의 블록에서 최종합을 구하는 방법 역시 Race Condition이 발생하게 된다. Race Condition이 발생하는 이유는 __syncthreads()가 블록단위로 쓰레드별로 작동하기 때문인데, 우리는 이러한 문제를 CUDA's atomic operation을 활용하여 해결할 수 있다.
Atomic Operations는 메모리로의 동시 접근이 필요한 상황일 때, atomic하게 이를 처리한다.(작업이 쪼개질 수 없이, 단일로 처리됨) CUDA C는 다음과 같은 atomic operation들을 지원하는데, 우리의 예제는 atomicAdd로 해결가능하다.

[ Parallel Dot to get Final Sum with Multi block, Multi Thread ]
이제 각 배열의 인덱스를 곱하여 최종합을 구하는 코드를 여러 개의 블록과 여러 개의 쓰레드에서 처리가능 하도록 아래와 같이 변경하도록 하자.
#include "device_launch_parameters.h"
#include <cuda_runtime.h>
#include <stdlib.h>
#include <stdio.h>
#define N (2048 * 2048)
#define THREADS_PER_BLOCK 512
__global__ void dot(int *a, int *b, int *c){
__shared__ int temp[THREADS_PER_BLOCK];
int index = threadIdx.x + blockIdx.x * blockDim.x;
temp[threadIdx.x] = a[index] * b[index];
__syncthreads();
if(threadIdx.x == 0){
int sum = 0;
for(int i = 0 ; i < THREADS_PER_BLOCK ; i++){
sum += temp[i];
}
atomicAdd(c, sum);
}
}
int main(void){
int *a, *b, *c;
int *dev_a, *dev_b, *dev_c;
int size = N * sizeof(int);
// allocate host memories
a = (int *)malloc(size);
b = (int *)malloc(size);
c = (int *)malloc(sizeof(int));
// allocate device memories
cudaMalloc(&dev_a, size);
cudaMalloc(&dev_b, size);
cudaMalloc(&dev_c, sizeof(int));
// initialize variable
for (int i = 0; i < SIZE; ++i) {
a[i] = i;
b[i] = i;
}
// copy host memories to device memories
cudaMemCpy(dev_a, a, size, cudaMemcpyHostToDevice);
cudaMemCpy(dev_b, b, size, cudaMemcpyHostToDevice);
// run dot with N threads
dot <<< N / THREADS_PER_BLOCK, THREADS_PER_BLOCK >>> (dev_a, dev_b, dev_c);
// copy device memories sum result(dev_c) to host memories(c)
cudaMemCpy(c, dev_c, sizeof(int), cudaMemCpyDeviceToHost);
// print result of final sum
printf("Final Sum: %d \n", *c);
free(a); free(b); free(c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
참고 자료
관련 포스팅
-
CUDA 프로그래밍 고급 예제 (2/2)
'나의 공부방' 카테고리의 다른 글
| [기술면접] CS 기술면접 질문 - 자료구조 (2/8) (2) | 2020.09.16 |
|---|---|
| [기술면접] CS 기술면접 질문 - 프로그래밍 공통 (1/8) (40) | 2020.09.16 |
| [CUDA] CUDA 개념 및 CUDA 초급 예제 (1/2) (4) | 2020.09.11 |
| [블록체인] NFT(Non-Fungible Token) ERC-721이란? (2) | 2020.08.21 |
| [블록체인] 이더리움(Ethereum)에 크립토키티(CryptoKitties)와 같은 게임 개발하기 (0) | 2020.07.22 |
