

티스토리 뷰
1. 마르코프 의사결정 모델이란?
[ 마르코프 의사결정 모델 ]
인공지능이 학습하고자 하는 방법을 공식화해서 추론하는 것은 매우 중요한 모델로, 학습을 위해 마르코프 의사결정 모델을 주로 사용합니다. 예를 들어 벽돌깨기 게임을 한다고 가정할 때, 여기서 Environment(환경)은 벽돌깨기가 되고, 그 환경은 바의 위치, 공의 방향과 위치, 모든 벽돌의 존재유무 등 다양한 State(상태)를 같습니다. 그리고 Agent는 환경안에서 바를 왼쪽 또는 오른쪽으로 옮기는 것과 같은 특정한 Action(행동)을 하게 되고, 때로는 이러한 행동들의 결과로 점수라는 Reward(보상)를 받게됩니다. Action들은 Environment에 변화를 일으키고, State값이 변하게 되어, Agent가 또 다른 Action을 선택하도록 하고, 이를 Policy(정책)이라 합니다. 여기서 Environment는 때로 무작위적으로 생성되는데, 예를 들어 공을 놓쳐버린 후에 새로운 공이 발사되는 방향 등은 랜덤하게 설정됩니다. 상태와 행동 그리고 보상들을 통해 마르코프 의사결정 Process가 결정됩니다. 이러한 Process 중 하나의 Episode(예를 들면, 게임의 한 턴)가 유한한 상태와 행동 그리고 보상의 시퀀스를 형성하게 됩니다.
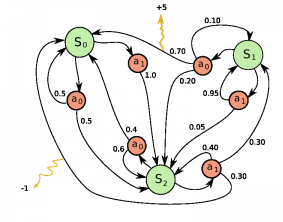
예를 들어 위와 같은 의사결정 모델이 있다고 할 때, 가능한 에피소드들은 아래와 같이 표현할 수 있습니다. $$s_0, a_0, r_1, s_1, a_1, r_2, ... s_{n-1}, a_{n-1}, r_n, s_n$$
2. Discounted Future Reward란?
[ Discounted Future Reward ]
오랜 시간동안 좋은 수행능력이 나오기 위해서는 당장의 Reward를 포함하여 미래에도 좋은 Reward를 받아야 합니다.
마르코프 과정이 한번 실행된 것을 보면, 한 에피소드의 Reward 합계를 쉽게 계산할 수 있습니다. 그리고 특정 시점에서 얻는 미래의 총 리워드는 아래의 식으로 표현할 수 있습니다. $$R_t = \sum_{t`=t}^{T}r^{t`-t}{r_{t^{`}}}$$
그러나 환경은 확률적이기 때문에, 같은 리워드를 받아서 다음 번에 같은 행동을 수행할 수 있다고 확신할 수 없습니다. 오히려 미래로 가면 갈수록 더욱 케이스가 나뉘어 지게 되고 가치가 떨어지게 되는데, 이를 위해 Reward Factor를 사용하여 미래의 리워드를 차감시킵니다. 일반적으로 Reward Factor는 0~1사이의 변수인데, 지수승을 사용하므로 미래로 갈수록 리워드의 가치가 줄어듭니다. 만약 차감변수를 0에 가깝게 둔다면 우리는 근시안적 보상을 목표로, 당장의 점수를 높게 획득하는 것에 초점을 둡니다. 만약 우리가 현재의 점수와 미래의 점수 사이의 균형을 맞추기를 원한다면 0.9정도의 값으로 설정해야 합니다. 하지만 만약 우리의 환경이 변하지 않으며, 같은 행동으로 동일한 보상이 발생한다면 그 값을 1로 설정하면 됩니다.
3. Bellman Equation(벨만 방정식)이란?
[ Bellman Equation ]
가치함수는 어떤 상태의 가치에 대한 기대값을 나타냅니다. 어떤 상태의 가치함수는 에이전트가 그 상태로 갈 경우에 앞으로 받을 보상의 합에 대한 기댓값입니다. 가치함수는 현재 Agent의 정책에 영향을 받는데, 이 정책을 반영한 식이 벨만 방정식입니다. 이러한 벨만 방정식은 강화학습에서 상당히 중요합니다. 기댓값을 알아내기 위해서는 앞으로 받을 모든 보상에 대해 고려를 해야하지만 물리적으로는 불가능합니다. 따라서 이를 컴퓨터가 계산하기 위해서는 다른 방법을 사용합니다. 한 번에 모든 것을 계산하는 것이 아니라 값을 변수에 저장하고 루프를 도는 계산을 통해 참 값을 알아가는 것입니다.
참고 자료
'인공지능' 카테고리의 다른 글
| [논문번역] Playing Atari with Deep Reinforcement Learning 논문 설명/요약 (2) | 2020.02.10 |
|---|---|
| E-Greedy Algorithm(입실론 그리디 알고리즘)이란? (4) | 2020.02.10 |
| Experience Replay Memory란? (0) | 2020.02.09 |
| Stochastic Gradient Descent(SGD)란? (0) | 2020.02.09 |
| Q-Learning이란? (2) | 2020.02.09 |
