
티스토리 뷰
[Server] COW(CopyOnWrite) 기법과 이를 활용하는 자바와 레디스의 예시들(COW on Java and Redis)
망나니개발자 2025. 6. 10. 10:00
1. COW(CopyOnWrite) 기법과 이를 활용하는 자바와 레디스의 예시들
(COW on Java and Redis)
[ COW(CopyOnWrite) 기법이란? ]
Copy-on-write(CoW, 복사 시 쓰기)는 컴퓨터 프로그래밍과 운영체제에서 데이터 복사를 최적화하기 위해 사용되는 전략이다. COW 방식은 데이터를 복사할 때 전체 데이터를 즉시 복제하는 대신, 기존 데이터에 대한 새로운 참조만 생성해두고, 원본이나 복사본 중 어느 하나가 데이터를 수정하려고 할 때 실제 복사를 진행한다.
예를 들어 부모 프로세스 A가 존재하는 상황에서 fork() 메서드를 통해 자식 프로세스 B를 생성했다고 하자. 이때 두 프로세스가 공유하는 페이지들이 다음과 같이 존재할 수 있다.

COW 기법은 두 프로세스가 동일한 참조를 가리키는 페이지에 대한 변경이 없을 경우에는 동일한 참조를 유지한다. 하지만 그러다가 어떤 프로세스가 변경을 원한다면, 기존 페이지를 복제하여 복제된 페이지에 대해 변경을 진행하게 되는 것이다.

이러한 방식은 리소스 사용을 최소화하고, 특히 대용량 데이터셋을 다룰 때 효율성을 크게 높일 수 있어서 다양한 곳에서 활용되고 있다.
[ 자바의 CopyOnWriteArrayList ]
자바에서는 ArrayList 클래스에 COW 기법을 적용하여 스레드 안전(thread-safe)하게 요소들을 다룰 수 있는 CopyOnWriteArrayList를 제공한다. CopyOnWriteArrayList에서 데이터를 추가하게 되면 다음과 같이 동기화가 걸린 상태로 내부 배열이 복사되어, 복사된 배열에 변경이 진행되는 것을 확인할 수 있다.

이것은 리스트를 변경하는 모든 작업이 리스트를 뒷받침하는 배열의 새로운 사본을 생성한다는 것을 의미하며, 반복자(iterator)를 통한 작업 수행 시에 변경이 발생하여도 ConcurrentModificationException이 발생하지 않는다는 것을 보장한다.
하지만 반복자를 생성하는 경우에도 COWIterator로 내부적으로 배열이 복사된 형태로 반복자가 실행된다.

따라서 반복자가 생성된 이후 목록에 대한 추가, 제거, 변경 사항은 반복자의 실행에 영향을 주지 않는다. 예를 들어 다음과 같이 반복자를 통해 반복을 하는 경우에 원소가 추가된 경우, 출력은 반복자의 생성되는 시점에 요소들만을 대상으로 한다는 것이다.
@Test
void cowIterator() {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("One");
list.add("Two");
for (String s : list) {
list.add("Three"); // 허용됨. ConcurrentModificationException 없음.
System.out.println(s);
}
}
// 출력 결과
// One
// Two
해당 구현은 일반적으로 사용하기에는 비용이 너무 크다. 내부적으로 변경 수행 시마다 배열의 복제가 일어날 뿐만 아니라, 배열 복제를 위해 synchronized 블록 내부에서 자체 lock 객체를 통한 잠금이 일어난다는 점 그리고 배열의 volatile 키워드에 의해 CPU 캐싱을 활용할 수 없다는 등의 성능적 한계가 존재한다.

COWIterator는 ListIterator를 구현하므로 인터페이스 계약에 따라 리스트를 변경하는 메서드를 지원해야 하지만, 단순성을 위해 리스트를 변경하는 메서드는 모두 UnsupportedOperationException을 던진다.
공유 데이터에 대한 CopyOnWriteArrayList의 접근 방식은 완벽한 동기화보다 빠르고 일관된 데이터 스냅숏(읽기마다 다를 수 있음)이 더 중요할 때 유용할 수 있다. 이는 미션이 크리티컬하지 않은 데이터와 관련된 시나리오에서 상당히 자주 볼 수 있으며, 복사후 쓰기 방식은 동기화와 관련된 성능 저하를 방지한다.
하지만 그럼에도 불구하고 CopyOnWriteArrayList는 순회 작업(traversal operation)이 변경 작업보다 훨씬 많을 때 그리고 프로그래머가 동기화의 번거로움을 피하고자 하면서도 스레드 간 간섭 가능성을 제거하고자 할 때 좋은 선택일 수 있으므로 알아둘 필요가 있다.
동기화되는 리스트라고 하면 SynchronizedList라는 선택지 역시 떠올릴 수 있다. CopyOnWriteArrayList는 변경 작업마다 배열을 복사하지만, 동기화된 버전은 백업 배열이 가득찬 경우에만 복사한다.
Collections.synchronizedList(new ArrayList<>());
하지만 이는 모든 작업에 대해 동기화(synchronized)되므로 서로 다른 스레드에서의 읽기 작업이 서로 블로킹될 수 있어서 활용하는 데 한계가 있다. COW 데이터 구조에서는 데이터 조회 시에는 이러한 현상이 발생하지 않는다.

[ 레디스의 COW 기반 백업 ]
레디스는 기본적으로 인메모리로 동작하지만, 안전한 데이터 저장을 위해 RDB와 AOF 두 가지의 백업 방식을 지원한다.
- AOF(Append Only File): 레디스 인스턴스가 처리한 모든 쓰기 작업을 차례대로 기록하며, 복원 시에는 파일을 다시 읽어가며 재구성함
- RDB(Redis DataBase): 일정 시점에 메모리에 저장된 데이터 전체를 저장함(snapshot 방식)
레디스는 요청 처리를 싱글 스레드로 수행하기 때문에 위와 같은 파일 쓰기 작업을 foreground 방식으로 메인 스레드가 처리하면 성능 병목 지점이 될 수 있다. 따라서 레디스는 디스크에 파일을 저장하는 작업을 수행할 때 fork()를 이용해 백그라운드 자식 프로세스를 만들어 처리하는데, 이때 COW 메커니즘이 동작한다.
부모 프로세스와 자식 프로세스가 동일한 메모리 페이지를 공유하는 상태에서 자식 프로세스는 백업을 진행한다. 그러다가 부모 프로세스가 클라이언트의 요청을 받아 변경 작업을 수행할 때 메모리 페이지를 복사하게 된다.
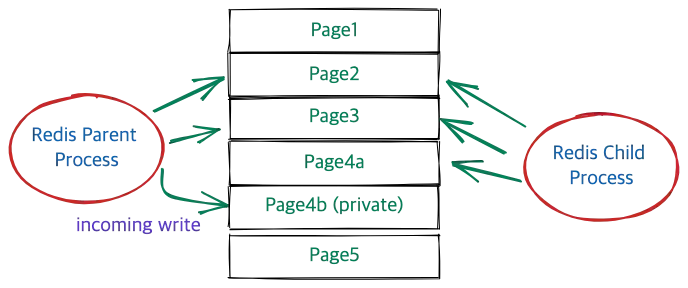
참고로 이때 페이지 복사로 인해 레디스의 메모리 사용량이 급증하여 순간적으로 메모리를 초과 할당해야 하는 상황이 생길 수 있다. 따라서 레디스 인스턴스의 maxmemory 값은 실제 서버 메모리보다 여유를 갖고 설정하고 vm.overcommit_memory를 1로 할 것을 권장하기도 한다.
참고 자료
- 자바 병렬 프로그래밍
- 개발자를 위한 레디스
'Server' 카테고리의 다른 글
| [Gradle] 그레이들 의존성 분석을 통해 NoClassDefFoundError, NoSuchFieldError 오류 해결하기 (3) | 2025.07.08 |
|---|---|
| [Kafka] 올바른 카프카 컨슈머(KafkaConsumer) 설정 가이드와 내부 동작 분석 (8) | 2025.06.24 |
| [Server] Logback AsyncAppender의 동작 방식과 neverBlock 설정의 필요성 (0) | 2025.05.27 |
| [Server] K6 부하 테스트 시나리오 작성하고 결과 지표 분석하기(K6 Load Testing) (2) | 2025.04.01 |
| [LLM] MCP(Model Context Protocol)에 대하여 알아보고 IntelliJ와 Claude를 MCP로 연동하기 (11) | 2025.03.25 |
