

티스토리 뷰
1. Apache Spark의 개념과 등장 배경
[ Apache Spark의 등장 배경 ]
Spark는 MapReduce 형태의 클러스터 컴퓨팅 패러다임의 한계를 극복하고자 등장하게 되었다. MapReduce는 Disk로부터 데이터를 읽은 후, Map을 통해 흩어져 있는 데이터를 Key-Value 형태로 연관성 있는 데이터끼리 묶은 후에, Reduce를 하여 중복된 데이터를 제거하고, 원하는 데이터로 가공하여 다시 Disk에 저장한다. 하지만 이러한 파일 기반의 Disk I/O는 성능이 좋지 못했고, In-memory의 연산을 통해 처리 성능을 향상시키고자 Spark가 등장하게 되었다.
[ Apache Spark란? ]
Apache Spark는 오픈소스이며, 범용적인 목적을 지닌 분산 클러스터 컴퓨팅 프레임워크으로 Fault Tolerance & Data Parallelism을 가지고 클러스터들을 프로그래밍할 수 있게 도와준다. Apache Spark에서는 RDD, Data Frame, Data Set의 3가지 API를 제공하는데, 이러한 데이터를 바탕으로 In-memory 연산을 가능하도록 하여 디스크 기반의 Hadoop에 비해 성능을 약 100배 정도 끌어올렸다.

Spark는 Cluster들을 관리하는 Cluster Manager와 데이터를 분산 저장하는 Distributed Storage System이 필요하다. 자주 사용되는 Cluster Manager로는 Hadoop의 YARN이나 Apache Mesos 등이 있다. 또한 Distributed Storage System으로는 HDFS(Hadoop Distributed File Syste), MapR-FS(MapR File System), Cassandra, OpenStack Swift, Amazon S3, Kudu, custom solution 등을 적용할 수 있다. 가장 많이 사용되는 Storage System는 Hadoop인데, zlib and Bzip2와 같은 압축 알고리즘을 지원하며, Spark와 같은 머신에서 구동가능하기 때문이다.
2. Spark와 다른 시스템의 결합
[ Spark와 Hadoop의 결합 ]
Spark는 Hadoop을 대체하기 나온 것이 아니라 Hadoop과 함께 하며 성능을 높이고자 나온 것이다. 그래서 모든 Hadoop의 사용자들이 가능한 쉽게 Spark를 사용할 수 있도록 초점을 두어 개발을 하였고, 그에 따라 Hadoop의 버전과 무관하게 그리고 Hadoop 클러스터에 대한 관리자 권한이 있는지와 무관하게 Spark를 실행할 수 있다.
물론 Spark 역시 Stand Alone 형태를 제공하지만, 실제 운영을 위해서는 Hadoop과 주로 결합되는데, 이러한 Spark는 아래와 같은 3가지 형태로 Hadoop과 결합되어 사용될 수 있다.
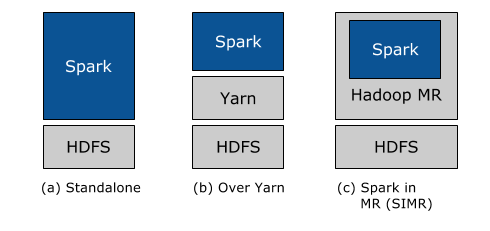
- Standalone Deployment
- Hadoop 클러스터의 모든 시스템 또는 하위 시스템에 Resource를 동적으로 할당하고, Hadoop의 MapReduce와 함께 Spark를 실행할 수 있다.
- 사용자는 HDFS 데이터에서 임의의 Spark 작업을 실행할 수 있다.
- Hadoop Yarn Deployment
- 이미 Hadoop Yarn을 배포했거나 배포하려는 사용자는 사전 설치나 관리 엑세스 없이 Spark를 실행할 수 있다.
- 이를 통해 사용자들은 Spark를 Hadoop에 쉽게 통합시켜 Spark의 기능들을 사용할 수 있다.
- Spark In MapReduce(SIMR)
- Yarn을 아직 실행하지 않은 Hadoop의 사용자는 Standalone 외에 SIMR을 통해 MapReduce 안에서 Spark를 사용할 수 있다.
- SIMR을 사용하면 사용자는 Spark를 실험하고, 다운로드한 후 몇분 내에 쉘을 사용할 수 있으며 진입장벽이 낮아 모두가 Spark를 사용할 수 있게 한다.
[ Spark와 YARN의 결합 ]
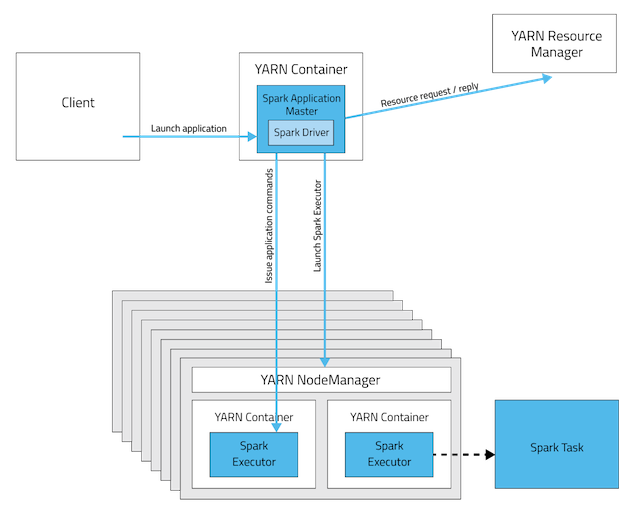
실제로 Task를 구동하는 Spark Executors와 Executors를 스케줄링하는 Spark Driver로 구성된 Spark jobs는 2가지 배치 모드 중 한가지로 실행될 수 있다. 2가지 모드를 잘 이해해야 적당한 메모리 할당량을 설정하고, jobs를 예상한대로 제출할 수 있다. 각각의 모드는 다음과 같다.
1. Cluster Mode(클러스터 모드)
Cluster Mode는 모든 것들은 Cluster에서 구동된다. Job을 Client에서 구동할 수 있으며, Client가 꺼져도 Cluster에서 job은 처리된다. Spark Driver는 YARN Application Master 내부에 캡슐화 되어있다. 오랜 작업시간이 필요한 경우, Cluster Mode를 사용하는 것이 좋다.
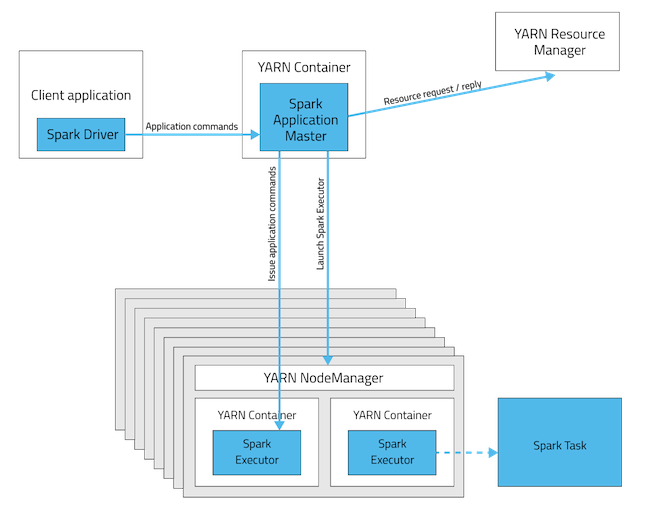
2. Client Mode(클라이언트 모드)
Spark Driver는 Client에서 구동이 된다. 만약 Client가 꺼지면, job은 fail하게 된다. 반면에 Spark Executors는 여전히 Cluster에서 구동되는데, 스케줄링을 위해 Yarn Application Master가 생성된다. Client Mode는 interactive jobs(실시간 쿼리 or 온라인 데이터 분석 등)에 적합하다.
3. Apache Spark의 3가지 API
[ RDD(Resilient Distributed Dataset) ]
Apache Spark 1.x는 RDD를 아키텍처의 기반으로 하는데, RDD란 여러 클러스터에 distributed되어 있으며 fault-tolerant한 방식으로 유지되는 변경불가능한(read-only) 형태의 데이터 모음으로 low-level transformation and control을 원하는 경우에 사용한다. 또한 schema를 포함하지 않아도 무관한 경우에 사용하면 좋다.
아래의 예제는 HDFS에 저장된 로그로부터 ERROR를 추출한 후 HDFS문자열이 포함된 것을 추출하여 time field를 추출하는 예제이다. 아래의 그래프에서 각각의 Box는 RDD를 뜻한다. 각 RDD는 연결되어 있으며, 해당 Box가 실패하는 경우 이전 단계가로 re-processing을 수행하는 lineage graph이다. 이러한 구조는 In-memory computing에서 Fault Tolernace를 보장하기 위함이다.
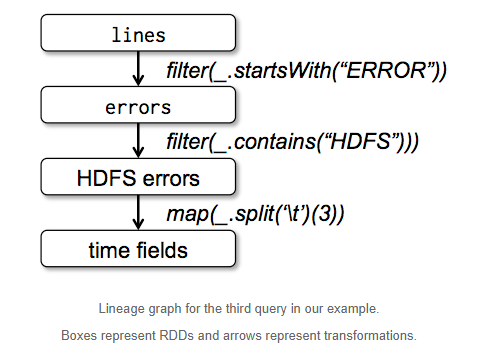
lines = spark.textFile("hdfs://...") // HDFS로부터 로그파일을 읽어 lines란 RDD 생성
errors = lines.filter(_.startWith("Error")) // ERROR로 시작되는 데이터만 필터링하여 RDD 생성
errors.persist() // In-memory에 erros RDD를 persist한다.
errors.count() // errors를 count하는 action을 수행한다.
errors.filter(_.contains("HDFS")) // errors RDD에서 HDFS가 포함된 경우
.map(_.split('\t')(3)) // 3번째 필드가 time이라 가정하고, tab으로 분리하여 3번째 필드를 가져온다.
.collect() // 결과값을 반환한다.
[ Data Frame ]
Spark 1.3.x 부터는 named column으로 구성된 데이터의 분산 집합인 DataFrame이 등장하게 되었다. named column이라는 것은 스키마를 가진 RDD로, 관계형 데이터베이스의 테이블과 비슷하다. Data Frame부터는 Spark 내부에서 최적화를 할 수 있는 기능들이 추가되었다. 또한 기존 RDD에 스키마를 부여하고 질의나 API를 통해 데이터를 쉽게 처리할 수 있다.
[ DataSet ]
Spark 2.0부터는 DataFrame과 DataSet가 Dataset으로 병합되어 데이터 처리를 통합하고 있다. 내부 동작 방식에는 Catalyst Optimizer를 통해 실행 시점에 최적화된 코드를 제공하여, 언어에 무관하게 동일한 성능을 보장한다. 개념적으로 DataFrame은 DataSet[Row]로 간주되며, DataSet의 부분집합으로 불 수 있다.

DataSets는 strongly-typed API와 untyped API라는 2가지의 특성을 모두 사용한다. DataSet[Row] 에서 Row는 Generic이 사용된 Untyped 형태의 JVM 객체이며, DataFrame은 DataSet에서 Row를 기반으로 추출한 데이터들을 의미한다.

이러한 DataSet을 이용하면 다음과 같은 다양한 장점들을 누릴 수 있다.
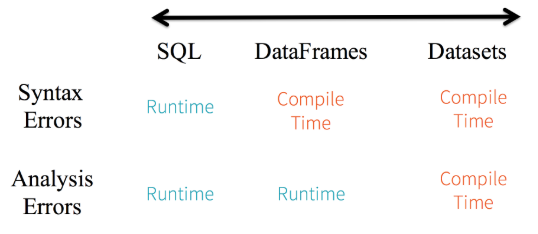
1. Static-typing and runtime type-safety
Spark SQL을 통해 작성한 쿼리문의 경우에는 실행 전까지 syntax error를 잡아낼 수 없지만, Data Frame이나 DataSet을 사용하는 경우에는 complie-time에 이를 잡아낼 수 있다. 만약 우리가 DataFrame 또는 DataSet API의 일부가 아닌 함수를 호출한 경우에 컴파일 시점에 에러가 발생하만, 존재하지 않는 column name을 호출하는 것은 runtime 이전까지 감지할 수 없다.
또한 DataSet API는 모두 lambda 함수와 JVM 형태의 객체로 표현되기 때문에 지정된 매개변수가 불일치한 경우, 컴파일 시점에 잘못된 JVM Typed Object를 잡아낼 수 있으며 Analysis Error역시 발견될 수 있다. 이러한 DataSet의 경우 개발자에게는 제약이 많지만 생산성이 높다.
2. High-level abstraction and custom view into structured and semi-structured data
Datasets[Row]의 집합인 Dataset은 구조화된 custom view를 반구조화된 데이터 형태로 보여준다. 예를 들어, Json 형태의 경우 스키마를 포함하고 있어서, DataFrame으로 스키마 정보가 Binding된다. 아래와 같은 Iot deive의 event에 대한 json 형태의 dataset이 있다고 할 때, 이를 DeviceIotData라는 Custom-Object로 만들 수 있다.
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL",
"cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius",
"temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408, "lcd": "red", "timestamp" :1458081226051}case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)// read the json file and create the dataset from the case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read.json(“/databricks-public-datasets/data/iot/iot_devices.json”).as[DeviceIoTData]
3. Ease-of-use of APIs with Structure
Dataset은 높은 수준의 API로 사용가능하며, Dataset의 유형 객체에 직접 엑세스하여 agg, select, sum, avg, map, filter, groupby 등의 작업을 수행할 수 있다.
// Use filter(), map(), groupBy() country, and compute avg()
// for temperatures and humidity. This operation results in
// another immutable Dataset. The query is simpler to read, and expressive
val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)
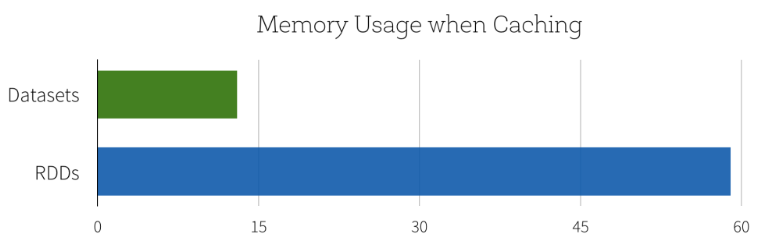
4. Performance and Optimization
DataSet API를 사용하는 모든 이점중에서도 Performance 와 Space Efficiency를 고려하지 않을 수 없다. Dataset도 DataFrame과 마찬가지로 Spark SQL Engine위에서 만들어졌는데, Catalyst Optimizer를 통해 실행 시점에 코드 최적화를 하여 성능을 향상시켜준다.
참고 자료
- https://en.wikipedia.org/wiki/Apache_Spark
- https://data-flair.training/blogs/apache-storm-vs-spark-streaming/
- https://www.popit.kr/spark2-0-new-features1-dataset/
- https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
- https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
- https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
'나의 공부방' 카테고리의 다른 글
| [개발서적] 클린 코드(Clean Code) 핵심 요약 및 정리 (10) | 2021.03.05 |
|---|---|
| [Hadoop] Hadoop의 구조와 MapReduce (0) | 2021.02.03 |
| [Hadoop] YARN의 구조와 동작 방식 (6) | 2021.02.02 |
| [Frontend] VueJS 프로젝트 생성 및 설정하기 (0) | 2021.02.01 |
| [Android] 안드로이드 프로그래밍 핵심 기술(MVVM 패턴과 RxJava) (0) | 2021.02.01 |
