

티스토리 뷰
개발을 하다 보면 함수의 파라미터로 변수를 넘겨주어야 한다. 각 언어마다 변수를 넘겨주는 방법(Pass By Value, Pass By Reference)이 다른데, 이를 정확히 인지하지 못하면 예상치 못한 버그를 발생시킬 수 있다. 이번에는 Java가 어떠한 방식으로 파라미터를 전달하는지 살펴보도록 하자.
1. 메모리 할당에 대한 이해
어떠한 변수를 선언한다는 것은 메모리를 할당한다는 것을 의미한다. 변수를 선언하기 위해 할당되는 메모리로는 크게 스택과 힙이 있다. 스택 영역에는 함수의 호출과 함께 지역 변수 또는 매개변수 등이 할당되며 정렬된 방식으로 메모리가 할당되고 해제된다. 반면에 힙 영역에는 클래스 변수(또는 인스턴스 변수) 또는 객체 등이 할당되며, 우연하고 무질서하게 메모리가 할당된다. (그래서 JVM은 무질서하게 관리되는 힙 영역을 위주로 가비지 컬렉터를 통해 메모리의 해제를 관리한다.)
이러한 기초 지식을 바탕으로 지역에 존재하는 원시 변수와 객체의 메모리 할당을 먼저 살펴보도록 하자.
(인스턴스 변수로 존재하는 원시변수는 힙 영역에서 관리됩니다. 아래의 설명에서는 지역에 존재하는 원시 변수인 Local Primitive Value를 기준으로 설명하고 있습니다.)
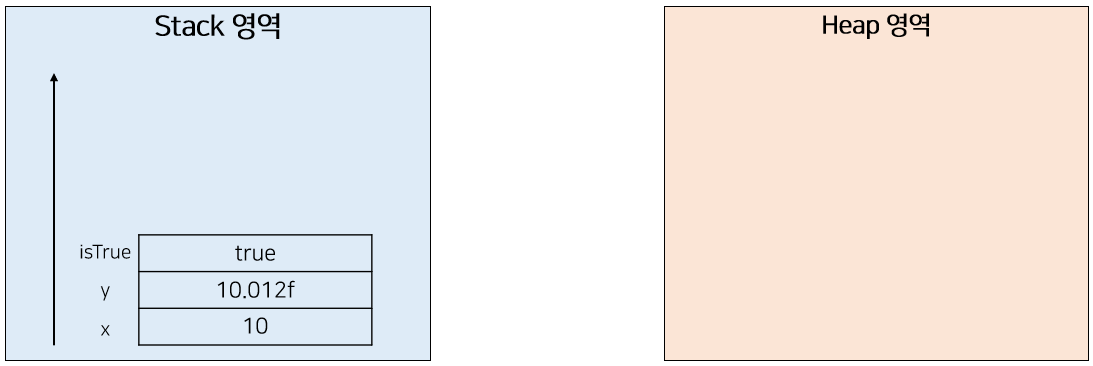
[ 원시 변수(Primitive Value)의 메모리 할당 ]
Java에서 변수는 객체가 아닌 실제 값들인 int, double, float boolean 등과 같은 원시 값(Primitive Value)들이 존재한다. 예를 들어 다음과 같이 함수 내에서 지역 변수로 원시 변수들을 선언하였다고 가정하자.
public void test() {
// Primitive Value
int x = 3;
float y = 10.012f;
boolean isTrue = true;
}
그렇다면 메모리에서는 해당 내용이 다음과 같이 스택 영역에 할당된다. Stack 영역에 실제 값들이 저장되는 것이다.
[ 객체(Object)의 메모리 할당 ]
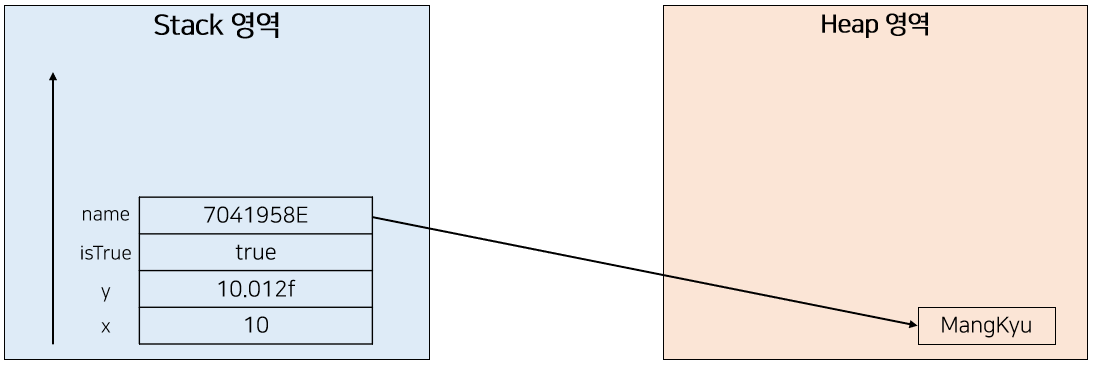
원시변수는 스택 영역에 실제 값들이 할당되었다. 하지만 객체는 원시변수와 다르게 값이 할당된다. 예를 들어 다음과 같은 String 객체를 추가로 생성하였다고 하자.
public void test() {
// Primitive Value
int x = 3;
float y = 101.012f;
boolean isTrue = true;
// Object
String name = "MangKyu";
}
그렇다면 메모리에 값은 다음과 같이 할당된다. 먼저 객체의 경우 Heap 영역에 실제 값이 할당된다. 그리고 이에 접근하기 위해 Stack 영역에는 Heap 영역에 존재하는 값의 실제 주소가 저장되고, C/C++에서는 이를 포인터(pointer)라고 부른다. 즉, Stack 영역에는 실제 값이 존재하는 Heap 영역의 주소가 저장된다는 것이다.
여기에 더해 다음과 같이 크기가 3인 String 배열을 추가적으로 선언하였다고 하자.
public void test() {
// Primitive Value
int x = 3;
float y = 101.012f;
boolean isTrue = true;
// Object
String name = "MangKyu";
String[] names = new String[3];
names[0] = "I";
names[1] = "am";
names[2] = new String("MangKyu");
}
여기에 더해 다음과 같이 크기가 3인 String 배열을 추가적으로 선언하였다고 하자. 배열도 객체이기 때문에 다음과 같이 메모리가 할당되게 된다.
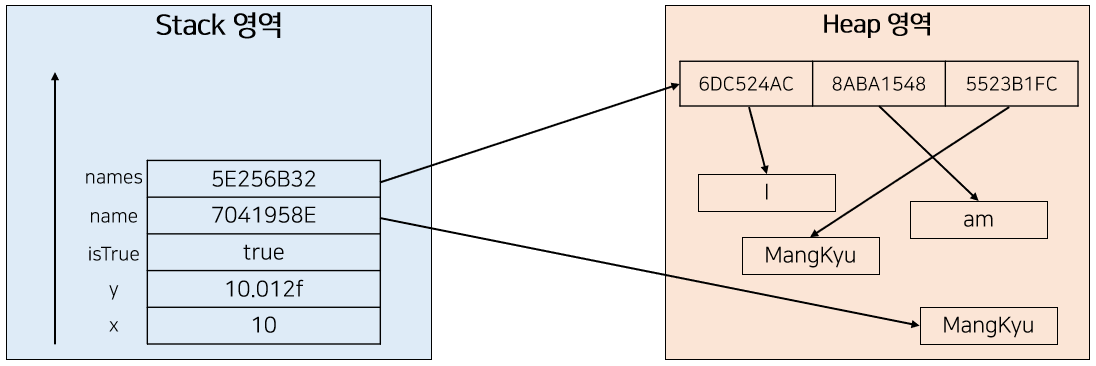
여기서 주목해야 할 것은 크게 세가지가 있다. 먼저 앞서 설명한대로 Heap 영역은 Stack 영역과 다르게 무질서하게 메모리 공간을 활용한다는 것이다. 또한 두 번째로 객체의 메모리 할당인 경우 Stack 영역에 실제 값을 참조하기 위한 Reference(참조값)이 저장되고 이를 통해 참조하여 실제 값에 접근한다는 것이다. 세번째로는 배열의 경우 또 그 배열의 인덱스마다 참조값이 할당되며 이를 통해 접근한다는 것이다.
2. 문제 파헤쳐보며 Pass By Value 이해하기
위에서 설명한 내용을 바탕으로 1장에서 풀었던 문제를 풀이해보자.
[ 문제 ]
class Dog {
private String name;
public Dog (String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public class Main {
public static void main(String[] args) {
int x = 10;
int[] y = {2, 3, 4};
Dog dog1 = new Dog("강아지1");
Dog dog2 = new Dog("강아지2");
// 함수 실행
foo(x, y, dog1, dog2);
// 어떤 결과가 출력될 것 같은지 혹은 값이 어떻게 변할지 예상해보세요!
System.out.println("x = " + x);
System.out.println("y = " + y[0]);
System.out.println("dog1.name = " + dog1.getName());
System.out.println("dog2.name = " + dog2.getName());
}
public static void foo(int x, int[] y, Dog dog1, Dog dog2) {
x++;
y[0]++;
dog1 = new Dog("이름 바뀐 강아지1");
dog2.setName("이름 바뀐 강아지2");
}
}
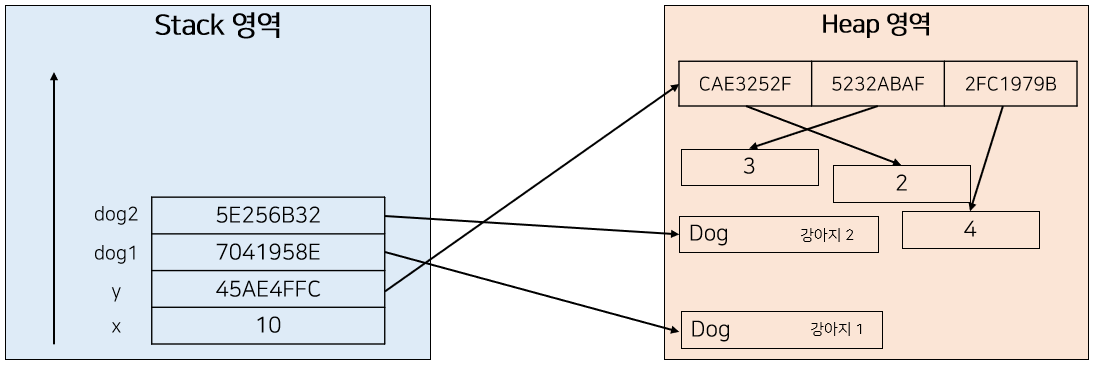
[ 변수의 할당 ]
우선 위의 문제에서는 4가지 변수를 할당해주고 있고, 이를 그림으로 표현하면 다음과 같다.
여기까지 이해를 하였으면 이제 foo 함수의 호출을 진행하여보자.
[ foo 호출 및 실행 - int x ]
foo() 함수는 먼저 int x를 첫 번째 파라미터로 받고 있고, 해당 값을 1 증가시키고 있다. 이 경우 Pass By Value는 다음과 같이 동작하게 된다.
먼저 Stack 영역에 파라미터가 할당된다. 즉, 새로운 x가 Stack에 10의 값으로 생성되는 것이다. 그리고 foo는 x의 값을 증가시키고 있는데, 기존의 x가 아닌 새로운 x값을 증가시키고 있다. 그렇기 때문에 기존의 x는 10으로 값이 유지되고, 새로운 x가 10이 할당된 후에 11로 증가되는 것이다.
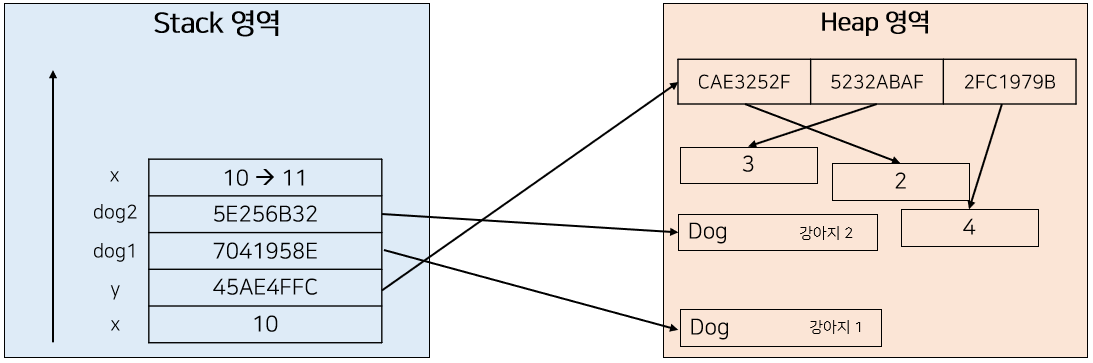
그리고 foo가 종료되면 새로운 x는 Stack영역에서 해제된다. 그렇기 때문에 foo를 호출한 후에 x를 출력하면 기존의 x가 출력되는 것이다.
[ foo 호출 및 실행 - int[] y ]
foo() 함수는 두 번째 파라미터로 int형 배열 y를 받고 있다. Pass By Value로 동작하는 Java는 역시 Stack에 새로운 파라미터인 int[] y를 할당할 것이다. 이를 그림으로 표현하면 다음과 같다.

그리고 y의 0번째 인덱스에 존재하는 값을 1 증가시키고 있는데, 앞선 x와는 상황이 다르다. 그러한 이유는 새로운 y가 할당되긴 하였지만 배열의 주소를 가리키고 있기 때문이다. 해당 y가 기존의 y이든 새로운 y이든 실제 배열의 주소로 접근하여 값을 1 증가시키고 있기 때문에 foo가 종료된 후에도 배열의 값은 변화하게 된다.
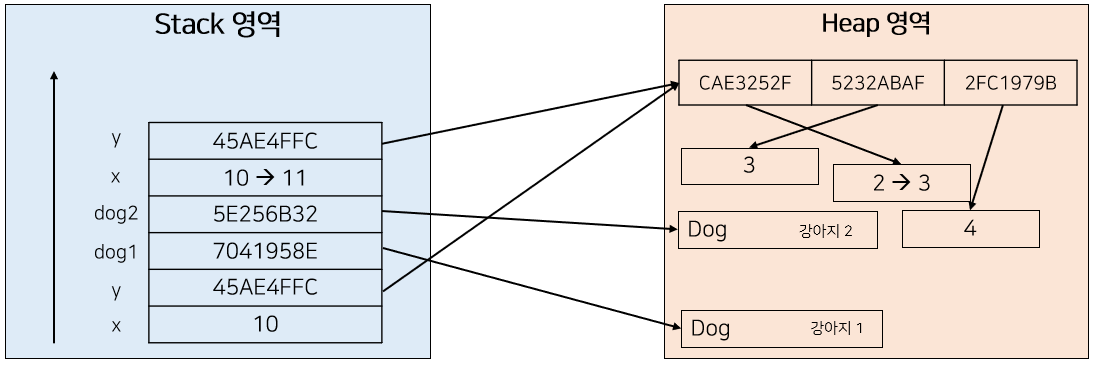
[ foo 호출 및 실행 - Dog dog1 ]
foo() 함수는 세 번째 파라미터로 Dog 클래스의 인스턴스인 dog1을 받고 있다. Pass By Value로 동작하는 Java는 역시 Stack에 새로운 파라미터인 dog1을 생성하게 되고, y와 마찬가지로 dog1은 객체이기 때문에 dog1의 주소를 값으로 갖게 된다.
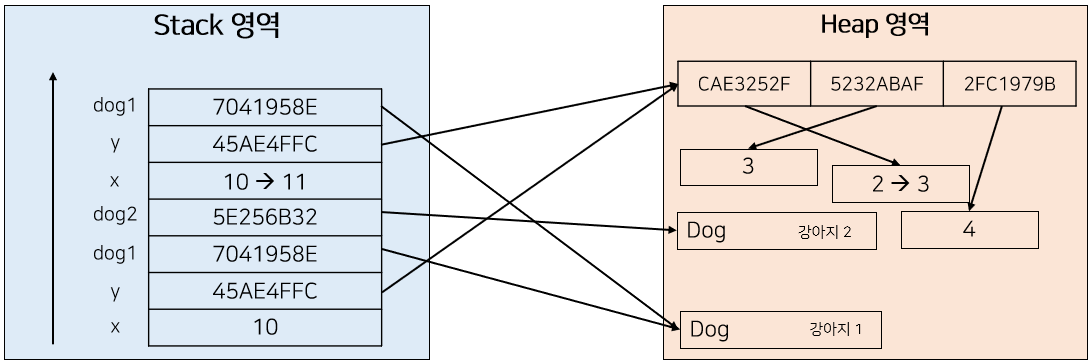
그리고 foo 함수에서 진행하는 연산을 살펴보자. foo 함수는 dog1을 새로 생성하고 있다. 그렇기 때문에 Heap 영역에는 새로운 dog1이 생성될 것이고, Stack에서 가리키는 주소값은 새로운 dog1을 가리키게 될 것이다.

마찬가지로 foo 함수가 종료되면 새로운 dog1은 소멸되고 기존의 dog1에는 변화가 없다.
[ foo 호출 및 실행 - Dog dog2 ]
마지막으로 foo() 함수는 네 번째 파라미터로 Dog 클래스의 인스턴스인 dog2를 받고 있다. dog1때와 마찬가지로 Stack 영역에는 새로운 dog2가 할당되고, 실제 dog2의 주소값을 가리키고 있다.
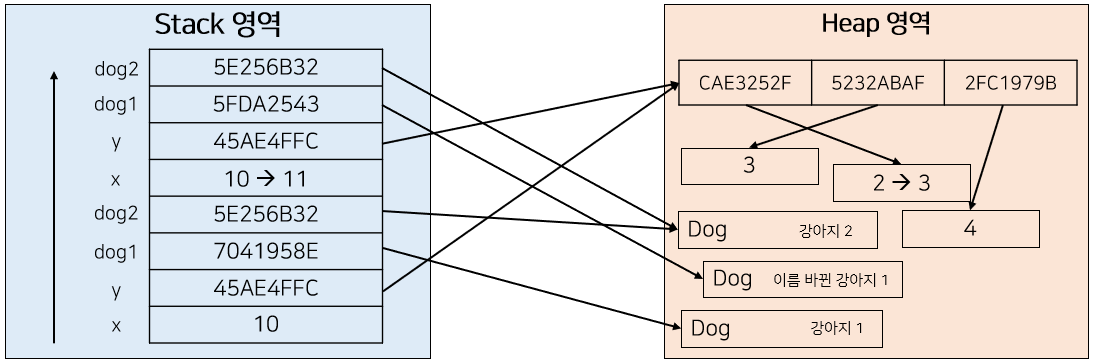
하지만 dog2가 수행하는 연산은 dog1과 다르다. dog2는 새로운 값을 할당하는 것이 아니라, 주소값을 통해 Heap 영역에 존재하는 객체에 접근하여 set을 통해 값을 변화시켜주고 있다.
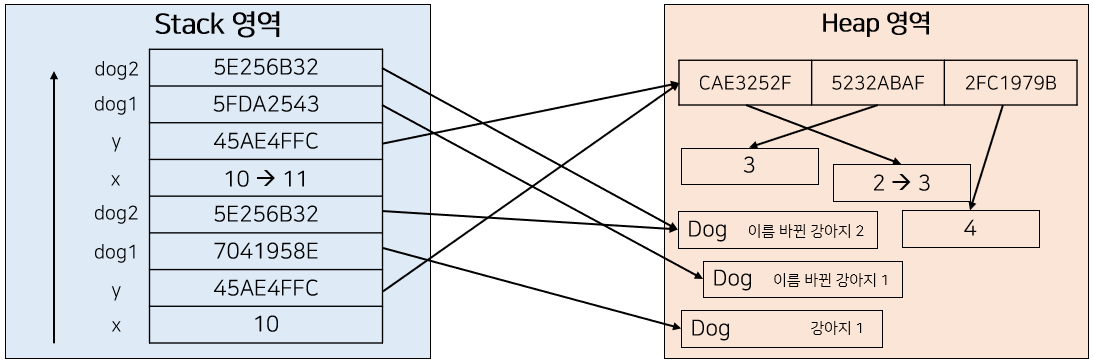
foo() 함수가 종료되면 어떻게 될 것인가? Stack 영역에 할당된 새로운 dog2는 소멸될 것이다. 하지만 Heap 영역에 존재하는 값은 변하였기 때문에 foo 함수가 종료된 후에 dog2의 name을 출력해보면 "이름 바뀐 강아지2"가 출력되는 것이다.
[ foo 종료 ]
foo 함수가 종료되면 foo 함수에서 사용했던 파라미터들은 모두 사라지고 다음과 같은 값들만 남게 된다.
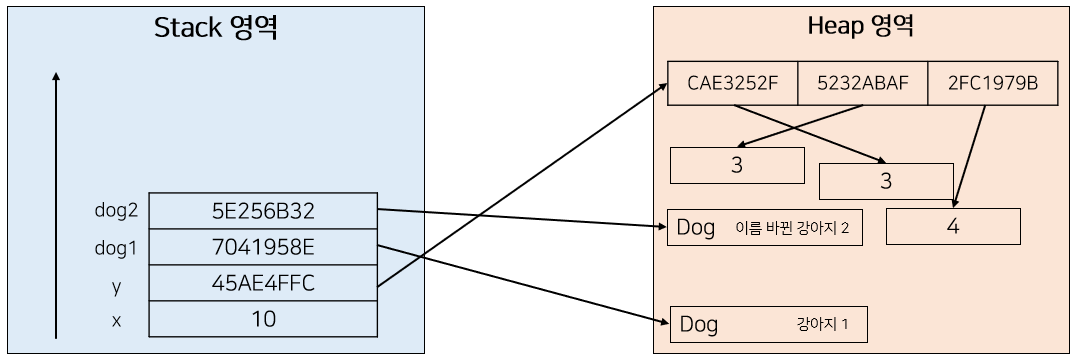
이러한 결과를 바탕으로 출력 결과를 예상하면 다음과 같다.
x = 10
y = 3
dog1.name = 강아지1
dog2.name = 이름 바뀐 강아지2
이러한 동작 방식과 결과를 갖게 되는 이유는 Java가 Pass By Value(또는 Call By Value)로 동작하기 때문이다. 다음 장에서는 Pass By Value와 Pass By Reference를 Call Stack을 통해 자세히 이해해보도록 하자.
관련 포스팅
- Pass By Value 실행 결과 예측해보기 (1/3)
- 메모리 관리 및 Pass By Value의 동작 방식 (2/3)
- Pass By Value와 Pass By Reference의 차이 및 이해 (3/3)
'Java & Kotlin' 카테고리의 다른 글
| [Java] Stream API에 대한 이해 - (1/5) (14) | 2021.01.22 |
|---|---|
| [Java] Pass By Value와 Pass By Reference의 차이 및 이해 (3/3) (14) | 2021.01.18 |
| [Java] Pass By Value 실행 결과 예측해보기 (1/3) (2) | 2021.01.18 |
| [Java] equals와 hashCode 함수 (21) | 2020.10.29 |
| [Java] Lombok이란? 및 Lombok 활용법 (24) | 2020.06.10 |
